Downloaded 45 times




















![public int run(String[] args) throws Exception {
Configuration conf = getConf();
JobConf job = new JobConf(conf, MyJob.class);
Path in = new Path(args[0]);
Path out = new Path(args[1]);
FileInputFormat.setInputPaths(job, in);
FileOutputFormat.setOutputPath(job, out);
job.setJobName("MyJob");
job.setMapperClass(MapClass.class);
job.setReducerClass(Reduce.class);
job.setInputFormat(KeyValueTextInputFormat.class);
job.setOutputFormat(TextOutputFormat.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
job.set("key.value.separator.in.input.line", ",");
JobClient.runJob(job);
return 0;
}](https://image.slidesharecdn.com/mapreduce-130417065750-phpapp02/85/MapReduce-22-320.jpg)
![public static void main(String[] args) throws Exception {
int res = ToolRunner.run(new Configuration(), new
MyJob(), args);
System.exit(res);
}
}
To Run it, You have to generate the JAR file, then
you can use the command:
bin/hadoop jar playground/MyJob.jar MyJob
input/cite75_99.txt output](https://image.slidesharecdn.com/mapreduce-130417065750-phpapp02/85/MapReduce-23-320.jpg)

![References
[1] Jeffrey Dean and Sanjay Ghemawat. MapReduce:
Simplified data processing
on large clusters. In OSDI, pages 137–150, 2004.
[2] Lam, Chuck. Hadoop in action. Manning
Publications Co., 2010.
[3] http://hadoop.apache.org/](https://image.slidesharecdn.com/mapreduce-130417065750-phpapp02/85/MapReduce-25-320.jpg)

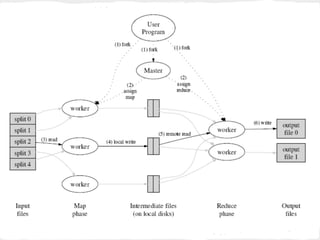
MapReduce is a programming model for processing large datasets in a distributed environment. It consists of a map function that processes input key-value pairs to generate intermediate key-value pairs, and a reduce function that merges all intermediate values associated with the same key. It allows for parallelization of computations across large clusters. Example applications include word count, sorting, and indexing web links. Hadoop is an open source implementation of MapReduce that runs on commodity hardware.










































































