Download as PDF, PPTX






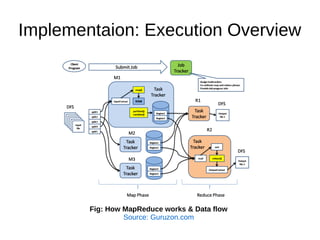
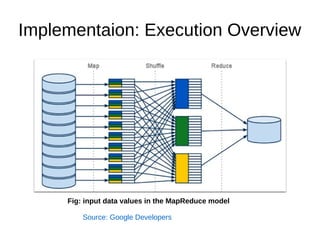

















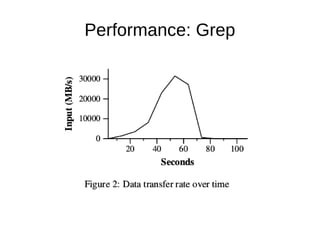


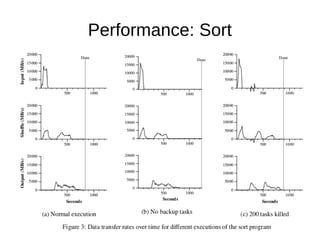




This document summarizes the MapReduce programming model and its implementation for processing large datasets in parallel across clusters of computers. The key points are: 1) MapReduce expresses computations as two functions - Map and Reduce. Map processes input key-value pairs and generates intermediate output. Reduce combines these intermediate values to form the final output. 2) The implementation automatically parallelizes programs by partitioning work across nodes, scheduling tasks, and handling failures transparently. It optimizes data locality by scheduling tasks on machines containing input data. 3) The implementation provides fault tolerance by reexecuting failed tasks, guaranteeing the same output as non-faulty execution. Status information and counters help monitor progress and collect metrics.























































































