Downloaded 32 times



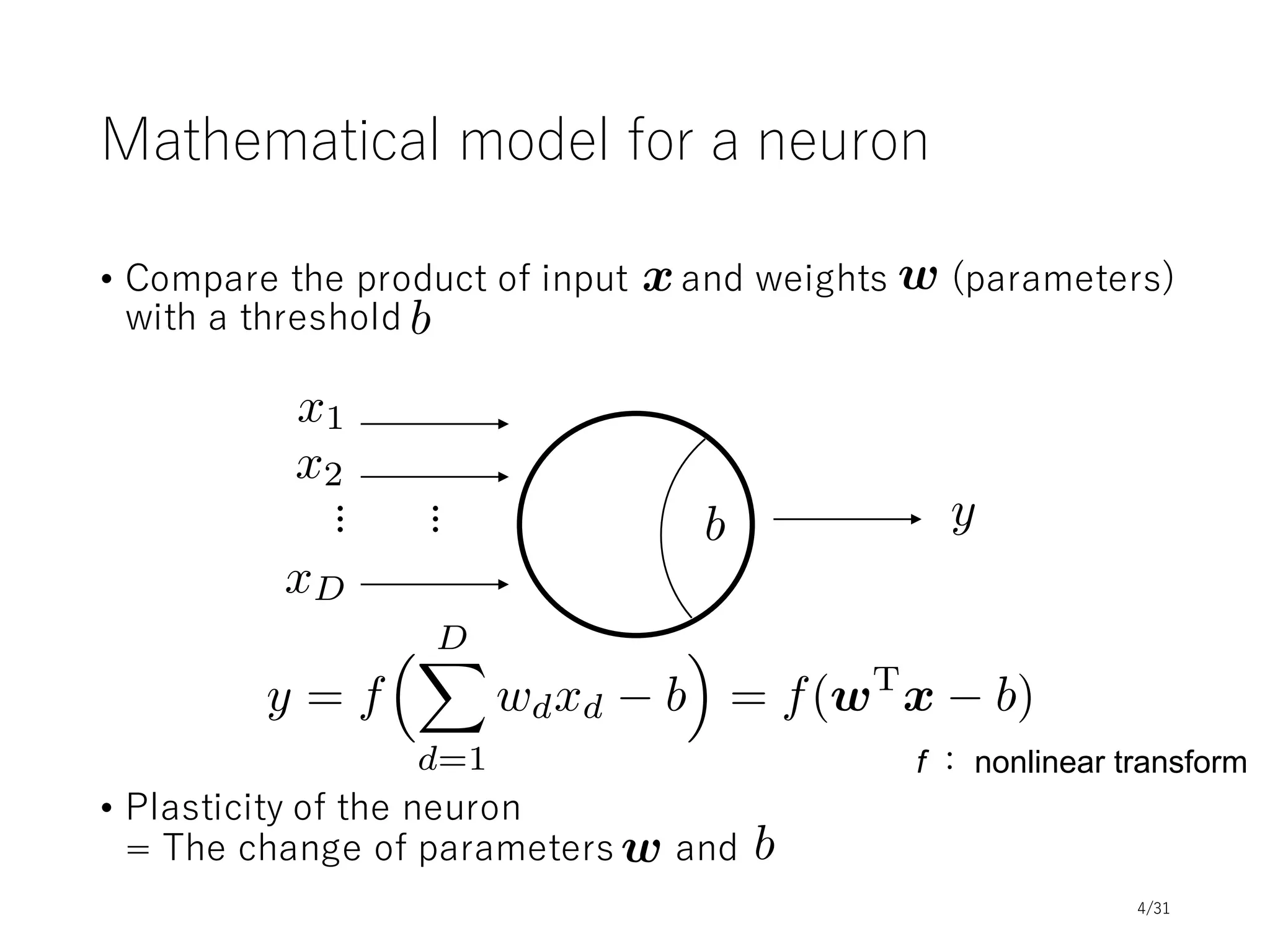






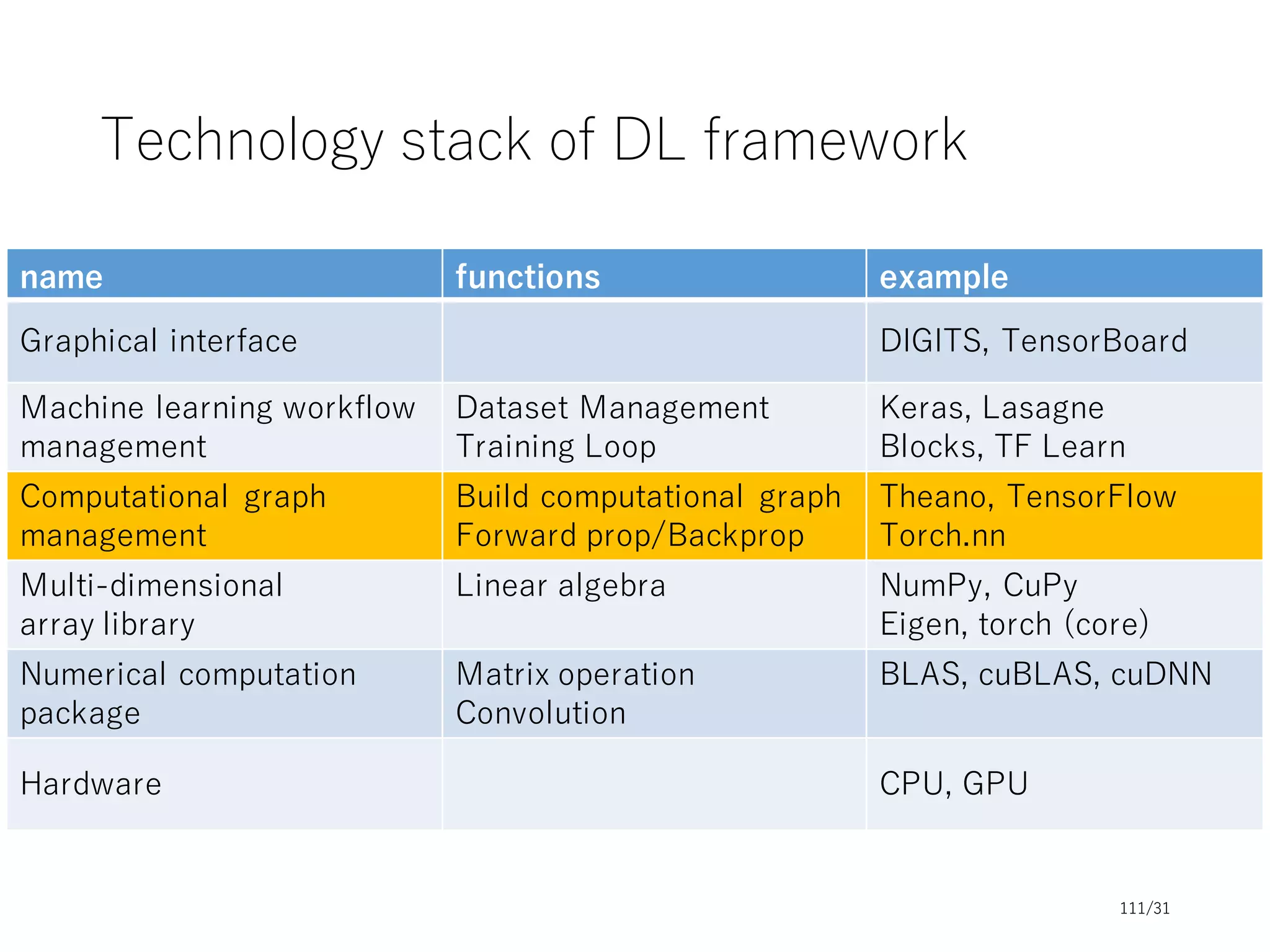
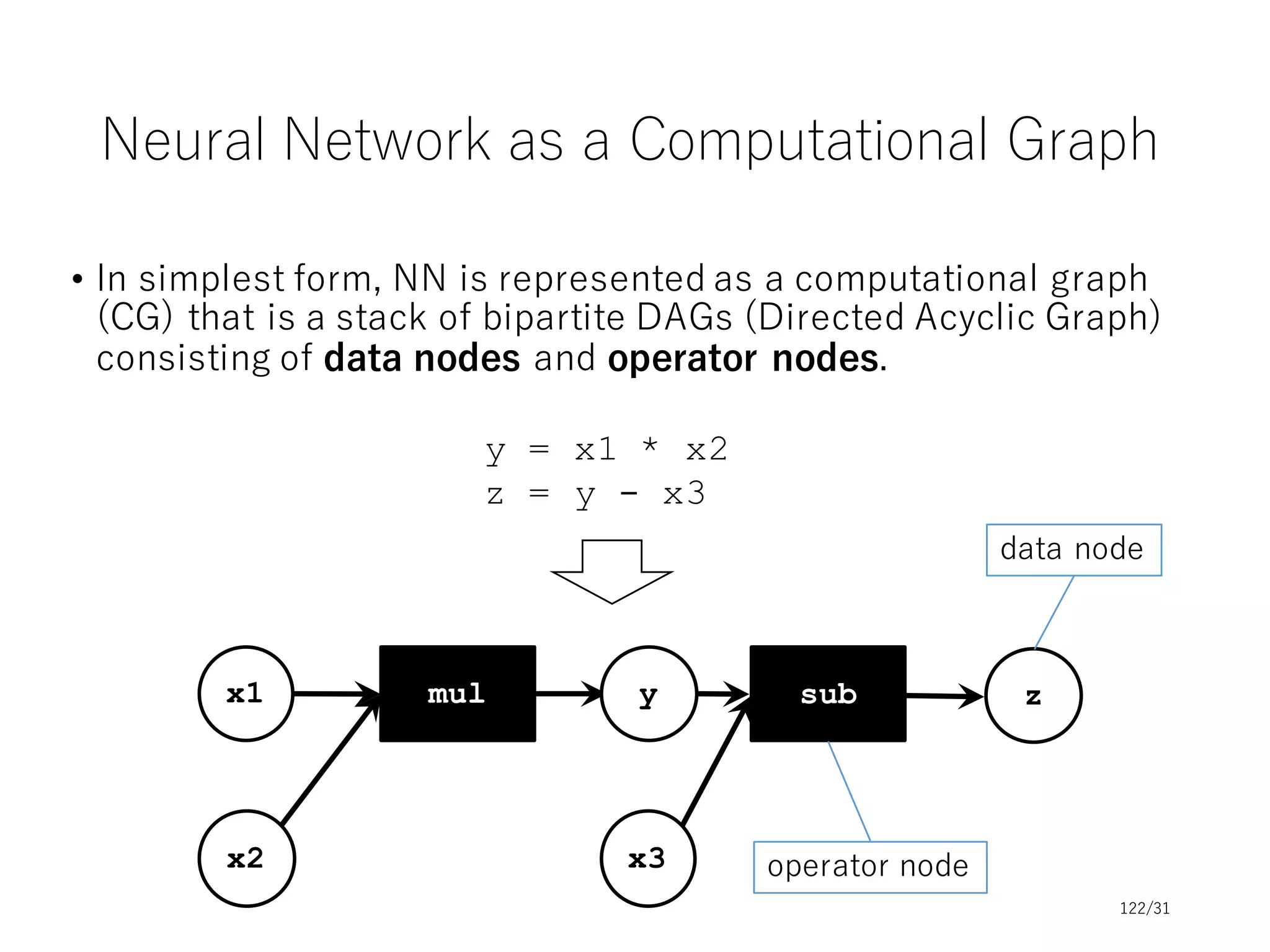



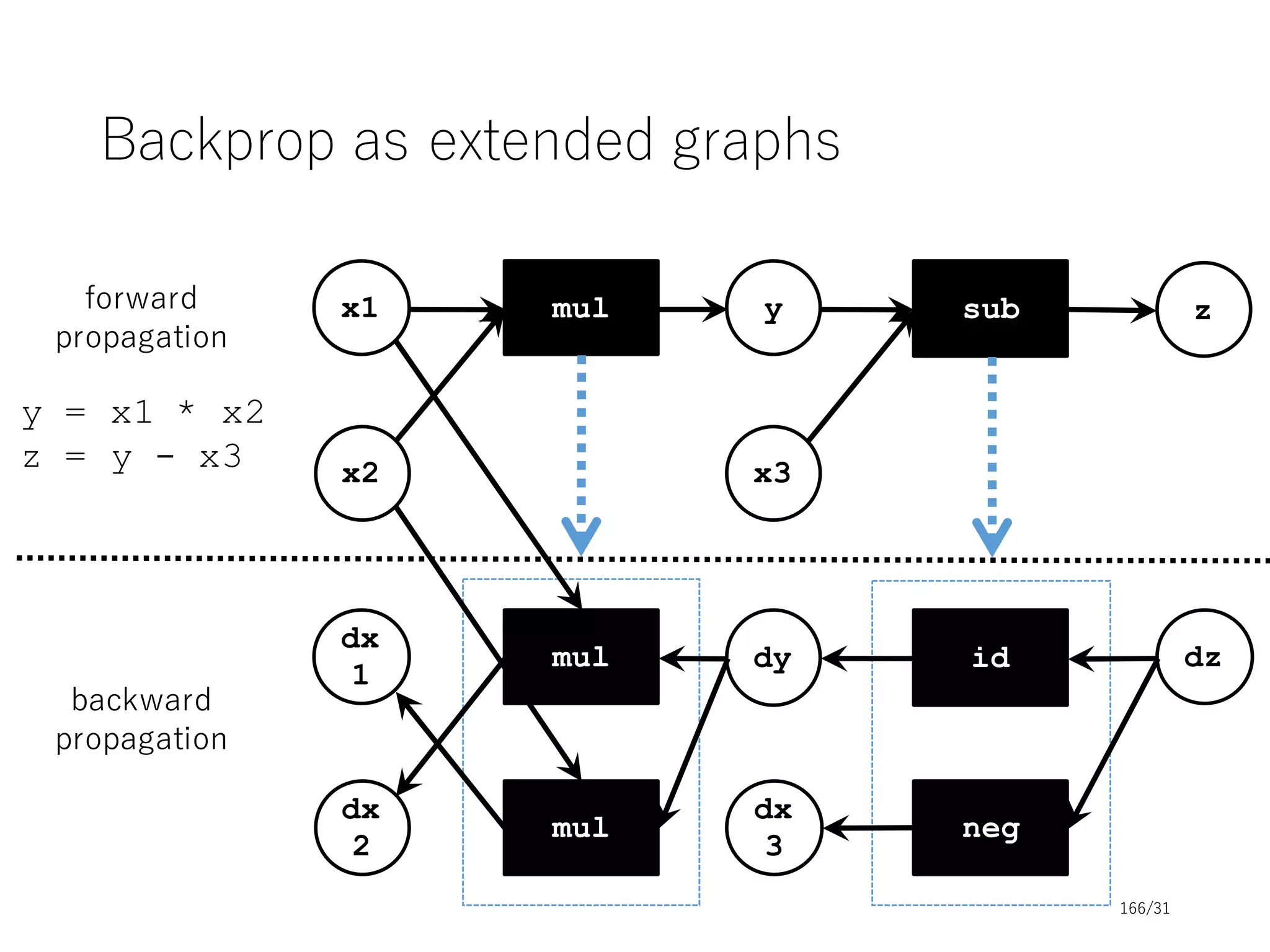














This document provides an overview and agenda for a tutorial on deep learning implementations and frameworks. The tutorial is split into two sessions. The first session will cover basics of neural networks, common design aspects of neural network implementations, and differences between deep learning frameworks. The second session will include coding examples of different frameworks and a conclusion. Slide decks and resources will be provided on topics including basics of neural networks, common design of frameworks, and differences between frameworks. The tutorial aims to introduce fundamentals of deep learning and compare popular frameworks.






















![[241]large scale search with polysemous codes](https://cdn.slidesharecdn.com/ss_thumbnails/241large-scalesearchwithpolysemouscodes-171017003327-thumbnail.jpg?width=640&height=640&fit=bounds)




















































































