Downloaded 27 times






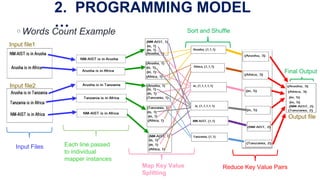



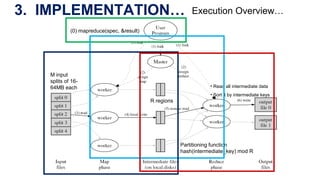






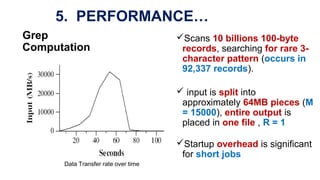
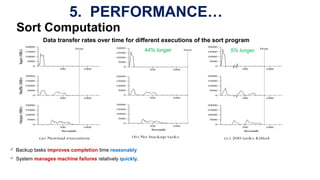



The document describes MapReduce, a programming model and software framework for processing large datasets in a distributed computing environment. It discusses how MapReduce allows users to specify map and reduce functions to parallelize tasks across large clusters of machines. It also covers how MapReduce handles parallelization, fault tolerance, and load balancing transparently through an easy-to-use programming interface.























































































