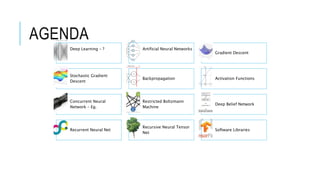
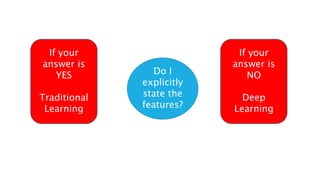
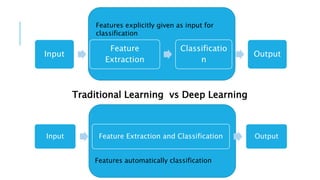
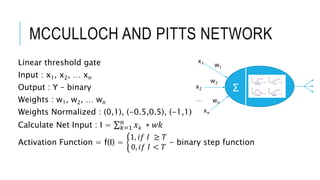
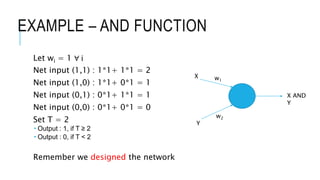
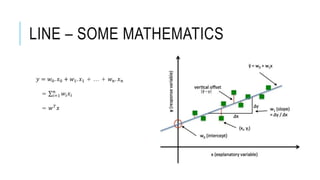
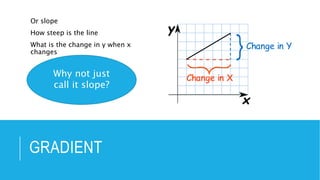
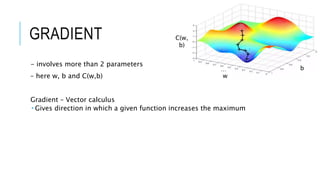
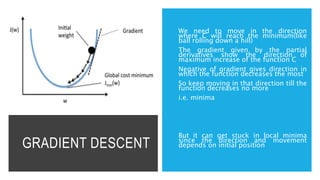
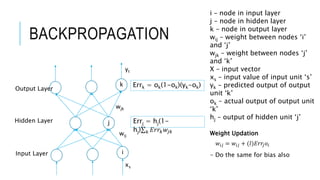
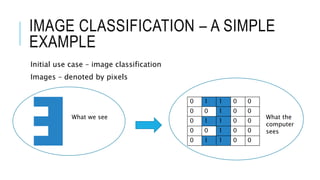
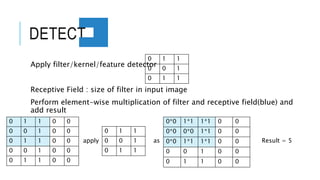
The document discusses deep learning and artificial neural networks. It provides an agenda for topics covered, including gradient descent, backpropagation, activation functions, and examples of neural network architectures like convolutional neural networks. It explains concepts like how neural networks learn patterns from data using techniques like stochastic gradient descent to minimize loss functions. Deep learning requires large amounts of processing power and labeled training data. Common deep learning networks are used for tasks like image recognition, object detection, and time series analysis.





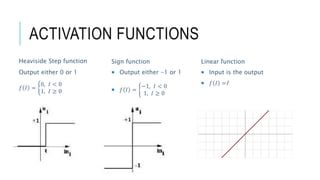
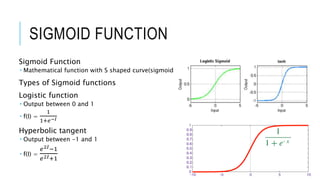
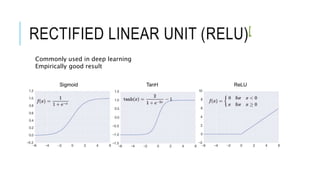
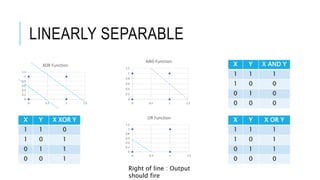


















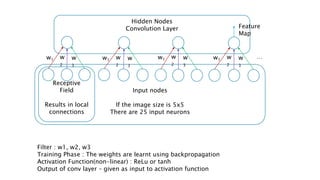

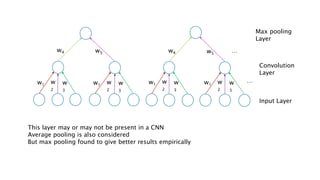




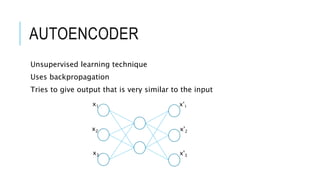

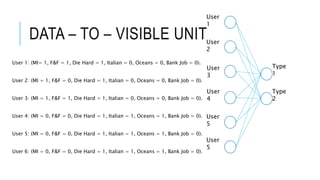

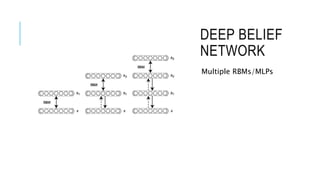

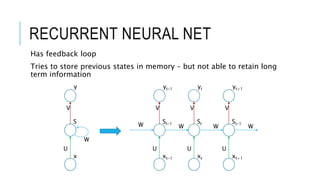

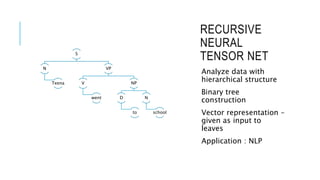










































![[DSC 2016] 系列活動:李宏毅 / 一天搞懂深度學習](https://cdn.slidesharecdn.com/ss_thumbnails/1-160521014039-thumbnail.jpg?width=640&height=640&fit=bounds)
































