Download as PDF, PPTX

































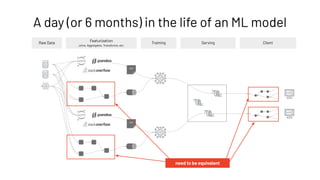

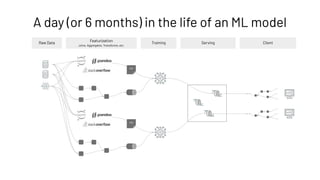
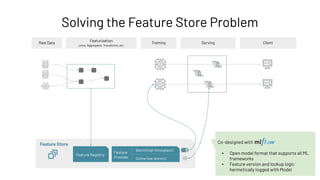

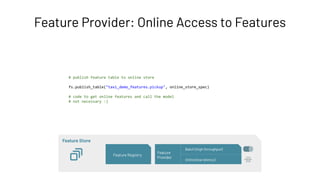
![# register feature table
@feature_store.feature_table
def pickup_features_fn(df):
# feature transformations
return pickupzip_features
fs.create_feature_table(
name="taxi_demo_features.pickup",
keys=["zip", "ts"],
features_df=pickup_features_fn(df),
partition_columns="yyyy_mm",
description="Taxi fare prediction. Pickup features",
)
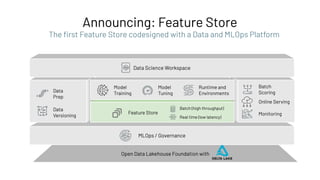
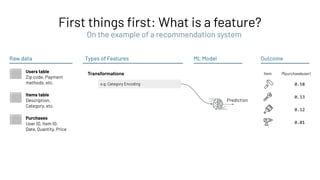
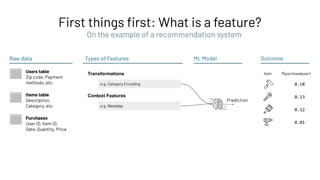
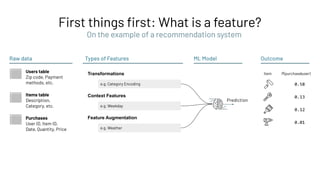
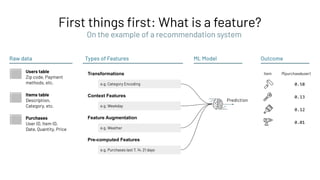
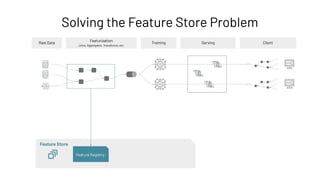
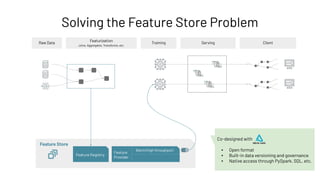
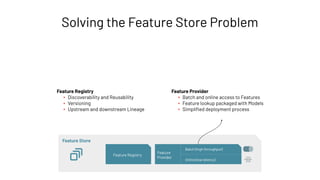
Feature Registry: Creating a Feature Table
Feature Store
Feature Registry
Feature
Provider
Batch (high throughput)
Online (low latency)](https://image.slidesharecdn.com/466clemensmewald-210608234845/85/What-s-New-with-Databricks-Machine-Learning-73-320.jpg)
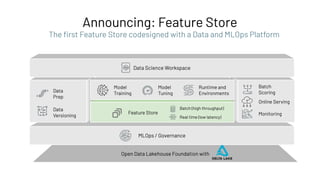
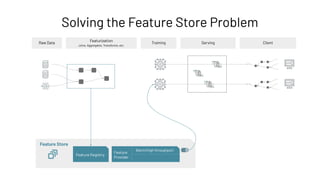
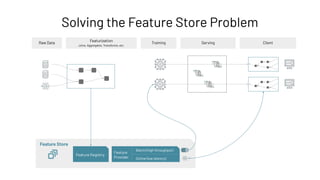
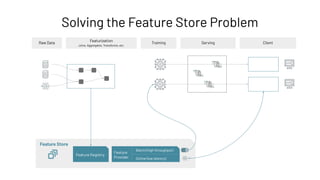
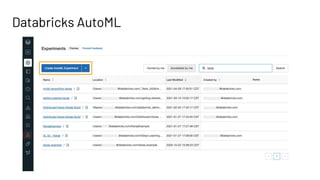
![Feature Provider: Batch Access to Features
# create training set from feature store
training_set = fs.create_training_set(
taxi_data,
feature_lookups = pickup_feature_lookups + dropoff_feature_lookups,
label = "fare_amount",
exclude_columns = ["rounded_pickup_datetime", "rounded_dropoff_datetime"]
)
Feature Store
Feature Registry
Feature
Provider
Batch (high throughput)
Online (low latency)](https://image.slidesharecdn.com/466clemensmewald-210608234845/85/What-s-New-with-Databricks-Machine-Learning-76-320.jpg)










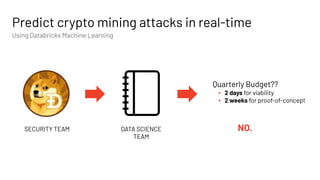

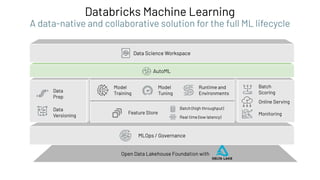

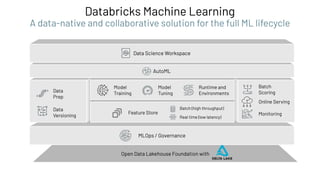



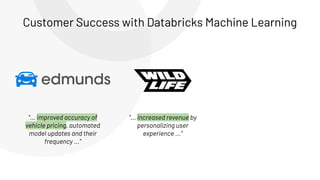
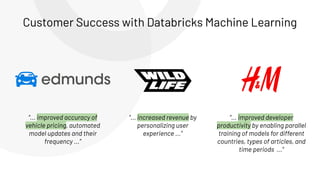


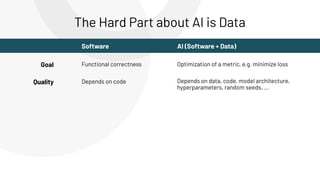
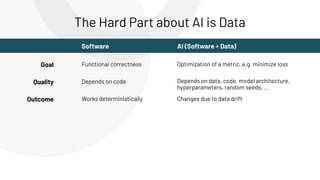
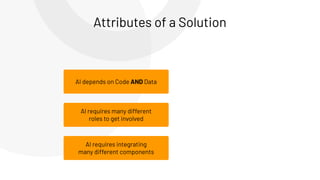
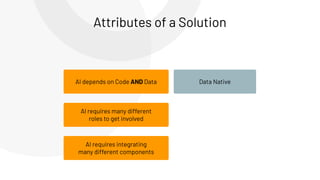
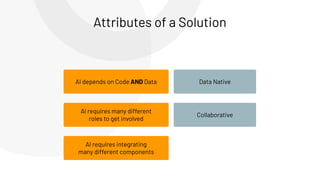
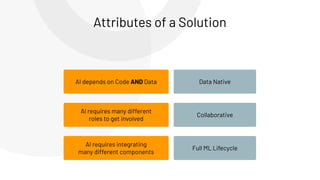
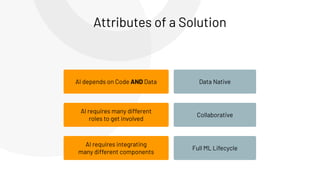
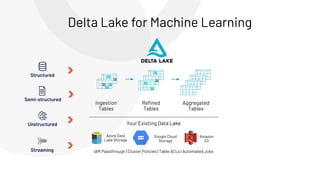
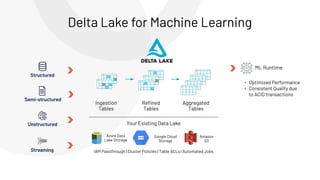
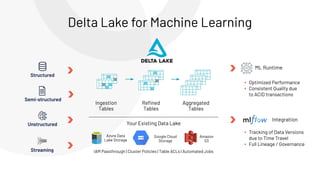
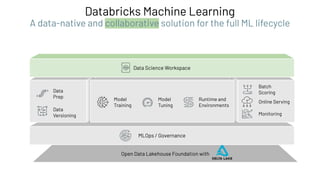
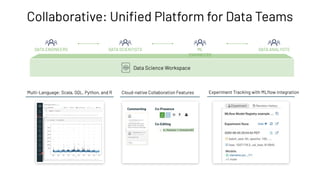
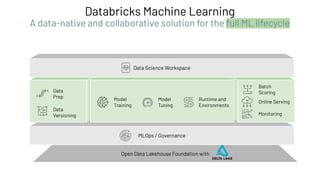
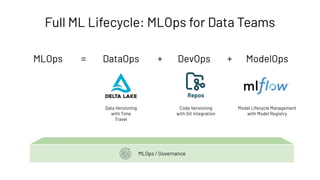
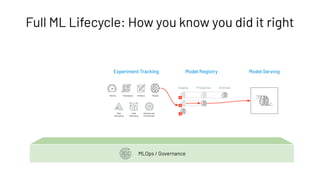
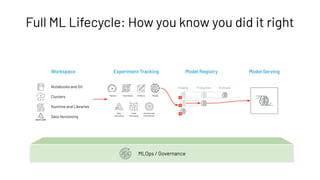
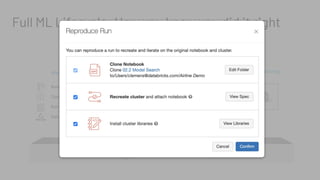
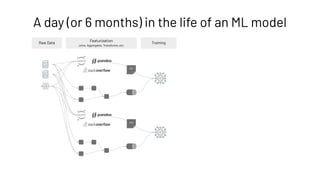
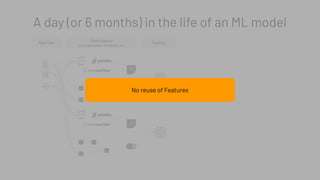
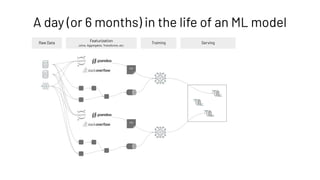
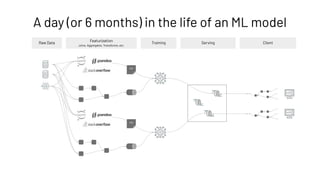
The document discusses the complexities and collaborative nature of AI, emphasizing the necessity for integration between software and data engineering. It highlights the need for robust tooling and a cohesive environment to effectively manage the entire machine learning lifecycle, including data preparation, model training, and governance. Additionally, it introduces Databricks' machine learning platform as a data-native and collaborative solution to streamline these processes.






![[DSC Europe 22] Overview of the Databricks Platform - Petar Zecevic](https://cdn.slidesharecdn.com/ss_thumbnails/petarzecevic-databricksoverview-221130080703-c60d93de-thumbnail.jpg?width=640&height=640&fit=bounds)
















































































