Download as PDF, PPTX



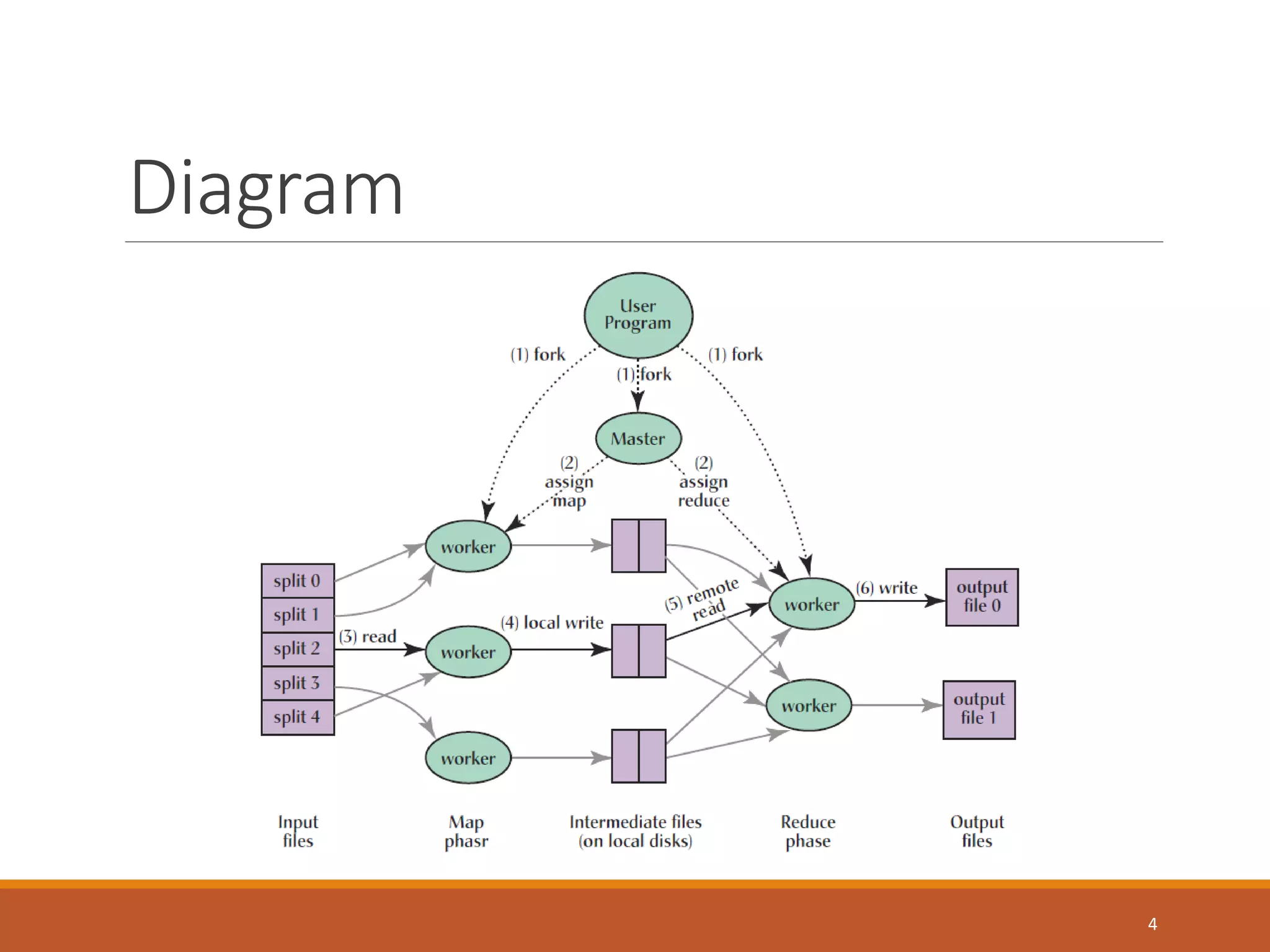




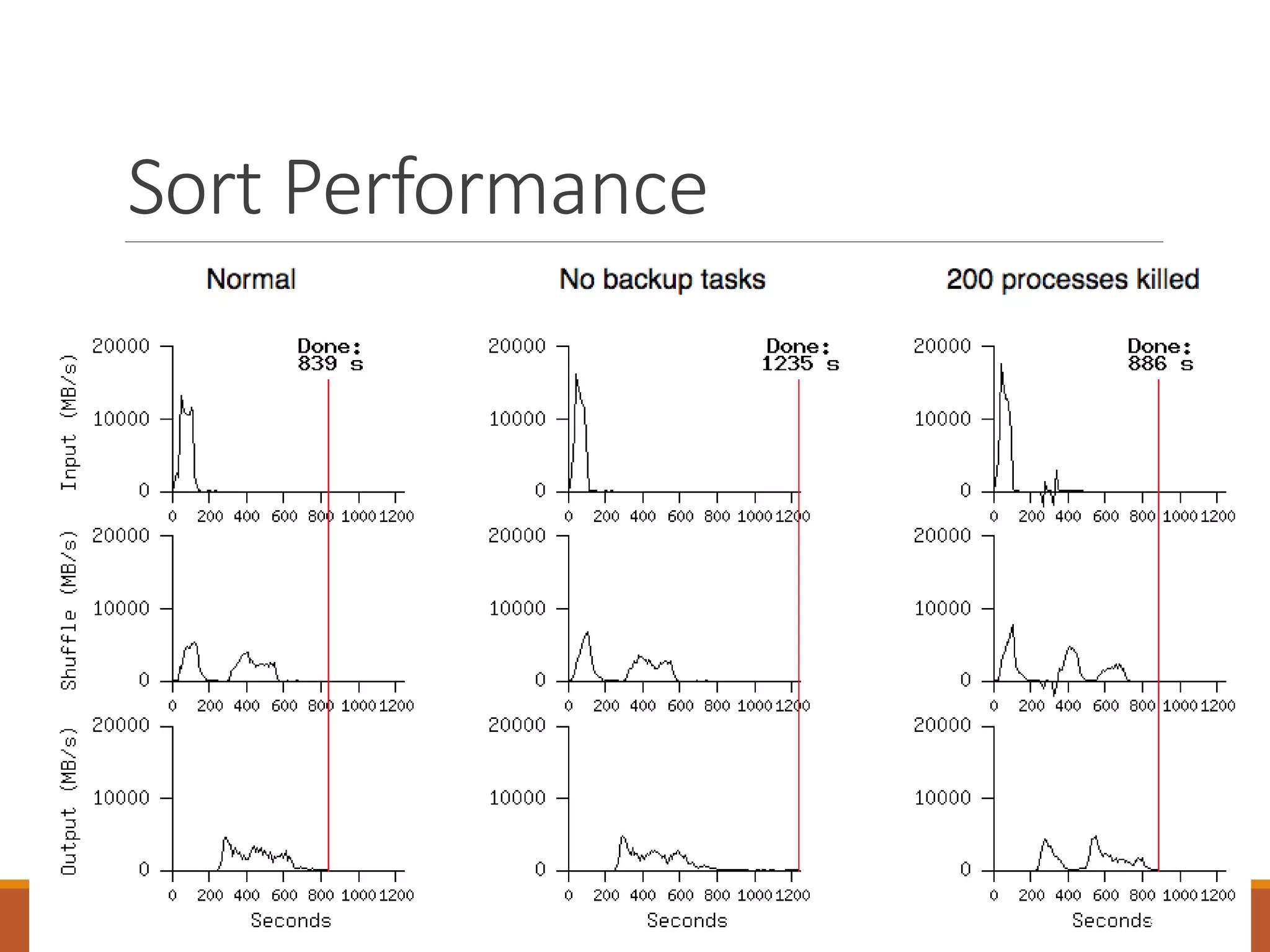









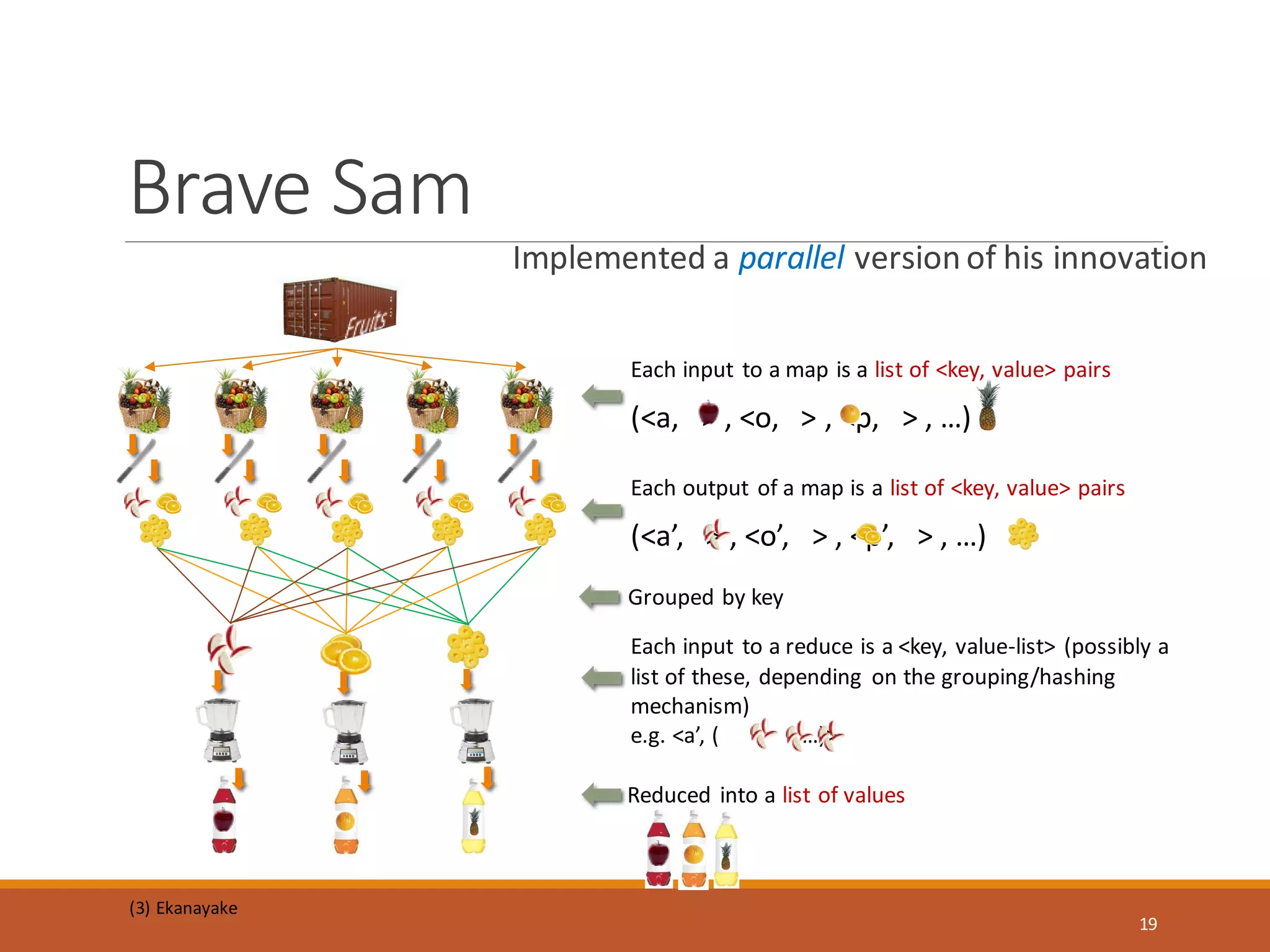
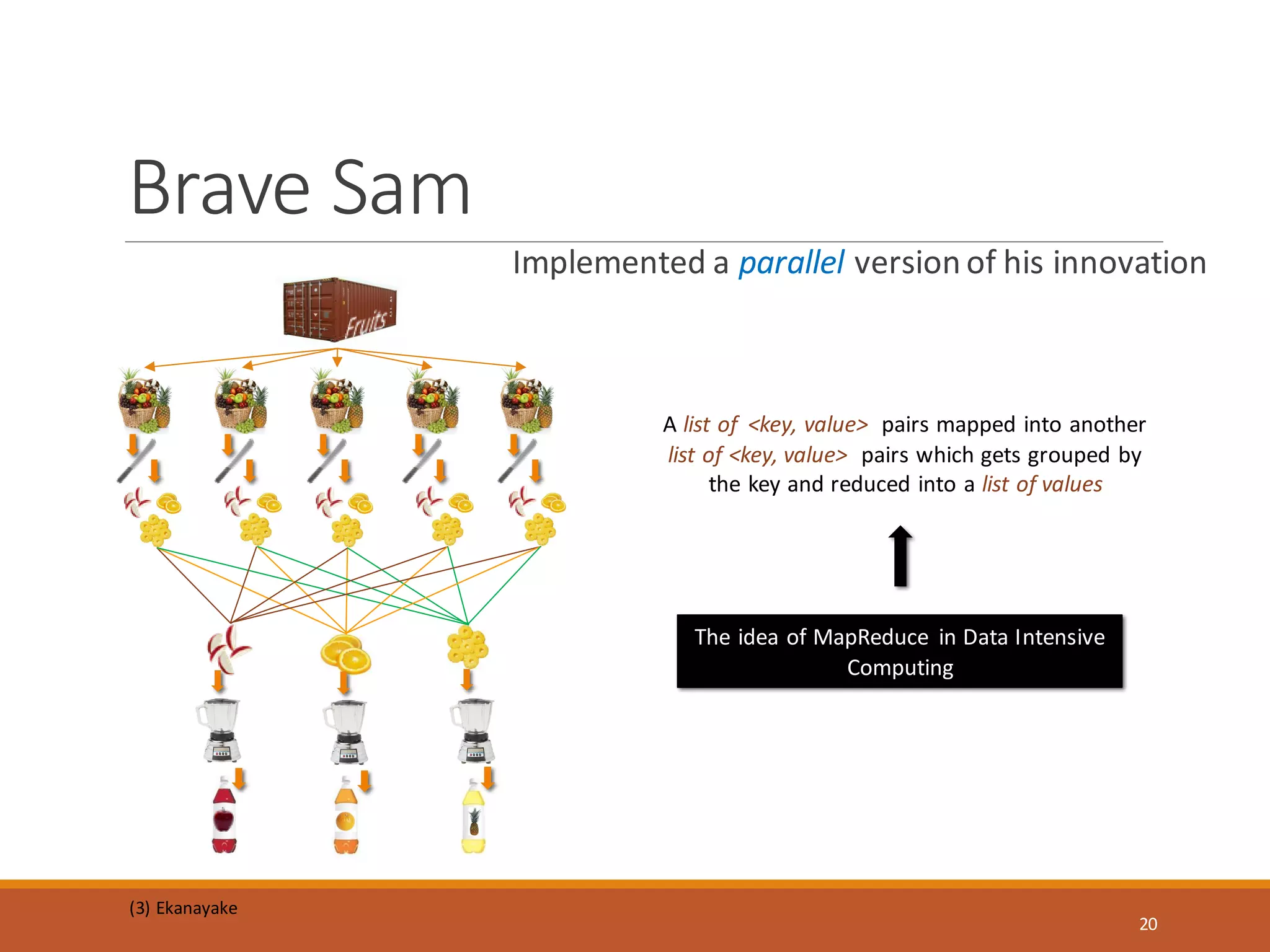



MapReduce is a programming model and software framework for processing large datasets in a distributed computing environment. It was originally developed at Google for processing web search data. The MapReduce framework breaks jobs into many small sub-tasks that are processed in parallel across large clusters of commodity servers. It handles parallelization, scheduling, load balancing, and fault tolerance. MapReduce jobs consist of a map step that processes key-value pairs to generate intermediate key-value pairs and a reduce step that merges all intermediate values associated with the same intermediate key.


























![[FOSS4G KOREA 2014]Hadoop 상에서 MapReduce를 이용한 Spatial Big Data 집계와 시스템 구축](https://cdn.slidesharecdn.com/ss_thumbnails/foss4g2014hadoop-geohash-v02-140829035316-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)











































