Download as PDF, PPTX






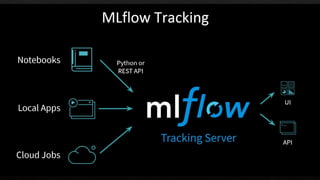




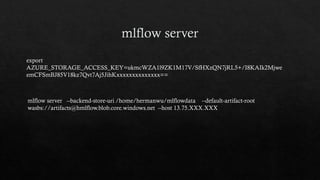
![mlflow.set_tracking_uri(). [remote tracking URIs]
Local file path (specified as file:/my/local/dir)
Database encoded as
<dialect>+<driver>://<username>:<password>@<host>:<port>/<d
atabase
MLFlow tracking server (specified as https://my-server:5000
Databricks workspace (specified as databricks or as
databricks://<profileName>e.](https://image.slidesharecdn.com/sparkmlflow-190906150820/85/Use-MLflow-to-manage-and-deploy-Machine-Learning-model-on-Spark-15-320.jpg)



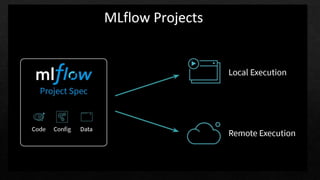









![MLFLOW_TRACKING_URI=http://0.0.0.0:5000 mlflow sklearn serve
--port 5001
--run_id XXXXXXXXXXXXXXXXXXXXXX
--model-path model
curl -X POST
http://127.0.0.1:5001/invocations
-H 'Content-Type: application/json'
-d '[
{
“XXX": 1.111,
“YYYY": 1.22,
“ZZZZ": 1.888
}
]'](https://image.slidesharecdn.com/sparkmlflow-190906150820/85/Use-MLflow-to-manage-and-deploy-Machine-Learning-model-on-Spark-31-320.jpg)










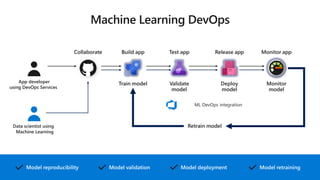






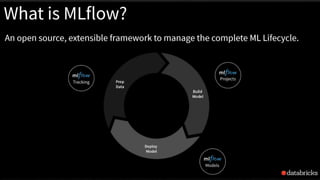
MLflow is a platform for managing the machine learning lifecycle, including tracking experiments, packaging models into reproducible projects, and deploying models into production. It provides APIs and tools to help with experiment tracking, model deployment, and model monitoring. MLflow supports many frameworks like PyTorch, TensorFlow, Keras, and Spark ML. It integrates with cloud platforms like Azure ML, AWS SageMaker, and Databricks to enable deployment and management of models on those platforms.









![[AI] ML Operationalization with Microsoft Azure](https://cdn.slidesharecdn.com/ss_thumbnails/wds-mlops-trainer-kyle-akepanidtaworn-v03-190924094657-thumbnail.jpg?width=640&height=640&fit=bounds)







































































