
Recommended
More Related Content
What's hot
What's hot (19)
Similar to Narasi
Similar to Narasi (20)
Recently uploaded
Recently uploaded (9)
Narasi
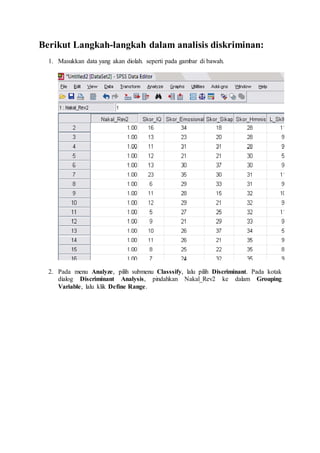
- 1. Berikut Langkah-langkah dalam analisis diskriminan: 1. Masukkan data yang akan diolah. seperti pada gambar di bawah. 2. Pada menu Analyze, pilih submenu Classsify, lalu pilih Discriminant. Pada kotak dialog Discriminant Analysis, pindahkan Nakal_Rev2 ke dalam Grouping Variable, lalu klik Define Range.
- 2. 3. Lalu pada kotak kecil, bagian minimum diisi dengan kode terkecil dan maximum diisi dengan kode terbesar dari variabel respon, pada contoh kasus disini,masukkan angka “1” untuk minimum dan “2” untuk maximum. Kemudian klik Continue. 4. Kembali ke kotak dialog Discriminant Analysis, lalu pada Independents diisi dengan variabel penjelas. Metode yang sering dipaparkan pada literatur-literatur adalah metode bertatar (stepwise), maka kali ini hanya akan diberi contoh penggunaan metode ini. Pada contoh kasus di sini, variabel independents adalah variabel yang tersisa tadi. Kemudian pindahkan variable yang tersisa ke dalam Independents.lalu, pilih dan klik Statistics.
- 3. 5. Pada kotak kecil, centangkan kotak means, univariate ANOVA’s, Box’s M, serta Unstandardized. Lalu, Continue. 6. Kembali ke kotak dialog Discriminant Analysis, lalu pada Classification, lalu diberi tanda cek di All group equal, Casewise result, Summary table, dan Within-groups. Lalu, klik Continue.
- 4. Interpretasi hasil analisis diskriminan Uji Asumsi Analisis diskriminan Uji Kesamaan matriks ragam-peragam antar kelompok Pada kasus ini, kita menguji asumsi kesamaan matrik ragam-peragam antara kelompok nakal menengah ke atas dan nakal ringan digunakan statistic uji Box’s M.
- 5. Dengan tingkat kepercayaan 95%, kelompok-1 dan kelompok-2 memiliki matriks ragam-peragam yang sama dilihat nilai sig 0.46 yang lebih besar dari 0.05(alpha). Asumsi semua kelompok memiliki matrik ragam-peragam yang sama terpenuhi. Selain itu, kesimpulan dapat diambil dengan melihat nilai log determinan dari tiap-tiap kelompok pada tabel log determinants. Nilai log determinan kelompok menengah ke atas = 13.103 dan kelompok ringan = 12.132. Hasil keduanya relative sama, yang mengindikasikan ragam-peragam untuk tiap kelompok sama. Perbedaan rata-rata antar kelompok Untuk uji perbedaan rata-rata antar kelompok menggunakan uji wilks lambda.
- 6. Dengan melihat nilai signifikansi yang lebih kecil dari alpha (0.05), sehingga dapat dikatakan bahwa terdapat perbedaan rata-rata antara kelompok 1 dan kelompok 2 dengan asumsi perbedaan rata-rata antar kelompok terpenuhi. Selain itu, juga dapat dilihat dari hasil tabel Test of Equality of Group Means mengenai perbedaan signifikan antar kelompok pada setiap peubah bebas. Dari hasil Tabel Test Of Equality Of Group Means kita dapat mengetahui hal sebagai berikut. 1. Karakteristik IQ, Kecerdasan Emosional, Sikap, Keharmonisan Keluarga, Lama SekolahAnak, Lama waktu bermain, dan Umur memiliki P-value < 0,05 berarti bahwa kategori anak nakal ringan berbeda signifikan dengan anak nakal menengah ke atas. Terdapat 7 peubah yang signifikan berbeda antar kelompok. 2. Dalam pengolahan SPSS nilai jumlah peubah p, dari hasil output ini terdapat 70% dari p yang berbeda signifikan. Karena ≥ 50% p, maka analisis diskriminan dapat dilakukan.
- 7. 3. Asumsi perbedaan rata-rata antar kelompok telah terpenuhi karena lebih dari 50 persen dari total peubah yang dianalisis telah signifikan berbeda antar kelompok. 4. Tiga peubah yang tidak signifikan yaitu jumlah anggota rumah tangga, jumlah saudara kandung, dan lama sekolah pengasuh. Ketiga peubah yang tidak lolos akan dikeluarkan dari daftar peubah yang akan disertakan pada analisis diskriminan. Analisis Hasil Analisis Diskriminan Stepwise statistics Berdasarkan hasil dari proses stepwise method dengan iterasi sebanyak empat kali didapatkan empat peubah yang signifikan membedakan kelompok nakal menengah ke atas dan nakal ringan karena nilai signifikansinya yang lebih kecil dari 0,05. Dengan tingkat residual error yang semakin kecil yang dinyatakan oleh Wilk’s Lambda mulai dari level 0,414 dan terus berkurang hingga mencapai 0,270 setelah keempat peubah tersebut terpilih untuk dimasukkan ke dalam fungsi diskriminan. Hal ini berarti kemampuan diskriminasi dari fungsi yang dihasilkan semakin meningkat. Summary of Canonical Discriminant Nilai akar ciri (eigen value) menunjukkan ada atau tidaknya multikolinearitas antar peubah bebas. Multikolinearitas akan terjadi bila nilai akar ciri (eigen value) mendekati 0 (nol). Berdasarkan hasil pengolahan data didapatkan nilai akar ciri yang menjauhi nol, yaitu sebesar
- 8. 2,709. Keadaan ini dapat diartikan bahwa fungsi diskriminan yang diperoleh cukup baik karena tidak terjadi multikolinearitas di antara sesama peubah bebasnya. Pada tabel Eigen Value terdapat nilai canonical correlation. Canonical correlation digunakan untuk mengukur derajat hubunggan antara besarnya variabilitas yang mampu diterangkan oleh variabel independen terhadap variabel dependen. Dari tabel di atas, diperoleh nilai canonical correlation sebesar 0,855, bila dikuadratkan menjadi (0,855x0,855)=0,7310; artinya 73,10% varians dari variabel dependen dapat dijelaskan dari model diskriminan yang terbentuk canonical discriminant function coefficients Tabel canonical discriminant function coefficients menerangkan model diskriminan yang terbentuk, yaitu : Y = -10,467 + 0,072IQ + 0,168Emosi + 0,076Perilaku + 0,047Harmonis. Function at Group Centroid
- 9. Group Centroid merupakan rata-rata nilai diskriminan dari tiap-tiap observasi di dalam masing-masing kelompok. Group Centroid untuk kelompok nakal menengah ke atas adalah sebesar -1,161, sedangkan untuk kelompok nakal ringan adalah sebesar 2,285. Ini berarti bahwa secara rata - rata skor diskriminan kedua kelompok berbeda cukup besar. Sehingga fungsi diskriminan yang diperoleh dapat membedakan secara baik kelompok yang ada. Classification results Tabel ini menggambarkan crosstabulasi antara model awal dengan pengklasifikasian model diskriminan. Terlihat ada 4 responden yang salah klasifikasi, yaitu 3 responden yang awalnya ada pada kelompok kenakalan menengah keatas kemudian diprediksi masuk dalam kelompok kenakalan ringan dan 1 responden yang awalnya ada pada kelompok kenakalan ringan kemudian diprediksi masuk dalam kelompok kenakalan menengah keatas. Secara keseluruhan model diskriminan yang terbentuk mempunyai tingkat validasi yang cukup tinggi yaitu 95,8%. Hasil survei di atas menunjukkan hasil keakuratan model diskriminan yang cukup tinggi.
- 10. ASUMSI ANALISIS DISKRIMINAN Analisis diskriminan mempunyai asumsi bahwa data berasal dari multivariate normal distribution dan matrik kovarian kedua kelompok perusahaan adalah sama. Asumsi mul tivariate normal distribution penting untuk menguji signifikansi dari variabel diskriminator dan fungsi diskriminan. Jika data tidak normal secara multivariate, maka secara teori uji signifikansi menjadi tidak valid. Hasil klasifikasi menurut teori juga dipengaruhi oleh multivariate normal distribution. Apabila diketahui bahwa asumsi multivariate normal distribution tidak dipenuhi maka sebaiknya menggunakan analisis logistic regression. Logistic regression tidak memerlukan asumsi distribusi normal untuk variabel bebasnya. Data tentatif ini akan kita gunakan untuk menjelaskan teknik analisis diskriminan. Contoh berikut adalah dua rasio keuangan EBITASS (rasio earning before interest and tax terhadap total asset) dan ROTC (return on total capital) 24 sampel perusahaan yang dibagi ke dalam dua kelompok yaitu 12 perusahaan sehat dan 12 perusahaan bangkrut. Apabila data ini kita plot, maka dapat dilihat sampai seberapa jauh kedua rasio keuangan ini mampu membedakan kedua kelompok perusahaan sehat dan perusahaan bangkrut.
- 11. Gambar di atas menunjukkan bahwa kedua kelompok perusahaan sehat dan bangkrut dapat dipisahkan secara nyata dilihat dari rasio EBITASS DAN ROTC. Hal ini berarti bahwa setiap rasio keuangan dapat membedakan dua kelompok perusahaan sehat dan bangkrut. Melihat perbedaan dua kelompok perusahaan dengan hanya melihat satu variabel disebut dengan analisis univariate. Uji statistik untuk univariate dapat dilakukan dengan uji beda t-test. Sedangkan melihat perbedaan dua kelompok perusahaan berdasarkan pada kombinasi kedua rasio keuangan secara bersama-sama disebut dengan analisis multivariate. Variabel yang memberikan pembeda (diskriminan) terbaik disebut dengan variabel diskriminan (discriminator variable). Mengidentifikasi sekelompok variabel yang dapat menjadi pembeda terbaik kedua kelompok perusahaan adalah tujuan utama dari analisis diskriminan. Berikut ini langkah analisis diskriminan : IDENTIFIKASI AXIS BARU Apabila pada gambar di atas kita membuat axis baru Z yang merupakan garis diagonal dengan sudut 45o dari garis EBITASS, maka kita memproyeksikan katakanlah titik P pada garis diagonal Z dengan persamaan : Zp = w1 EBITASS + w2 ROTC Besarnya w1 = cos 45 = 0,707 dan w2 = sin 45 = 0,707 dengan demikian persamaan Zp menjadi :
- 12. Zp = 0,707 EBITASS + 0,707 ROTC Persamaan ini merupakan kombinasi linear dari rasio keuangan EBITASS dan ROTC untuk perusahaan P. Jadi proyeksi suatu titik pada garis Z memberikan variabel baru Z yang merupakan kombinasi linear dari variabel rasio keuangan. Jadi tujuan kedua analisis diskriminan adalah mencari axis baru yaitu Z dimana variabel baru Z memberikan maksimum kemampuan untuk membedakan antara dua kelompok perusahaan. Axis baru ini disebut linear discriminant function atau sering disingkat discriminant function. Proyeksi suatu titik pada discriminant function (atau nilai dari variabel baru Z) disebut discriminant score. Tujuan ketiga yang ingin dicapai oleh analisis diskriminan adalah pengelompokkan atau klasifikasi observasi ke dalam satu dari dua kelompok perusahaan di masa datang. MEMILIH VARIABEL DISKRIMINATOR Perbedaan rata-rata masing-masing rasio keuangan untuk kedua kelompok perusahaan sehat dan bangkrut dapat diuji dengan uji beda t-test. Hasil uji t test dapat di bawah ini. Nilai t hitung untuk EBITASS adalah 9,854 dan ROTC sebesar 11,528. Oleh karena nilai t hitung lebih besar dari nilai t tabel pada tingkat signifikan 5%, maka dapat disimpulkan bahwa kedua rasio keuangan ini mampu membedakan kedua kelommpok perusahaan dan akan digunakan untuk membentuk fungsi diskriminan. U t test hanya berdasarkan pada pendekatan univariate, yaitu uji t test untuk masing-masing rasio keuangan. Pendekatan yang lebih disukai adalah dengan uji multivariate, di mana kedua rasio keuangan diuji secara simultan atau bersama-sama. FUNGSI DISKRIMINAN DAN KLASIFIKASI Misalkan kombinasi linear atau fungsi diskrimina yang membentuk variabel baru (score discriminant) sebagai berikut : Z = w1 EBITASS + w2 ROTC Di mana Z adalah fungsi diskriminan, maka tujuan analisis diksriminan adalah menentukan nilai w1 dan w2 dari fungsi diskriminan di atas agar memaksimumkan nilai lambda. lambda = between group sum of square / within group sum of square Fungsi diskriminan didapat dengan memaksimumkan nilai lambda dan disebut Fisher's linear
- 13. discriminant function. Langkah analisis dengan SPSS. a. buka file b. dari menu utama SPSS, pilih menu Statistics/Analyze kemudian submenu Classify, lalu pilih Discriminant. c. tampak di layar windows Discriminant Analysis. d. pada Box Grouping Variable isikan CODE dan definisikan perusahaan sehat 1 dan bangkrut 2. e. pada Box Independent isikan variabel EBITASS dan ROTC. f. pilih Statistics dan aktifkan pilihan test statistics descriptive, Matrice dan function coefficient.
- 14. Penilaian signifikan variabel diskriminan dapat dilihat dari nilai rata-rata dari rasio keuangan apakah berbeda secara signifikan untuk perusahaan sehat dan bangkrut. Untuk menguji apakah ada perbedaan secara signifikan antara kedua kelompok perusahaan dapat dilakukan dengan uji t test. Alternatif lain adalah dengan menggunakan Wilk's L test statistics. Semakin kecil nilai Wilk's L maka semakin besar probabilitas hipotesis nol (tidak ada perbedaan rata-rata populasi) ditolak. Untuk menguji signifikansi nilai Wilk's L maka dapat dikonversikan kedalam F ratio. Dari tampilan group statistik jelas bahwa nilai rata-rata kedua rasio keuangan antara perusahaan sehat dan bangkrut berbeda yaitu 0,18533 untuk perusahaan sehat dan 0,035167 untuk perusahaan bangkrut dilihat dari rasio EBITASS. Sedangkan rasio ROTC dengan rata-rata 0,18350 untuk perusahaan sehat dan 0,00333 untuk perusahaan bangkrut. Dilihat dari test statistik Wilk's L jelas ada perbedaan secara signifikan yaitu untuk EBITASS nilai Wilk's L sebesar 0,185 dan signifikan pada 0,000. Sedangkan nilai Wilk's L ROTC sebesar 0,142 juga signifikan pada 0,000. Hasil ini menunjukkan bahwa kedua variabel rasio keuangan dapat digunakan untuk membentuk variabel diskriminan.
- 15. Persamaan estimati fungsi diskriminan unstandardized dapat dilihat dari output Canonical Discriminant Function Coefficient dengan persamaan sebagai berikut : Z = -3,195 + 13,430 EBITASS + 18,353 ROTC Untuk menguji signifikansi statistik dari fungsi diskriminan digunakan multivariate test of signifikance. Oleh karena dalam kasus ini lebih dari satu variabel deskriminator yaitu EBITASS dan ROTC, maka untuk menguji perbedaan kedua kelompok perusahaan untuk semua variabel secara bersama-sama digunakan multivariate test. Uji Wilk's L dapat diaproksimasi dengan statistik Chi-square. Besarnya nilai Wilk's L sebesar 0,115 atau sama dengan Chi -square 45,498 dan ternyata nilai ini signifikan pada 0,000 maka dapat disimpulkan bahwa fungsi diskriminan signifikan secara statistik yang berarti nilai rata-rata score diskriminan untuk kedua kelompok perusahaan berbeda secara nyata. Walaupun secara statistik perbedaan kedua kelompok perusahaan itu signifikan, tetapi untuk tujuan praktis perbedaan kedua kelompok perusahaan tadi tidak begitu besar. Hal ini dapat terjadi pada kasus dengan jumlah sampel yang besar. Untuk menguji seberapa besar dan berarti perbedaan antara kedua kelompok perusahaan dapat dilihat dan nilai Square Canonical Correlation (CR2). Square Canonical Correlation identik dengan R2 pada regresi yaituu mengukur variasi antara kedua kelompok perusahaan yang dapat dijelaskan oleh variabel diskriminannya. Jadi CR2 mengukur sebagai kuat fungsi diskriminan. Tampilan output Eigenvalues menunjukkan bahwa besarnya Canonical Correlation adalah sebesar 0,941 atau besarnya Square Canonical Correlation (CR2) = (0,941)2 atau sama dengan 0,885. Jadi
- 16. dapat disimpulkan bahwa 88,5% variasi antara kelompok perusahaan sehat dan bangkrut yang dapat dijelaskan oleh variabel diskriminan rasio EBITASS dan ROTC. Menilai pentingnya variabel diskriminan dan arti dari fungsi diskriminan dapat dilakukan dengan melihat fungsi diskriminan standardized. Tampilan standardized canonical discriminat function menunjukkan bahwa besarnya koefisien EBITASS 0,501 dan koefisien ROTC sebesar 0,703. Koefisien yang sudah distandarisasi digunakan untuk menilai pentingnya variabel diskriminator secara relatif dalam membentuk fungsi diskriminan. Makin tinggi koefisien yang telah distandarisasi, maka makin penting variabel tersebut terhadap variabel lainnya dan sebaliknya. Variabel rasio EBITASS relatif lebih penting dibandingkan variabel rasio ROTC dalam membentuik fungsi diskriminan. Oleh karena score diskriminan adalah indeks gabungan atau kombinasi linear dari variabel awal, maka perlu untuk mengetahui apakah arti dari score diskriminan. Nilai loading dari structure coefficient dapat digunakan untuk menginterpretasikan kontribusi setiap variabel untuk membentuk fungsi diskriminan. Nilai loading variabel diskriminator merupakan korelasi antara score diskriminan dan variabel diskriminator dan nilai loading akan berkisar +1 dan -1. Makin mendekati 1 (satu) nilai absolut dari loading, maka tinggi komunalitas antara variabel diskriminan dan fungsi diskriminan dan sebaliknya. Tampilan struktur matrik menunjukkan bahwa besarnya loading untuk EBITASS 0,756 dan besarnya loading untuk ROTC sebesar 0,884. Oleh karena loading kedua variabel rasio keuangan ini tinggi, maka score diskriminan dapat diinterpretasikan sebagai ukuran kesehatan keuangan perusahaan. Tujuan ketiga dari analisis diskriminan adalah mengklasifikasikan observasi di masa datang ke dalam satu dari dua kelompok perusahaan. Output SPSS memberikan nilai tingkat klasifikasi sebesar 100%.
- 17. Klasifikasi dari observasi secara esensial akan mengurangi pembagian ruang diskriminan ke dalam dua region. Nilai score diskriminan yang membagi ruang kedalam dua region disebut nilai cutoff. Makin tinggi nilai EBITASS dan ROTC makin tinggi nilai score diskriminan dan sebaliknya. Oleh karena perusahaan yang mempunyai kesehatan keuangan akan memiliki nilai yang lebih tinggi untuk kedua rasio keuangan, perusahaan yang sehat akan memiliki score diskriminan lebih tinggi daripada perusahaan bangkrut. Jadi perusahaan akan dikelompokkan sebagai perusahaan dapat sehat jika score diskriminannya lebih tinggi daripada nilai cutoff dan perusahaan akan dikelompokkan sebagai perusahaan bangkrut jika score diskriminannya lebih kecil dari nilai cutoff. Secara umum nilai cutoff yang dipilih nilai yang meminimumkan jumlah incorrect classification atau kesalahan misklasifikasi atau dapat dihitung dengan rumus: Cutoff = (Z1 + Z2) / 2 Di mana Zj adalah rata-rata score diskriminan kelompok j. Rumus ini berasumsi jumlah sampel kedua kelompk sama. Dalam hal jumlah sampel kedua kelompok tidak sama maka rumus cutoff menjadi :
- 18. Cutoff = (n1Z1 + n2Z2) / (n1 + n2) Di mana ng adalah jumlah observasi pada kelompok g. Tampilan output SPSS memberikan rata-rata score diskriminan untuk kelompok 1 sebesar 2,662 dan rata-rata score diskriminan untuk kelompok 2 sebesar -2,662 dan memberikan nilai cutoff nol. Ringkasan nilai klasifikasi dapat dilihat pada classification matrix atau confussion matrix. Hasil matrik klasifikasi menunjukkan bahwa seluruh observasi telah diklasifikasikan secara benar dengan ketepatan 100%.