Download to read offline








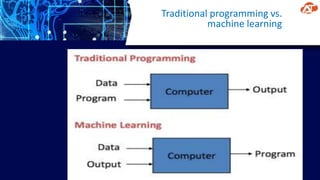











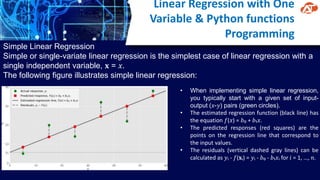













This document provides an overview of machine learning concepts and techniques including linear regression, logistic regression, unsupervised learning, and k-means clustering. It discusses how machine learning involves using data to train models that can then be used to make predictions on new data. Key machine learning types covered are supervised learning (regression, classification), unsupervised learning (clustering), and reinforcement learning. Example machine learning applications are also mentioned such as spam filtering, recommender systems, and autonomous vehicles.









































































