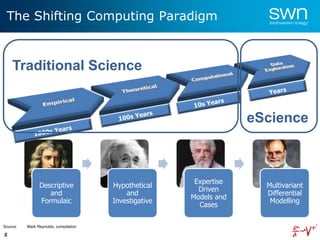
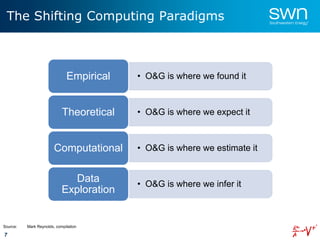
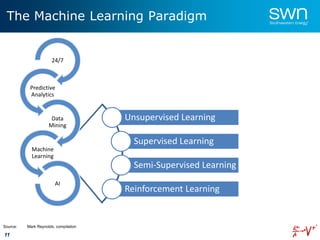
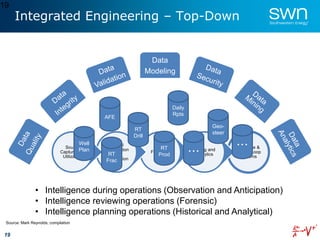
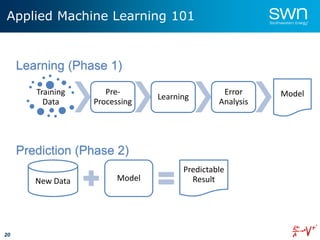
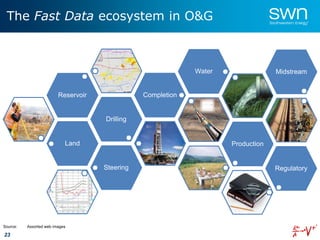
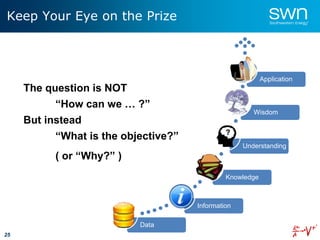
The document outlines a roadmap for implementing machine learning in the oil and gas industry, focusing on the transition to a top-down integrated systems engineering approach to enhance operational efficiencies and recovery. It discusses various machine learning paradigms including supervised, unsupervised, and reinforcement learning, as well as the implications of big data in the sector. Additionally, it emphasizes the significance of data quality and the importance of developing predictive analytics and data mining solutions.













![22
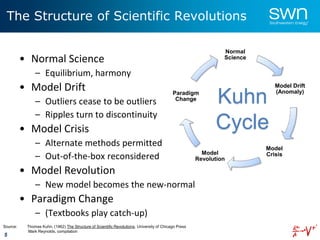
Machine Learning: Data Diversity
• Macro (or field-level)
– Spatial
– Temporal
• Pad (or offset)
– Spatial
– Temporal
• Well (or wellbore)
– Spatial
– Temporal
• External
– Uploads
– Political, Climate, etc
• The 3 Cs of Data Quality
– Consistency
– Correctness
– Completeness
– [#4] Currency
– [#5] Conformity
Source: Mark Reynolds, compilation
Data Diversity - Spatial, Temporal, Referential](https://image.slidesharecdn.com/2016-04-19machinelearning-160807111804/85/2016-04-19-machine-learning-23-320.jpg)









![Data Analytics Life Cycle [EMC² - Data Science and Big data analytics]](https://cdn.slidesharecdn.com/ss_thumbnails/bdalifecycle-slideshare-211028070344-thumbnail.jpg?width=640&height=640&fit=bounds)







































































