Downloaded 290 times







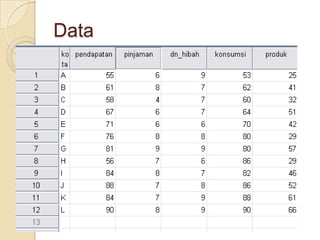



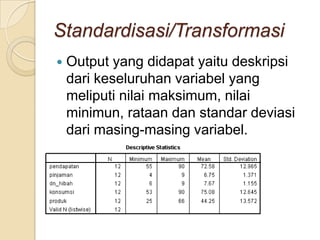








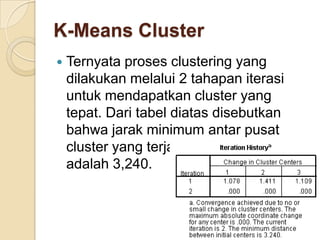
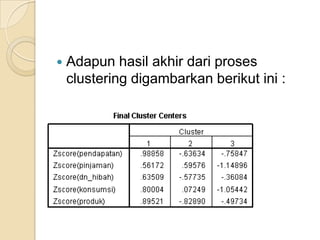







Metode statistik multivariat digunakan untuk menganalisis data yang melibatkan lebih dari satu variabel. Teknik k-means cluster digunakan untuk mengelompokkan kota-kota ke dalam 3 kelompok berdasarkan karakteristik ekonomi mereka."























































































