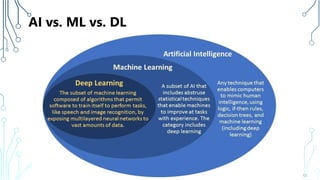
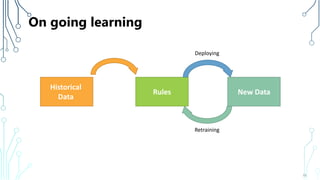
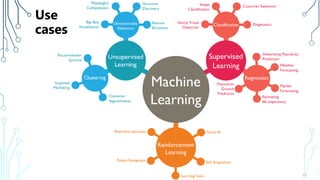
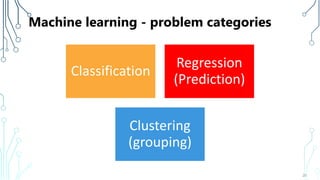
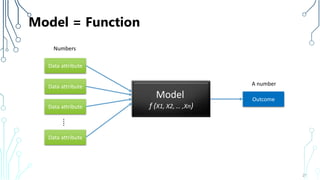
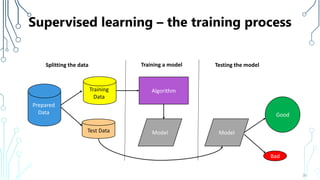
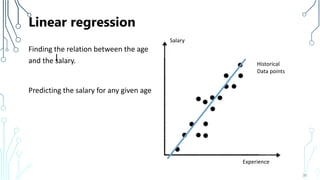
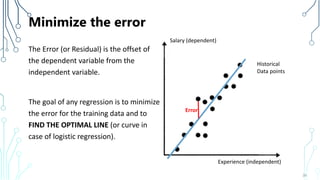
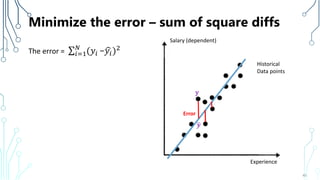
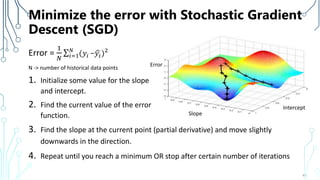
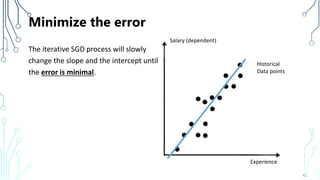
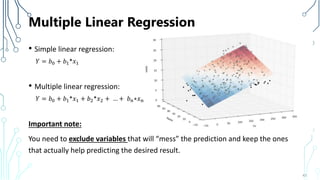
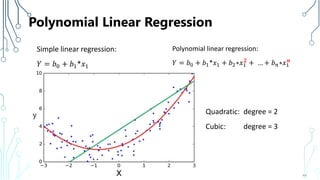
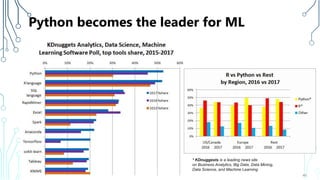
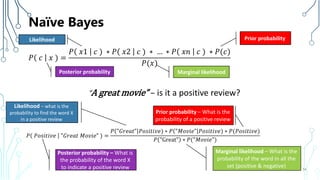
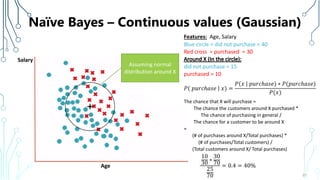
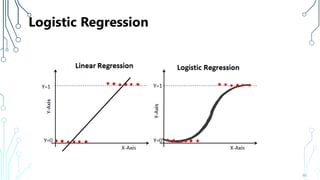
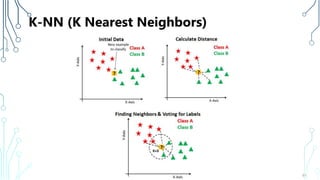
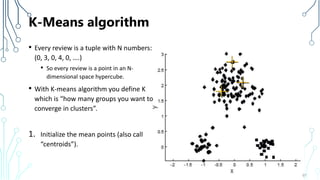
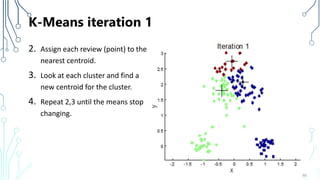
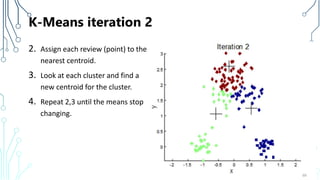
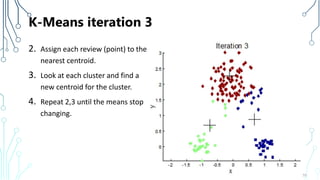
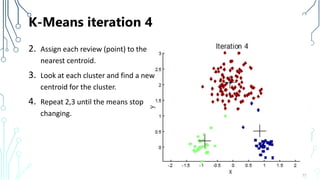
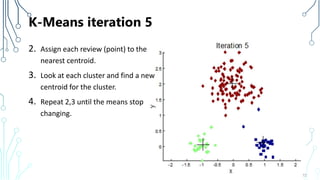
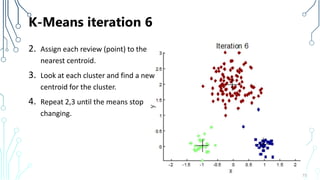
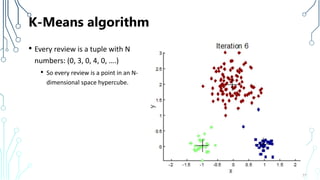
The document provides an introduction to machine learning (ML), covering its definitions, essential algorithms, and practical applications using Python and libraries like Scikit-learn and TensorFlow. It discusses various ML techniques including supervised, unsupervised, and reinforcement learning, as well as algorithm examples such as linear regression, Naive Bayes, and k-means clustering. Additionally, it highlights the importance of data in the ML process, challenges faced, and solutions offered by advancements in technology.