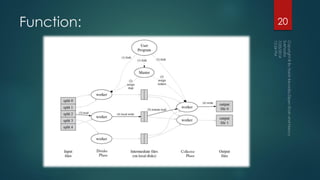
The document discusses the concept of computer clusters used for processing large amounts of data, emphasizing the need for distributed computing to manage big data efficiently. It explains how a master node coordinates the tasks of worker nodes and how algorithms are needed to handle interdependent data inputs. The document also describes the MapReduce programming model as a method to generate scalable and fault-tolerant systems for data processing tasks.



























![[IJET V2I5P18] Authors:Pooja Mangla, Dr. Sandip Kumar Goyal](https://cdn.slidesharecdn.com/ss_thumbnails/ijet-v2i5p18-161107144130-thumbnail.jpg?width=640&height=640&fit=bounds)


















































































