Download to read offline




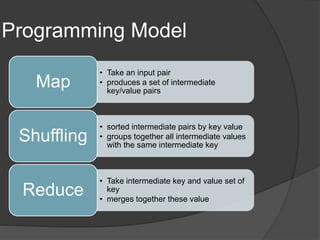
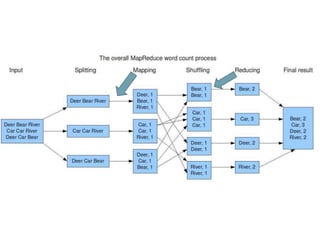


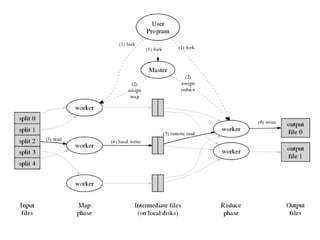




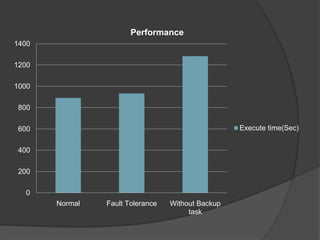







The document describes MapReduce, a programming model for processing large datasets in a distributed environment. MapReduce allows users to write map and reduce functions, hiding the complexity of parallelization, fault tolerance, and load balancing. It works by dividing the input data into mapped key-value pairs, shuffling and sorting by key, and reducing the values for each key. This makes it easy to write distributed programs for tasks like inverted indexing, sorting, and counting URL frequencies. The implementation assigns tasks to worker nodes, handles failures, and optimizes for locality and load balancing.
















































































