Downloaded 39 times





![15
from sklearn.datasets import make_moons
import pandas
X, y = make_moons(n_samples=int(1e2),
noise=0.05, random_state=0)
X = pandas.DataFrame({'fea%d'%i: X[:, i]
for i in range(X.shape[1])})
from sklearn.cluster import DBSCAN
dbscan = DBSCAN(eps = 0.3, min_samples = 5)
dbscan.fit(X)
y_hat = dbscan.predict(X)
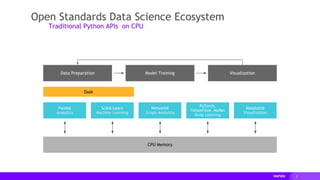
RAPIDS Matches Common Python APIs
CPU-accelerated Clustering](https://image.slidesharecdn.com/databricksmeetuprapids-200930221351/85/Accelerated-Machine-Learning-with-RAPIDS-and-MLflow-Nvidia-RAPIDS-15-320.jpg)
![16
from sklearn.datasets import make_moons
import cudf
X, y = make_moons(n_samples=int(1e2),
noise=0.05, random_state=0)
X = cudf.DataFrame({'fea%d'%i: X[:, i]
for i in range(X.shape[1])})
from cuml import DBSCAN
dbscan = DBSCAN(eps = 0.3, min_samples = 5)
dbscan.fit(X)
y_hat = dbscan.predict(X)
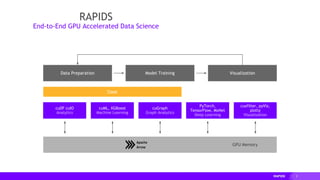
RAPIDS Matches Common Python APIs
GPU-accelerated Clustering](https://image.slidesharecdn.com/databricksmeetuprapids-200930221351/85/Accelerated-Machine-Learning-with-RAPIDS-and-MLflow-Nvidia-RAPIDS-16-320.jpg)



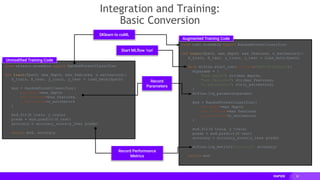
![31
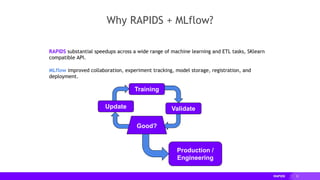
Integration:
Nesting+HPO and Model Logging
hpo_runner = HPO_Runner(hpo_train)
with mlflow.start_run(run_name=f"RAPIDS-HPO", nested=True):
search_space = [
uniform("max_depth", 5, 20),
uniform("max_features", 0.1, 1.0),
uniform("n_estimators", 150, 1000),
]
hpo_results = hpo_runner(fpath, search_space)
artifact_path = "rapids-mlflow-example"
with mlflow.start_run(run_name='Final Classifier', nested=True):
mlflow.sklearn.log_model(hpo_results.best_model,
artifact_path=artifact_path,
registered_model_name="rapids-mlflow-example",
conda_env='conda/conda.yaml')
from cuml.ensemble import RandomForestClassifier
from your_hpo_library import HPO_Runner
# Called by hpo_runner
def hpo_train(params):
X_train, X_test, y_train, y_test = load_data(params.fpath)
with mlflow.start_run(run_name=f”Trial {params.trail}",
nested=True):
mod = RandomForestClassifier(
max_depth=params.max_depth,
max_features=params.max_features,
n_estimators=params.n_estimators
)
mod.fit(X_train, y_train)
preds = mod.predict(X_test)
accuracy = accuracy_score(y_test, preds
return mod, accuracy
Add HPO Runner
Log Runs and Best Model
Import our HPO library
Update Nested Training
Register Best Result](https://image.slidesharecdn.com/databricksmeetuprapids-200930221351/85/Accelerated-Machine-Learning-with-RAPIDS-and-MLflow-Nvidia-RAPIDS-31-320.jpg)
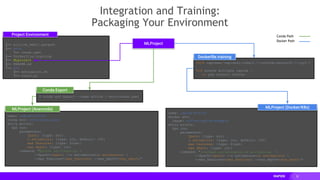


![35
Model Deployment
$ mlflow models serve -m models:/rapids_mlflow_cli/1 -p 56767
2020/09/24 18:05:26 INFO mlflow.models.cli: Selected backend for flavor 'python_function'
2020/09/24 18:05:26 INFO mlflow.pyfunc.backend: === Running command 'gunicorn --timeout=60 -b 127.0.0.1:56767 -w 1 ${GUNICORN_CMD_ARGS} --
mlflow.pyfunc.scoring_server.wsgi:app'
[2020-09-24 18:05:26 -0600] [17024] [INFO] Starting gunicorn 20.0.4
[2020-09-24 18:05:26 -0600] [17024] [INFO] Listening at: http://127.0.0.1:56767 (17024)
[2020-09-24 18:05:26 -0600] [17024] [INFO] Using worker: sync
[2020-09-24 18:05:26 -0600] [17026] [INFO] Booting worker with pid: 17026
[2020-09-24 18:05:28 -0600] [17024] [INFO] Handling signal: winch
Registered Model
Anaconda
This can also be a storage path.
Query Request
Docker Serving (Experimental)
$ mlflow models build-docker -m models:/rapids_mlflow_cli/9 -n mlflow-rapids-example
2020/09/24 16:43:18 INFO mlflow.models.cli: Selected backend for flavor 'python_function'
2020/09/24 16:43:18 INFO mlflow.models.docker_utils: Building docker image with name mlflow-rapids-example
…. build process ….
Successfully built 900f8e84b370
Successfully tagged mlflow-rapids-example:latest
$
Registered Model
EXPERIM
ENTAL](https://image.slidesharecdn.com/databricksmeetuprapids-200930221351/85/Accelerated-Machine-Learning-with-RAPIDS-and-MLflow-Nvidia-RAPIDS-35-320.jpg)
![36
Endpoint Inference
import json
import requests
host = 'localhost'
port = '56767'
headers = {
"Content-Type": "application/json",
"format": "pandas-split"
}
data = {
"columns": ["Year", "Month", "DayofMonth", "DayofWeek", "CRSDepTime",
"CRSArrTime", "UniqueCarrier",
"FlightNum", "ActualElapsedTime", "Origin", "Dest", "Distance",
"Diverted"],
"data": [[1987, 10, 1, 4, 1, 556, 0, 190, 247, 202, 162, 1846, 0]]
}
resp = requests.post(url="http://%s:%s/invocations" % (host, port),
data=json.dumps(data), headers=headers)
print('Classification: %s' % ("ON-Time" if resp.text == "[0.0]" else "LATE"))
test_query.py
$ python src/rf_test/test_query.py
Classification: ON-Time
Shell](https://image.slidesharecdn.com/databricksmeetuprapids-200930221351/85/Accelerated-Machine-Learning-with-RAPIDS-and-MLflow-Nvidia-RAPIDS-36-320.jpg)



The document discusses the integration of RAPIDS and MLflow for accelerating machine learning workflows, focusing on data preparation, model training, and deployment using GPU-accelerated tools. It highlights the benefits of using RAPIDS for ETL processes, achieving significant performance improvements compared to CPU-based methods, while MLflow enhances collaboration, experiment tracking, and model management. Various examples and benchmarks illustrate the effective use of these technologies together, showcasing their capabilities in handling large datasets and improving training times.























































































