Download to read offline





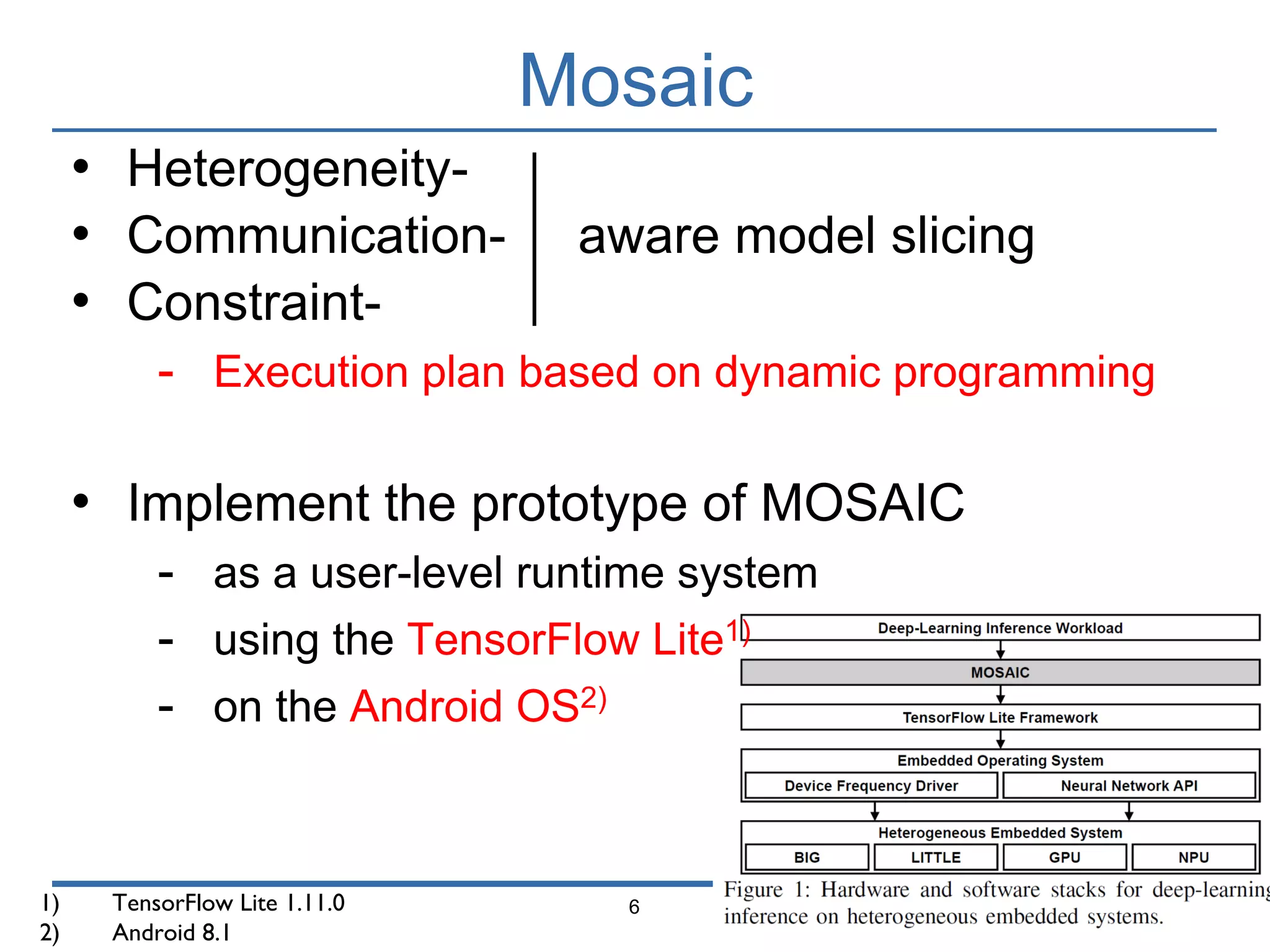
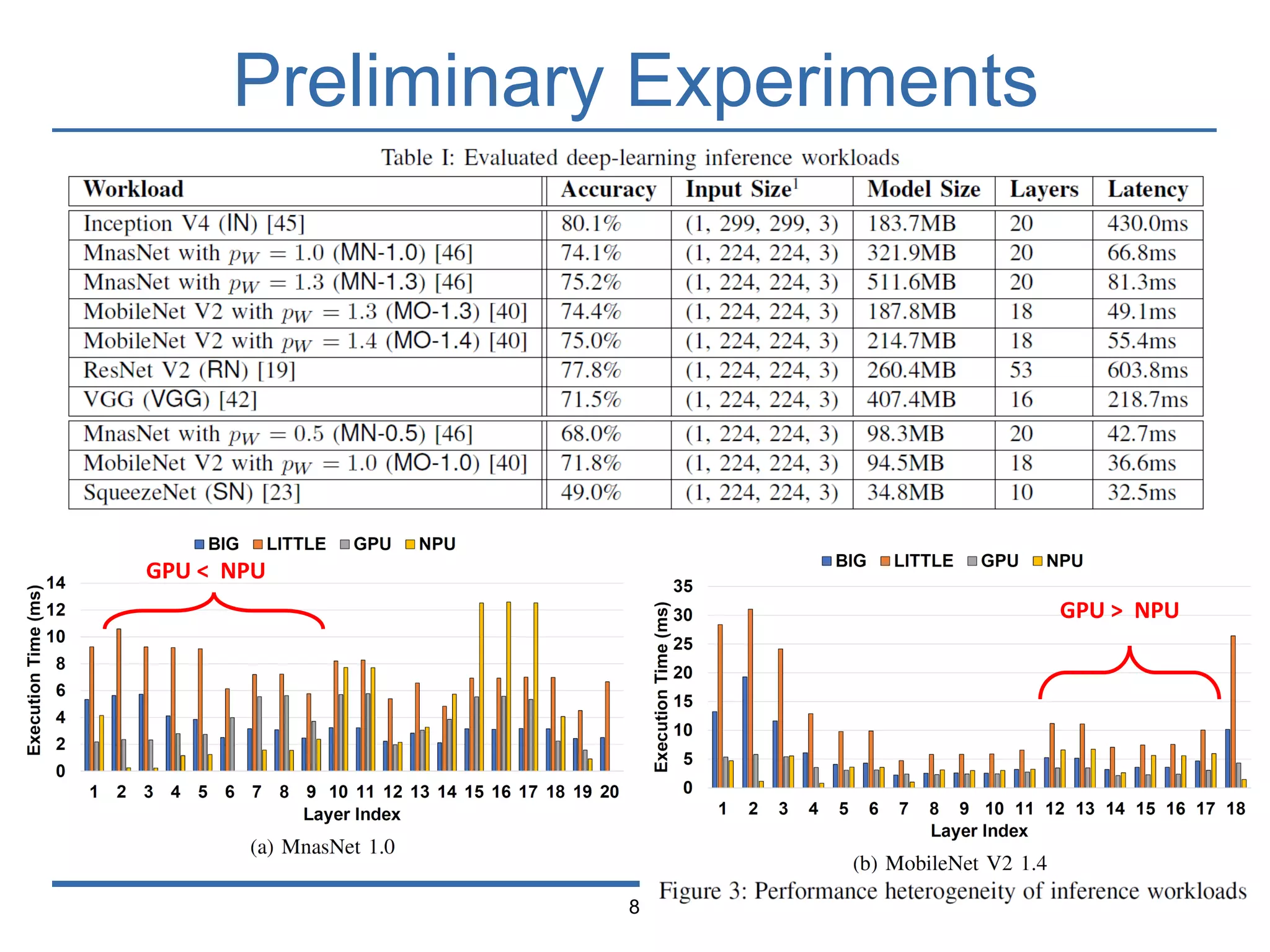
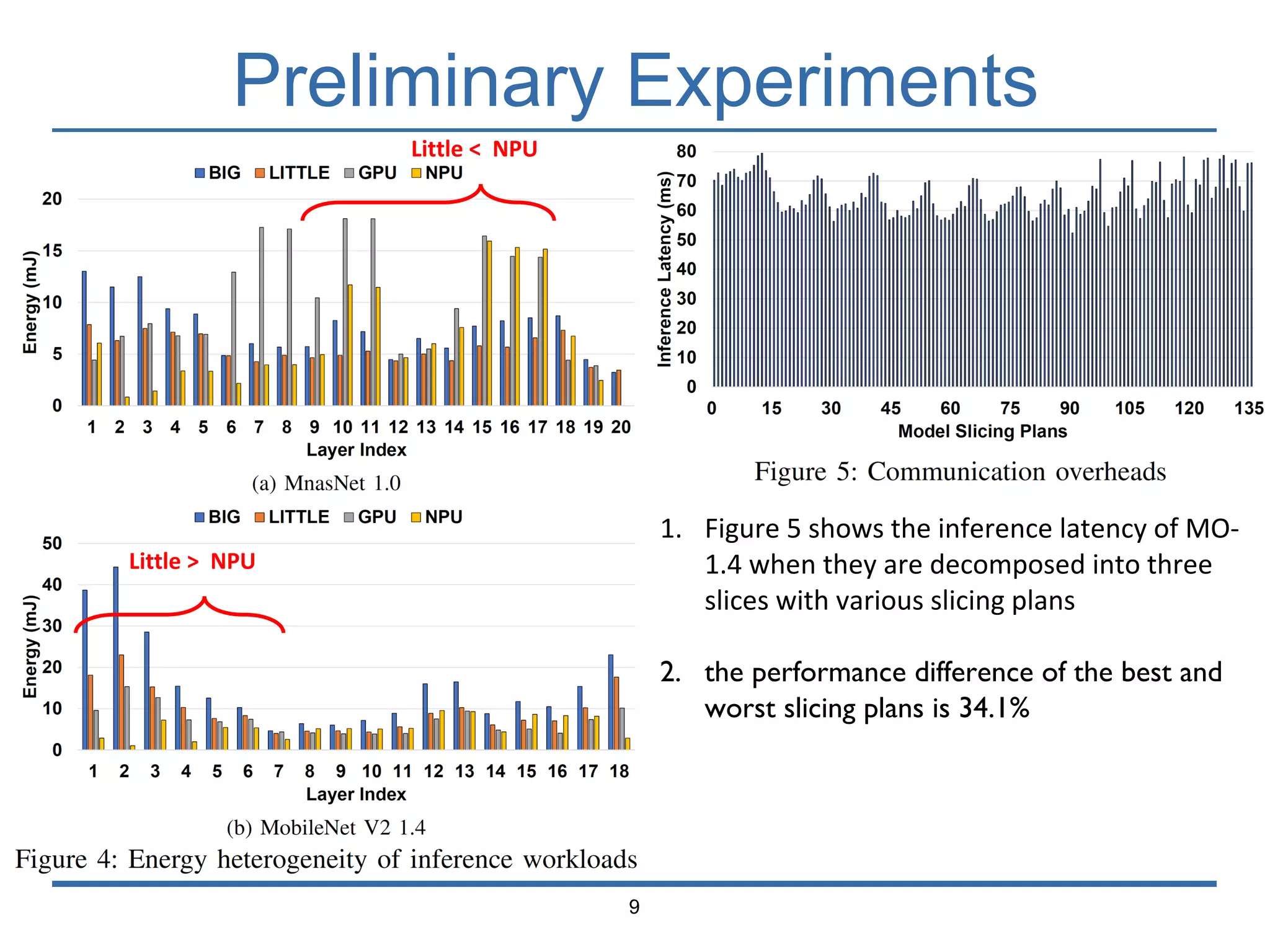
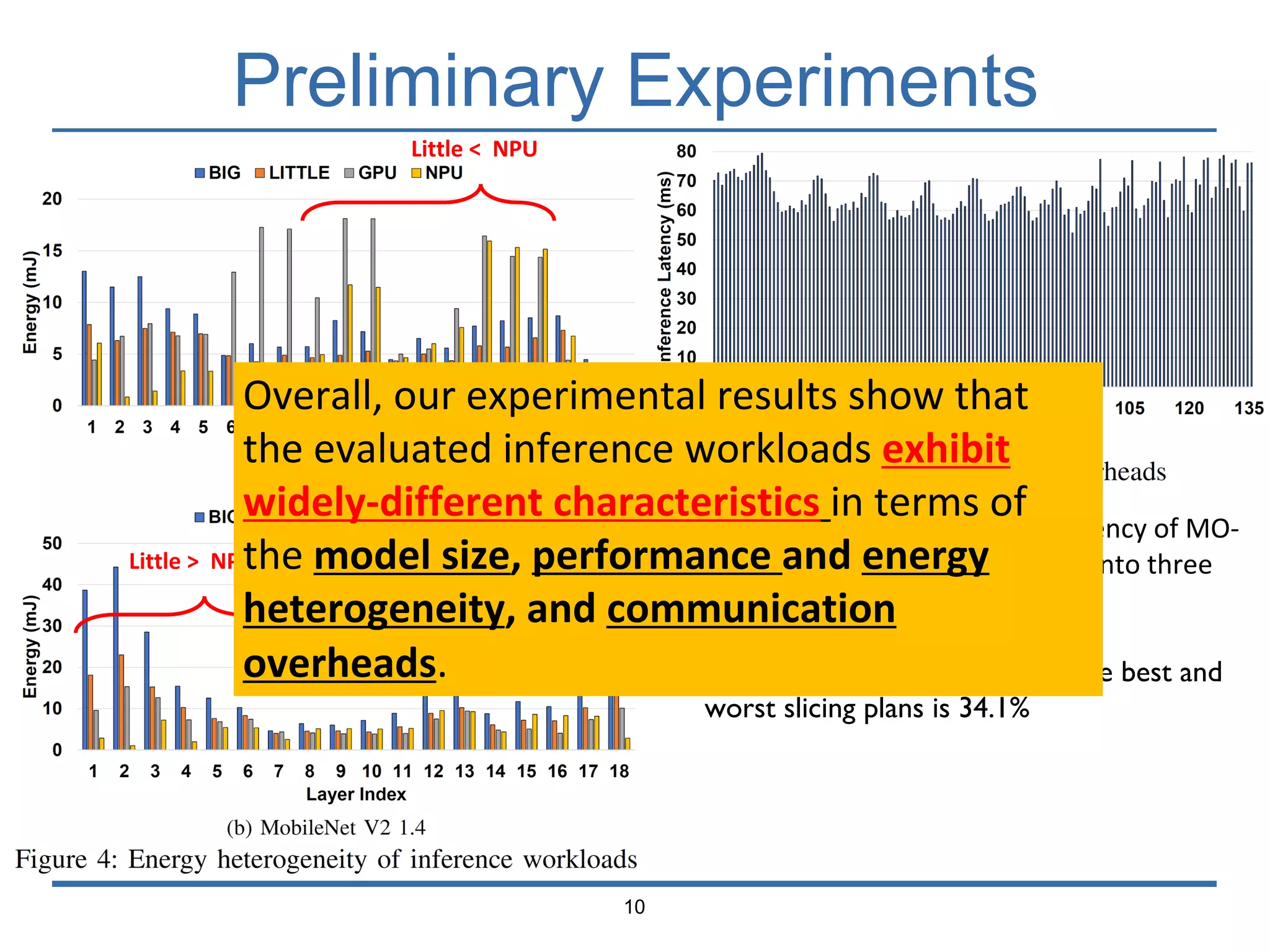

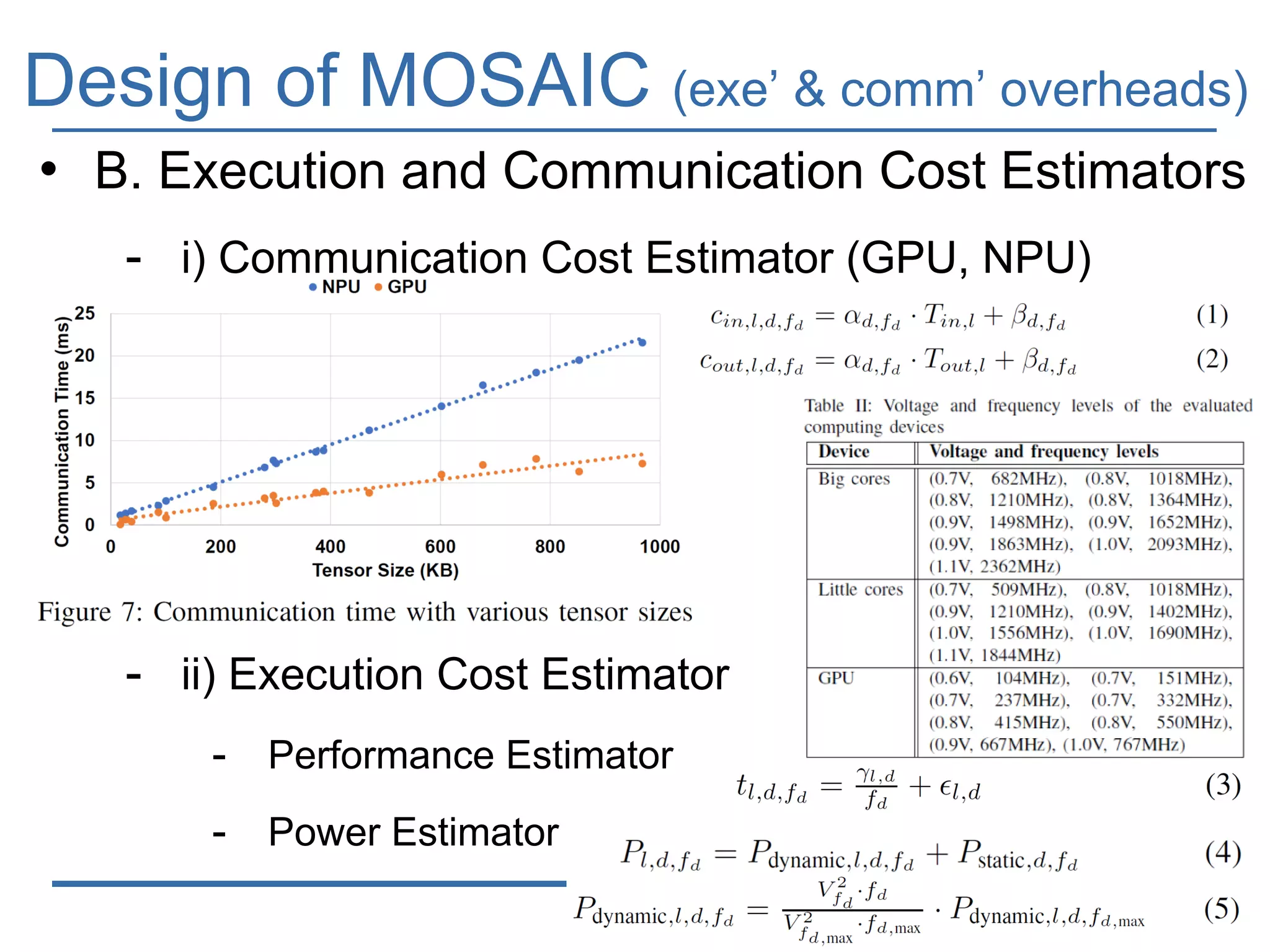


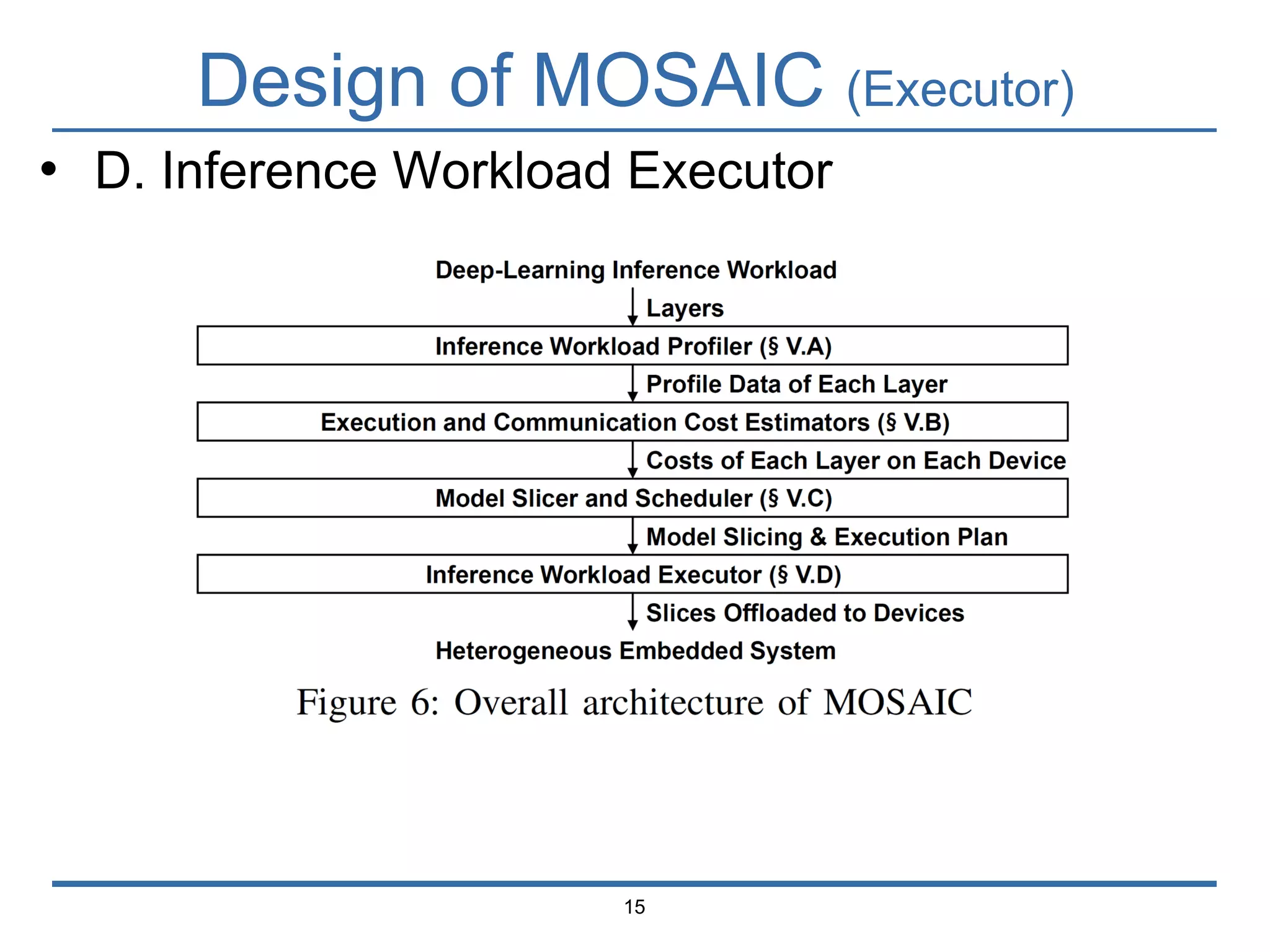

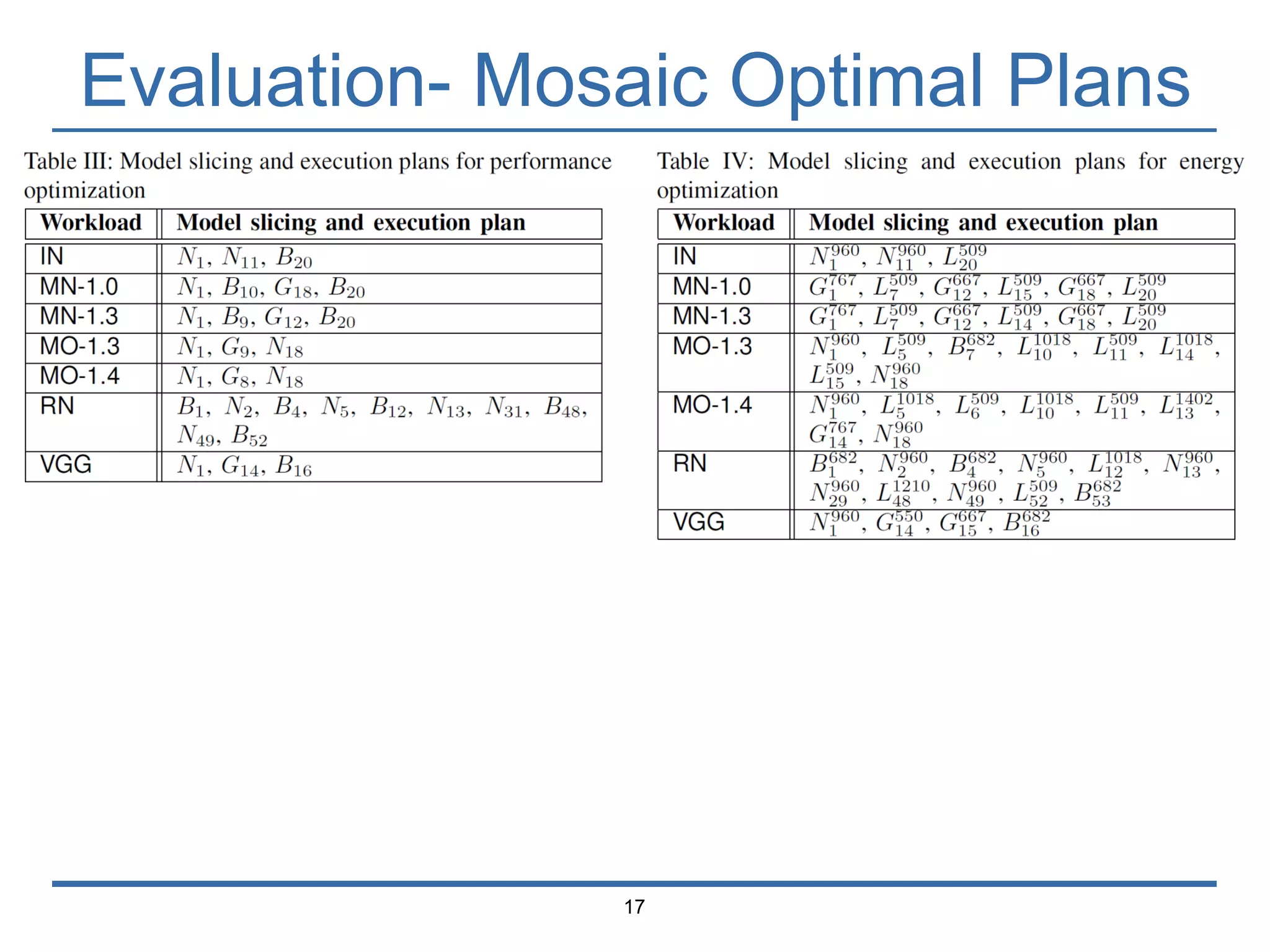
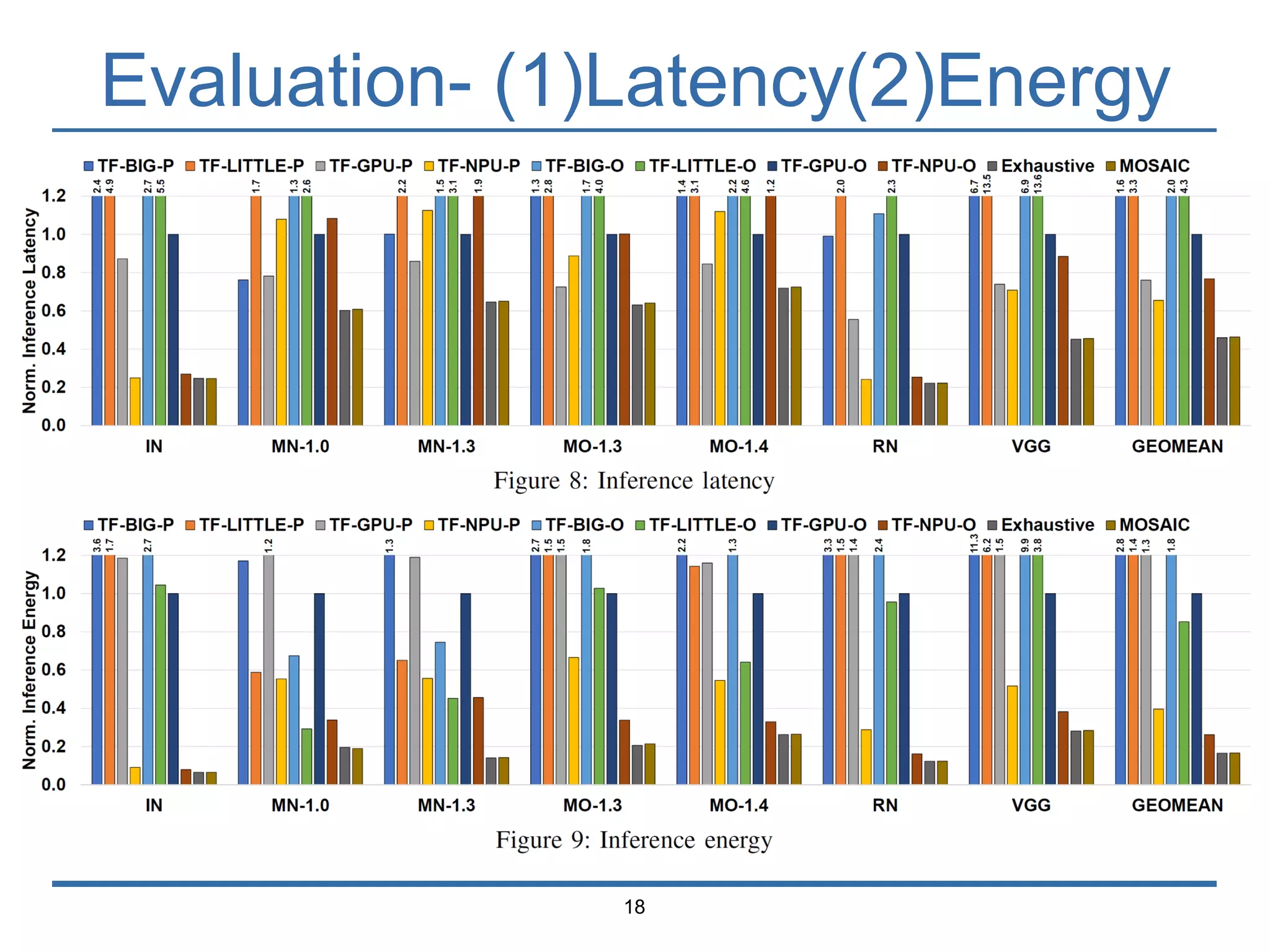
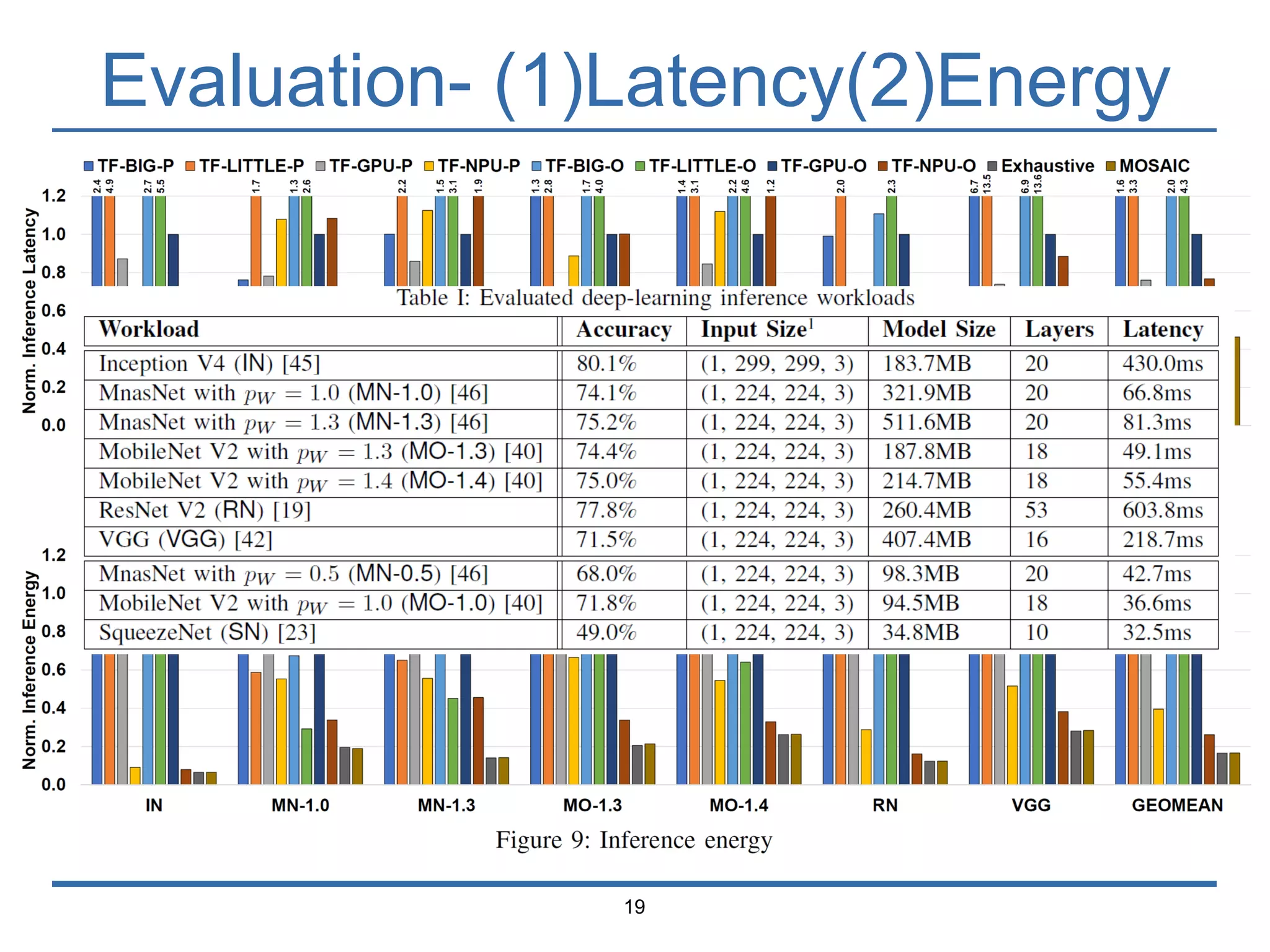
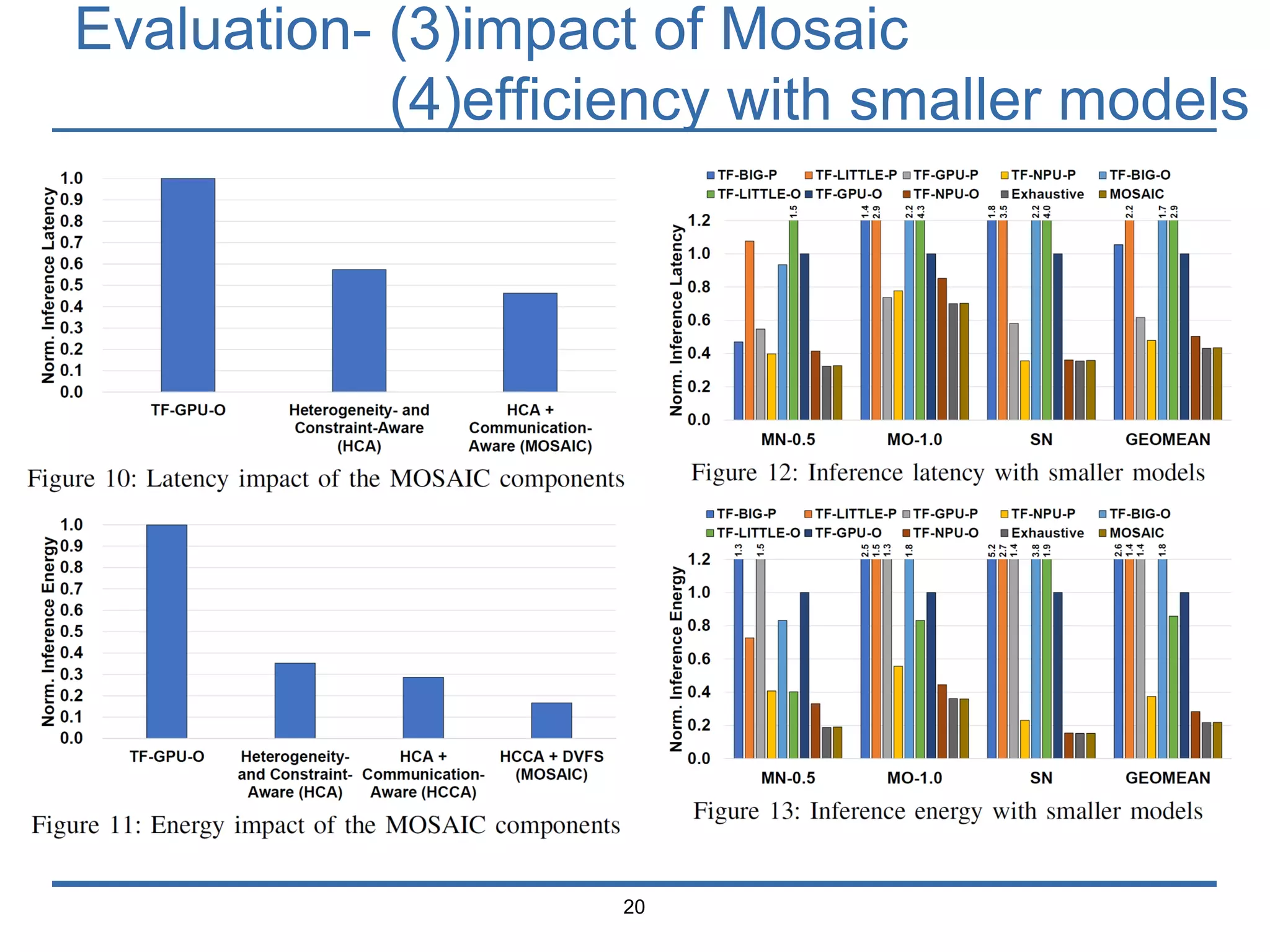
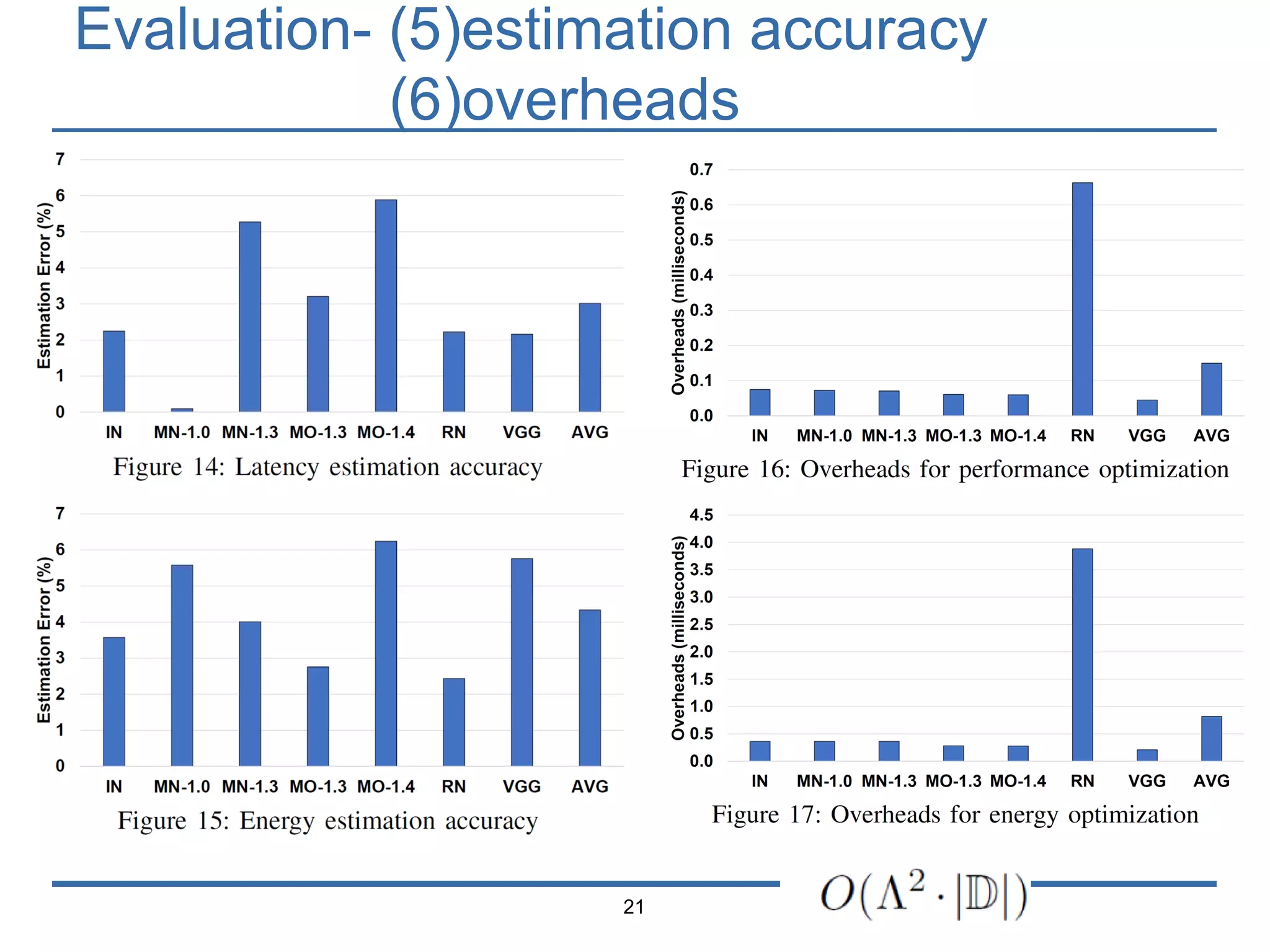


The document presents 'Mosaic', a model slicing and execution framework designed for accurate and efficient inference on heterogeneous embedded systems. It leverages model profiling and dynamic programming to optimize layer execution and communication costs, demonstrating significant improvements with lower inference latency and energy consumption compared to existing methods. Preliminary experiments highlight Mosaic's effectiveness in managing resources across different computing architectures while maintaining high estimation accuracy and low overheads.



























































