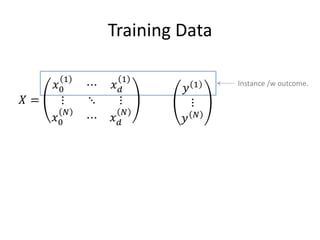
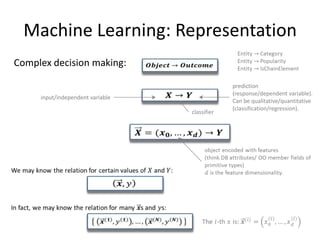
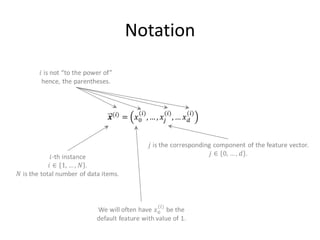
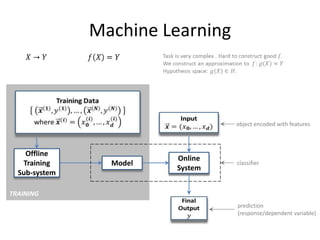
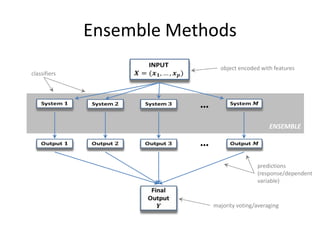
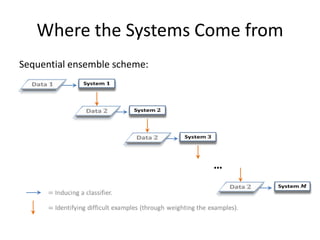
This document provides an overview of machine learning techniques including categorization, popularity, and sequence labeling applications. It outlines the goals of introducing important machine learning concepts and illustrating techniques through examples. The tutorial aims to be self-contained and explain notation. The outline includes examples of machine learning applications, encoding objects with features, the machine learning framework, linear models, tree models, boosting, ranking evaluation, and sequence labeling with hidden Markov models.






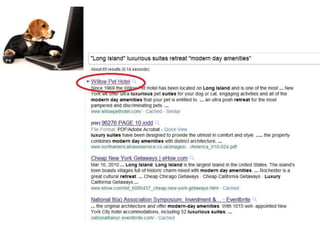
![Tokenization
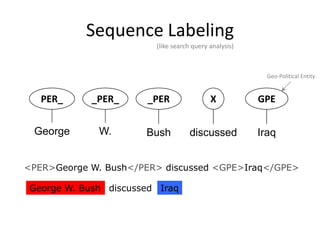
What!?I love the iphone:-)
What !? I love the iphone :-)
How difficult can that be? — 98.2% [Zhang et al. 2003]
NO TRESSPASSING
VIOLATORS WILL
BE PROSECUTED
7](https://image.slidesharecdn.com/machine-learning-120930145310-phpapp01/85/Machine-Learning-with-Applications-in-Categorization-Popularity-and-Sequence-Labeling-7-320.jpg)


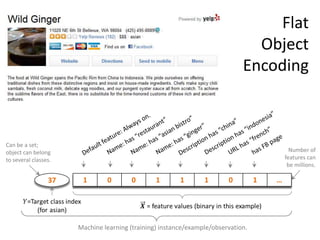
![Parts of Objects (Meronymy)
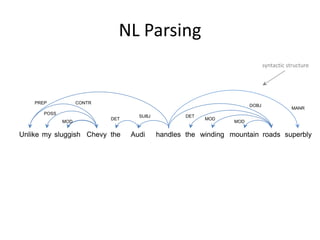
[…] the interior seems upscale with leatherette upholstery that looks and
feels better than the real cow hide found in more expensive vehicles, a
dashboard accented by textured soft-touch materials, a woven mesh
headliner, and other materials that give the New Beetle’s interior a
sense of quality. […] Finally, and a big plus in my book, both front seats were
height adjustable, and the steering column tilted and telescoped for
optimum comfort.
13](https://image.slidesharecdn.com/machine-learning-120930145310-phpapp01/85/Machine-Learning-with-Applications-in-Categorization-Popularity-and-Sequence-Labeling-13-320.jpg)






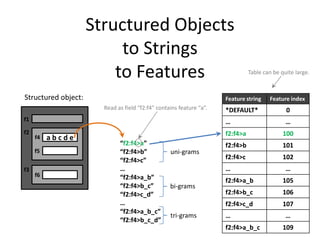
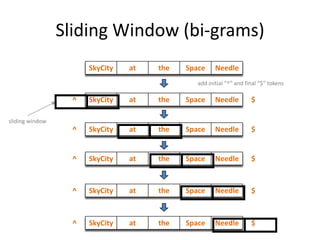
![Example: Feature Templates
public static List<string> NGrams( string field ) could add field name as argument and prefix all features
{
var featutes = new List<string>();
string[] tokens = field.Split( spaceCharArr, System.StringSplitOptions.RemoveEmptyEntries );
featutes.Add( string.Join( "", field.Split(SPLIT_CHARS) ) ); // the entire field
string unigram = string.Empty, bigram, previous1 = "^", previous2 = "^", trigram;
for (int i = 0; i < tokens.Length; i++)
{
unigram = tokens[ i ];
featutes.Add(unigram);
bigram = previous1 + "_" + unigram; initial bigram is “^_tokens*0]"
featutes.Add( bigram );
if ( i >= 1 ) { trigram = previous2 + "_" + bigram; featutes.Add( trigram ); }
previous2 = previous1;
initial tri-gram is: "^_tokens[0]_tokens[1] "
previous1 = unigram;
}
featutes.Add( unigram + "_$" );
featutes.Add( bigram + "_$" ); last trigram is “tokens*tokens.Length-2]_tokens[tokens.Length-1]_$"
return result;
24
}](https://image.slidesharecdn.com/machine-learning-120930145310-phpapp01/85/Machine-Learning-with-Applications-in-Categorization-Popularity-and-Sequence-Labeling-24-320.jpg)

![Generic Nature of ML Systems
human sees
Indices of (binary) features that trigger.
instance( class= 7, features=[0,300857,100739,200441,...])
computer “sees” instance( class=99, features=[0,201937,196121,345758,13,...])
instance( class=42, features=[0,99173,358387,1001,1,...])
...
Number of features that trigger for individual
instances are often not the same. 26
Default feature always triggers.](https://image.slidesharecdn.com/machine-learning-120930145310-phpapp01/85/Machine-Learning-with-Applications-in-Categorization-Popularity-and-Sequence-Labeling-26-320.jpg)






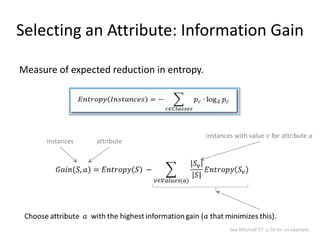
![Chi Square Feature Selection
int[] featureCounts = new int[ numFeatures ];
int numLabels = labelIndex.Count;
int[] classTotals = new int[ numLabels ]; // instances with that label.
float[] classPriors = new float[ numLabels ]; // class priors: classTotals[label]/numInstances.
int[,] counts = new int[ numLabels, numFeatures ]; // (label,feature) co-occurrence counts.
int numInstances = instances.Count;
... Do a pass over the data and collect above counts.
float[] weightedChiSquareScore = new float[ numFeatures ];
for (int f = 0; f < numFeatures; f++) // f is a feature index
{
float score = 0.0f;
for (int labelIdx = 0; labelIdx < numLabels; labelIdx++)
{
int a = counts[ labelIdx, f ];
int b = classTotals[ labelIdx ] - p;
int c = featureCounts[ f ] - p;
int d = numInstances - ( p + q + r );
if (p >= MIN_SUPPORT && q >= MIN_SUPPORT) { // MIN_SUPPORT = 5
score += classPriors[ labelIdx ] * Chi2( a, b, c, d );
}
}
Weighted average across all classes.
weightedChiSquareScore[ f ] = score;
} 34](https://image.slidesharecdn.com/machine-learning-120930145310-phpapp01/85/Machine-Learning-with-Applications-in-Categorization-Popularity-and-Sequence-Labeling-34-320.jpg)





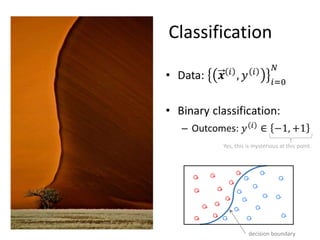







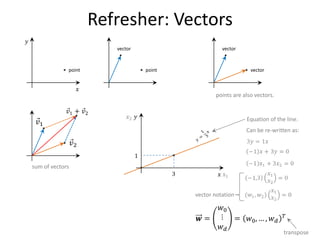
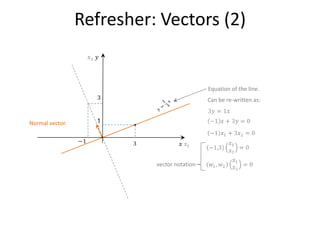
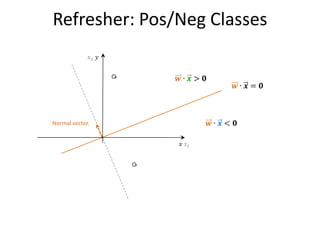
![Definitions
Sensitivity & Specificity
TN: true negatives
FP: false positives
[same as recall;
TP: aka true positive rate]
true positives
FN: false negatives
[aka true negative rate]
False positive rate: False negative rate:
55](https://image.slidesharecdn.com/machine-learning-120930145310-phpapp01/85/Machine-Learning-with-Applications-in-Categorization-Popularity-and-Sequence-Labeling-55-320.jpg)






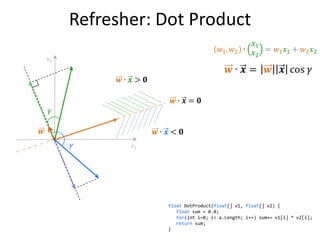
![Refresher: Dot Product
float DotProduct(float[] v1, float[] v2) {
float sum = 0.0;
for(int i=0; i< a.Length; i++) sum+= v1[i] * v2[i];
return sum;
} 63](https://image.slidesharecdn.com/machine-learning-120930145310-phpapp01/85/Machine-Learning-with-Applications-in-Categorization-Popularity-and-Sequence-Labeling-63-320.jpg)



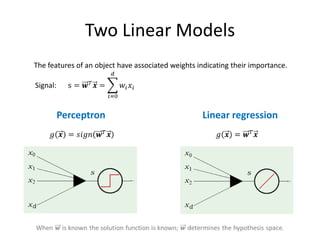
![Why “Regression”?
Why the term for quantitative output prediction is “regression”?
“That same year [1875], [Francis] Galton decided to recruit some of his friends for an experiment with
sweet peas. He distributed seeds among seven of them, asking them to plant the seeds and return the
offspring. Galton measured the baby seeds and compared their diameters to those of their parents. He
noticed a phenomenon that initially seems counter-intuitive: the large seeds tended to produce smaller
offspring, and the small seeds tended to produce larger offspring. A decade later he analyzed data from his
anthropometric laboratory and recognized the same pattern with human heights. After measuring 205
pairs of parents and their 928 adult children, he saw that exceptionally tall parents had kids who were
generally shorter than they were, while exceptionally short parents had children who were generally taller
than their parents.
After reflecting upon this, we can understand why it must be the case. If very tall parents always produced
even taller children, and if very short parents always produced even shorter ones, we would by now have
turned into a race of giants and midgets. Yet this hasn't happened. Human populations may be getting
taller as a whole – due to better nutrition and public health – but the distribution of heights within the
population is still contained.
Galton called this phenomenon ‘regression towards mediocrity in hereditary stature’. The concept is now
more generally known as regression to the mean.”
[A.Bellos pp.375]
67](https://image.slidesharecdn.com/machine-learning-120930145310-phpapp01/85/Machine-Learning-with-Applications-in-Categorization-Popularity-and-Sequence-Labeling-67-320.jpg)

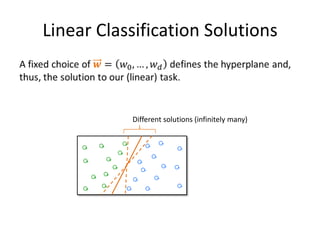


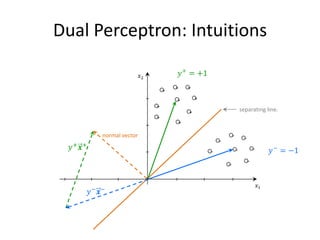

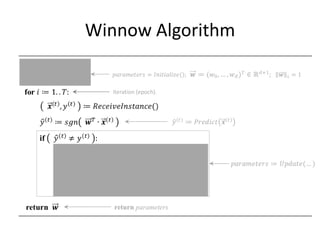

![Compact Model Representation
Use float instead of double:
Store only non-zero weights (and indices):
Store non-zero weights and diff of indices:
void Save( StreamWriter w, int labelIdx, float[] weights )
{
w.Write( labelIdx );
int previousIndex = 0;
for (int i = 0; i < weights.Length; i++) Difference of indices.
{
if (weights[ i ] != 0.0f) {
w.Write( " " + (i - previousIndex) + " " + weights[ i ] );
previousIndex = i;
}
}
Remember last index where the weight was non-zero .
}
78](https://image.slidesharecdn.com/machine-learning-120930145310-phpapp01/85/Machine-Learning-with-Applications-in-Categorization-Popularity-and-Sequence-Labeling-78-320.jpg)
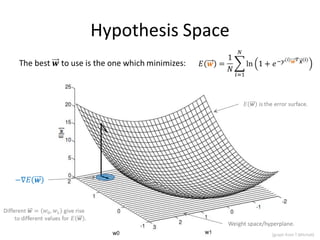









![Hypothesis Space
Weight space/hyperplane.
91
[graph from T.Mitchell]](https://image.slidesharecdn.com/machine-learning-120930145310-phpapp01/85/Machine-Learning-with-Applications-in-Categorization-Popularity-and-Sequence-Labeling-91-320.jpg)


















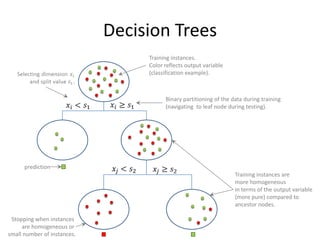
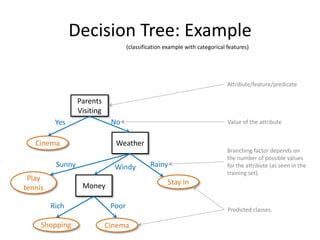
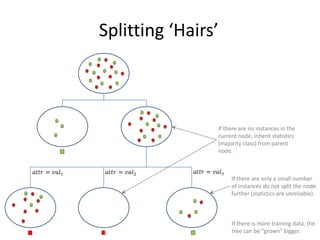



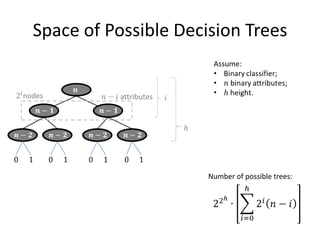
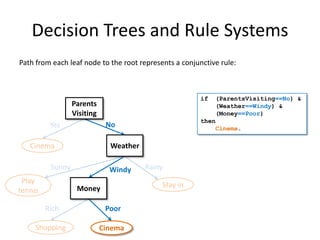

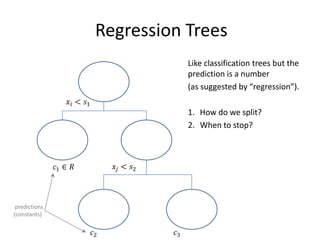
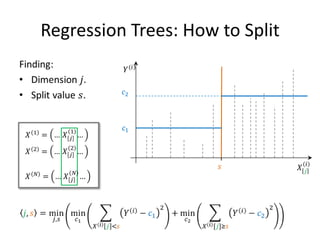
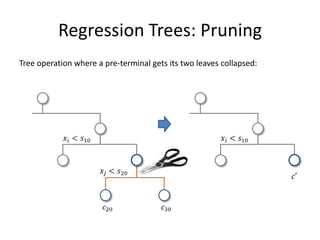



![Alternative Attribute Selection:
Gain Ratio [Quinlan 1986]
instances attribute
Examples:
all different values.
130](https://image.slidesharecdn.com/machine-learning-120930145310-phpapp01/85/Machine-Learning-with-Applications-in-Categorization-Popularity-and-Sequence-Labeling-130-320.jpg)
![Alternative Attribute Selection:
GINI Index [Corrado Gini: Italian statistician]
131](https://image.slidesharecdn.com/machine-learning-120930145310-phpapp01/85/Machine-Learning-with-Applications-in-Categorization-Popularity-and-Sequence-Labeling-131-320.jpg)
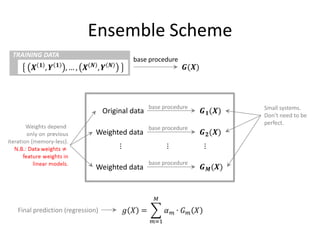

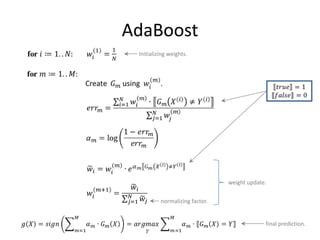





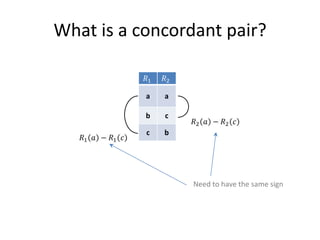
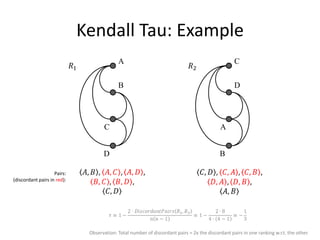

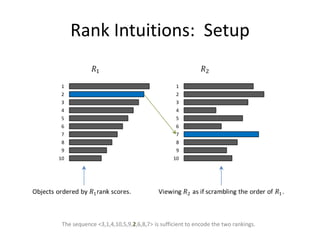
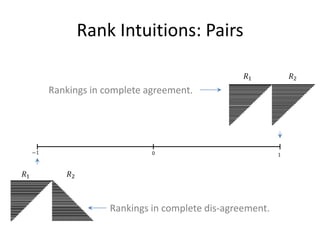
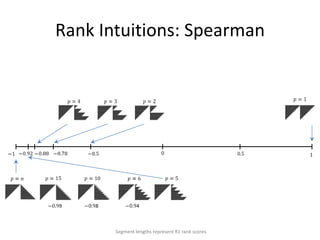
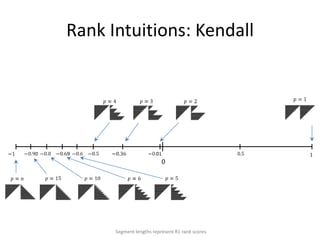

![Binary Classifier
• Constraint:
– Must not have all zero clicks for current week, previous week and week before last
[shopping team uses stronger constraint: only instances with non-zero clicks for
current week].
• Training:
– 1.5M instances.
– 0.5M instances (validation).
• Feature extraction:
– 4.82mins (Cosmos job).
• Training time:
– 2hrs 20mins.
• Testing:
– 10k instances: 1sec.
148](https://image.slidesharecdn.com/machine-learning-120930145310-phpapp01/85/Machine-Learning-with-Applications-in-Categorization-Popularity-and-Sequence-Labeling-148-320.jpg)












![References
1. Yaser S. Abu-Mostafa, Malik Magdon-Ismail & Hsuan-Tien Lin (2012) Learning From Data. AMLBook. [link]
2. Ethem Alpaydin (2009) Introduction to Machine Learning. 2nd edition. Adaptive Computation and Machine Learning series. MIT Press.
[link]
3. David Barber (2012) Bayesian Reasoning and Machine Learning. Cambridge University Press. [link]
4. Ricardo Baeza-Yates & Berthier Ribeiro-Neto (2011) Modern Information Retrieval: The Concepts and Technology behind Search. 2nd
Edition. ACM Press Books. [link]
5. Alex Bellos (2010) Alex's Adventures in Numberland. Bloomsbury: New York. [link]
6. Ron Bekkerman, Mikhail Bilenko & John Langford (2011) Scaling up Machine Learning: Parallel and Distributed Approaches. Cambridge
University Press. [link]
7. Christopher M. Bishop (2007) Pattern Recognition and Machine Learning. Information Science and Statistics. Springer. [link]
8. George Casella & Roger L. Berger (2001) Statistical Inference. 2nd edition. Duxbury Press. [link]
9. Anirban DasGupta (2011) Probability for Statistics and Machine Learning: Fundamentals and Advanced Topics. Springer Texts in Statistics.
Springer. [link]
10. Luc Devroye, László Györfi & Gábor Lugosi (1996) A Probabilistic Theory of Pattern Recognition. Springer. [link]
11. Richard O. Duda, Peter E. Hart & David G. Stork (2000) Pattern Classification. 2nd Edition. Wiley-Interscience. [link]
12. Trevor Hastie, Robert Tibshirani & Jerome Friedman (2009) The Elements of Statistical Learning: Data Mining, Inference, and Prediction.
2nd Edition. Springer Series in Statistics. Springer. [link]
13. James L. Johnson (2008) Probability and Statistics for Computer Science. Wiley-Interscience. [link]
14. Daphne Koller & Nir Friedman (2009) Probabilistic Graphical Models: Principles and Techniques. Adaptive Computation and Machine
Learning series. MIT Press. [link]
15. David J. C. MacKay (2003) Information Theory, Inference and Learning Algorithms. Cambridge University Press. [link]
16. Zbigniew Michalewicz & David B. Fogel (2004) How to Solve It: Modern Heuristics. 2nd edition. Springer. [link]
17. Tom M. Mitchell (1997) Machine Learning. McGraw-Hill (Science/Engineering/Math). [link]
18. Mehryar Mohri, Afshin Rostamizadeh & Ameet Talwalkar (2012) Foundations of Machine Learning. Adaptive Computation and Machine
Learning series. MIT Press. [link]
19. Lior Rokach (2010) Pattern Classification Using Ensemble Methods. World Scientific. [link]
20. Gilbert Strang (1991) Calculus. Wellesley-Cambridge Press. [link]
21. Larry Wasserman (2010) All of Statistics: A Concise Course in Statistical Inference. Springer Texts in Statistics. Springer. [link]
22. Sholom M. Weiss, Nitin Indurkhya & Tong Zhang (2010) Fundamentals of Predictive Text Mining. Texts in Computer Science. Springer. [link]
165](https://image.slidesharecdn.com/machine-learning-120930145310-phpapp01/85/Machine-Learning-with-Applications-in-Categorization-Popularity-and-Sequence-Labeling-165-320.jpg)







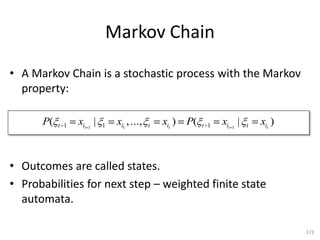
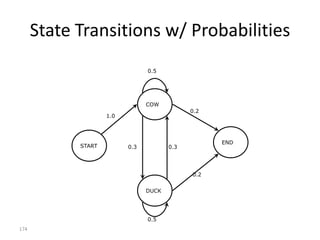


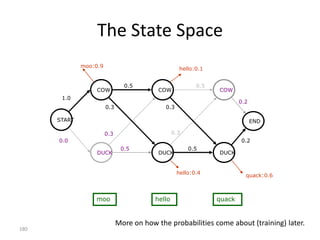







![Markov Model
Finite set of states:
{s1,..., sm}
Signal alphabet:
{ 1,..., k }
Transition matrix:
P [ pij ] where pij P( t 1 sj | t si )
Emission probabilities:
A [aij ] where aij P( t j | t si )
Initial probability vector:
v [v1 ,..., vm ] where v j P( 1 sj)
190](https://image.slidesharecdn.com/machine-learning-120930145310-phpapp01/85/Machine-Learning-with-Applications-in-Categorization-Popularity-and-Sequence-Labeling-190-320.jpg)





![Viterbi (cont)
Note:
1 (i ) vi aik 1 where vi P( 1 si ) and aik 1 P( t k1 | t si )
We will show that:
t ( j ) [max t 1 (i) pij ] a jk t
i
196](https://image.slidesharecdn.com/machine-learning-120930145310-phpapp01/85/Machine-Learning-with-Applications-in-Categorization-Popularity-and-Sequence-Labeling-196-320.jpg)
![Recurrence Equation
t ( j) max P ( S t 1 , t s j ;O t )
S t 1
max max P ( S t 2 , t 1 si , t s j ;O t 1 , t kt )
i S t 2
max max P ( t sj; t kt |S t 2 , t 1 si ; O t 1 )
i S t 2
k1
P( S t 2 , t 1 si ; O t 1 )
max max P ( t sj | t 1 si ) P ( t kt | t sj)
i S t 2
P( S t 2 , t 1 si ; O t 1 )
[max P ( t sj | t 1 si ) max P ( S t 2 , t 1 si ; O t )]
1
i S t 2
P( t kt | t sj)
[max pij t 1 (i )] a jk t
i
197](https://image.slidesharecdn.com/machine-learning-120930145310-phpapp01/85/Machine-Learning-with-Applications-in-Categorization-Popularity-and-Sequence-Labeling-197-320.jpg)

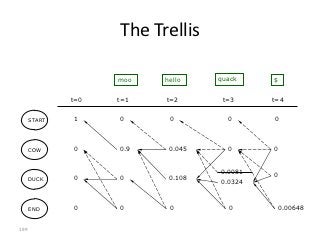
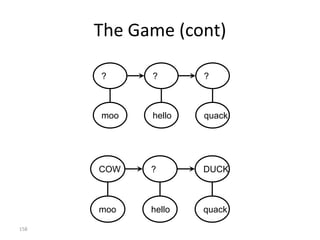
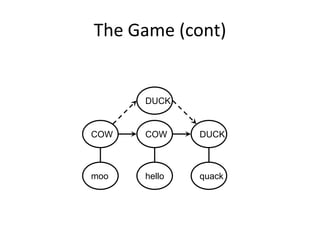
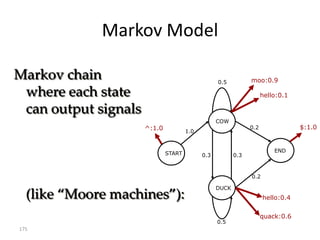
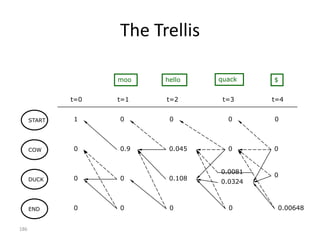
![Implementation (Python)
observations = ['^','moo','hello','quack','$'] # signal sequence
states = ['start','cow','duck','end']
# Transition probabilities - p[FromState][ToState] = probability
p = {'start': {'cow':1.0},
'cow': {'cow' :0.5,
'duck':0.3,
'end' :0.2},
'duck': {'duck':0.5,
'cow' :0.3,
'end' :0.2}}
# Emission probabilities; special emission symbol '$' for 'end' state
a = {'cow' : {'moo' :0.9,'hello':0.1, 'quack':0.0, '$':0.0},
'duck': {'moo' :0.0,'hello':0.4, 'quack':0.6, '$':0.0},
'end' : {'moo' :0.0,'hello':0.0, 'quack':0.0, '$':1.0}}
200](https://image.slidesharecdn.com/machine-learning-120930145310-phpapp01/85/Machine-Learning-with-Applications-in-Categorization-Popularity-and-Sequence-Labeling-200-320.jpg)
![Implementation (Viterbi)
n = len(observations)
# Initializing viterbi table row by row; v[state][time] = prob
v = {}; for s in states: v[s] = [0.0] * T
# Initializing back pointers
backPointer = {}; for s in states: backPointer[s] = [""] * T
v['start'][0] = 1.0
for t in range(T-1): # t =[0..T-1]; populate column t+1 in v
for s in states[:-1]: # 'end' state not considered
# only consider 'start' state at time 0
if t == 0 and s != 'start': continue
for s1 in p[s].keys(): # s1 is the next state
newScore = v[s][t] * p[s][s1] * a[s1][observations[t+1]]
if v[s1][t+1] == 0.0 or newScore > v[s1][t+1]:
v[s1][t+1] = newScore
backPointer[s1][t+1] = s
201](https://image.slidesharecdn.com/machine-learning-120930145310-phpapp01/85/Machine-Learning-with-Applications-in-Categorization-Popularity-and-Sequence-Labeling-201-320.jpg)
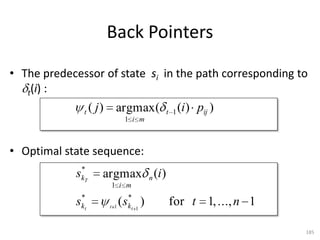
![Implementation (Best Path)
# Now recover the optimal state sequence
state_sequence = [ 'end' ]
for t in range( n-1, 0, -1 ):
state = backPointer[ state ][ t ]
state_sequence = [ state ] + state_sequence
print "Observations....: ", observations
print "Optimal sequence: ", state_sequence
202](https://image.slidesharecdn.com/machine-learning-120930145310-phpapp01/85/Machine-Learning-with-Applications-in-Categorization-Popularity-and-Sequence-Labeling-202-320.jpg)












![SSII2022 [TS2] 自律移動ロボットのためのロボットビジョン〜 オープンソースの自動運転ソフトAutowareを解説 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts2ssii2022r4-220607054405-1c6b5fc2-thumbnail.jpg?width=640&height=640&fit=bounds)




![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DL輪読会]"CyCADA: Cycle-Consistent Adversarial Domain Adaptation"&"Learning Se...](https://cdn.slidesharecdn.com/ss_thumbnails/20180803dlakuzawa-180803003349-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]MUTAN: Multimodal Tucker Fusion for Visual Question Answering](https://cdn.slidesharecdn.com/ss_thumbnails/dlreadingyokota20171222-171222003255-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Learning to Generalize: Meta-Learning for Domain Generalization](https://cdn.slidesharecdn.com/ss_thumbnails/20180208-180209000942-thumbnail.jpg?width=640&height=640&fit=bounds)






























































