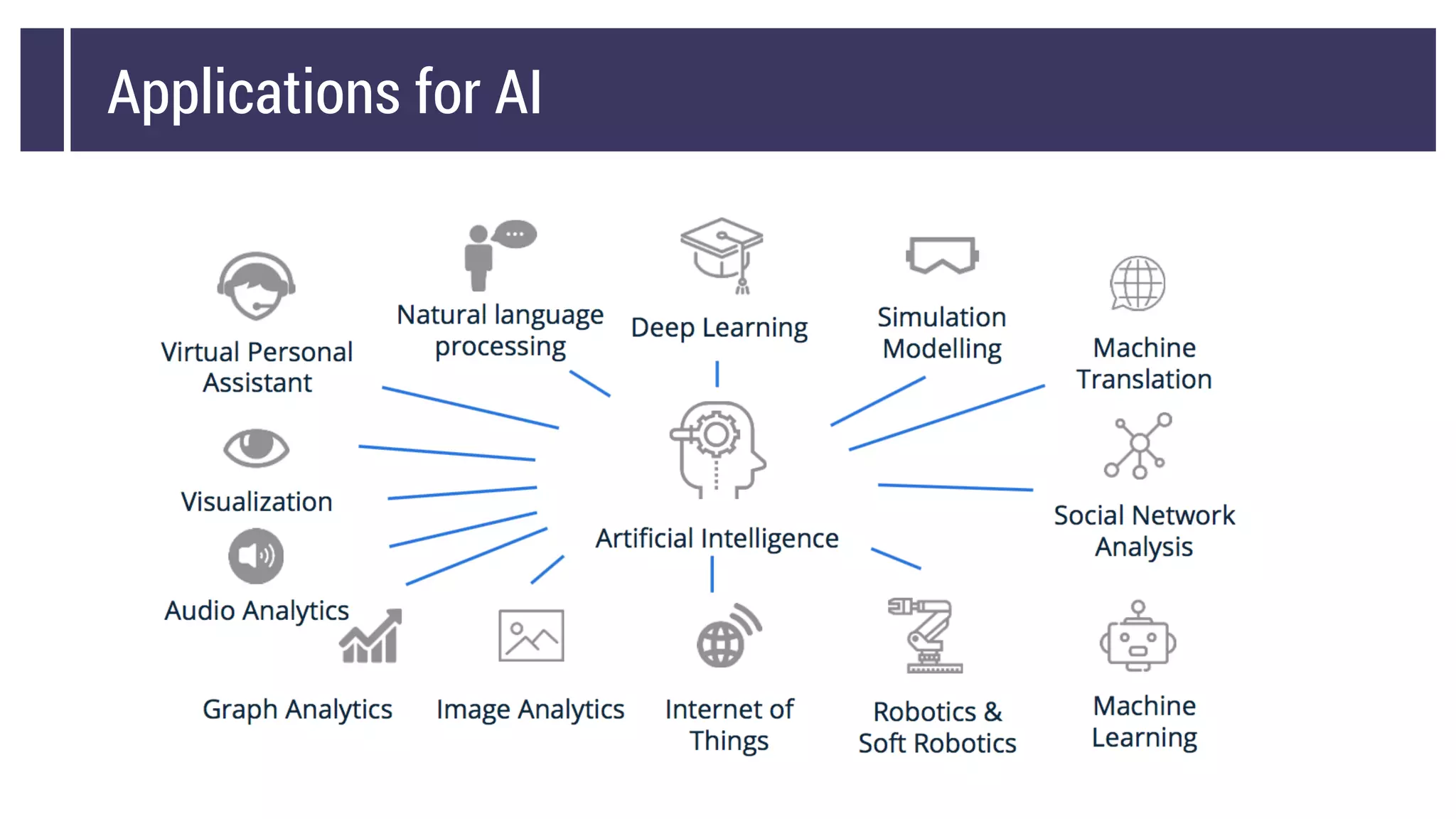
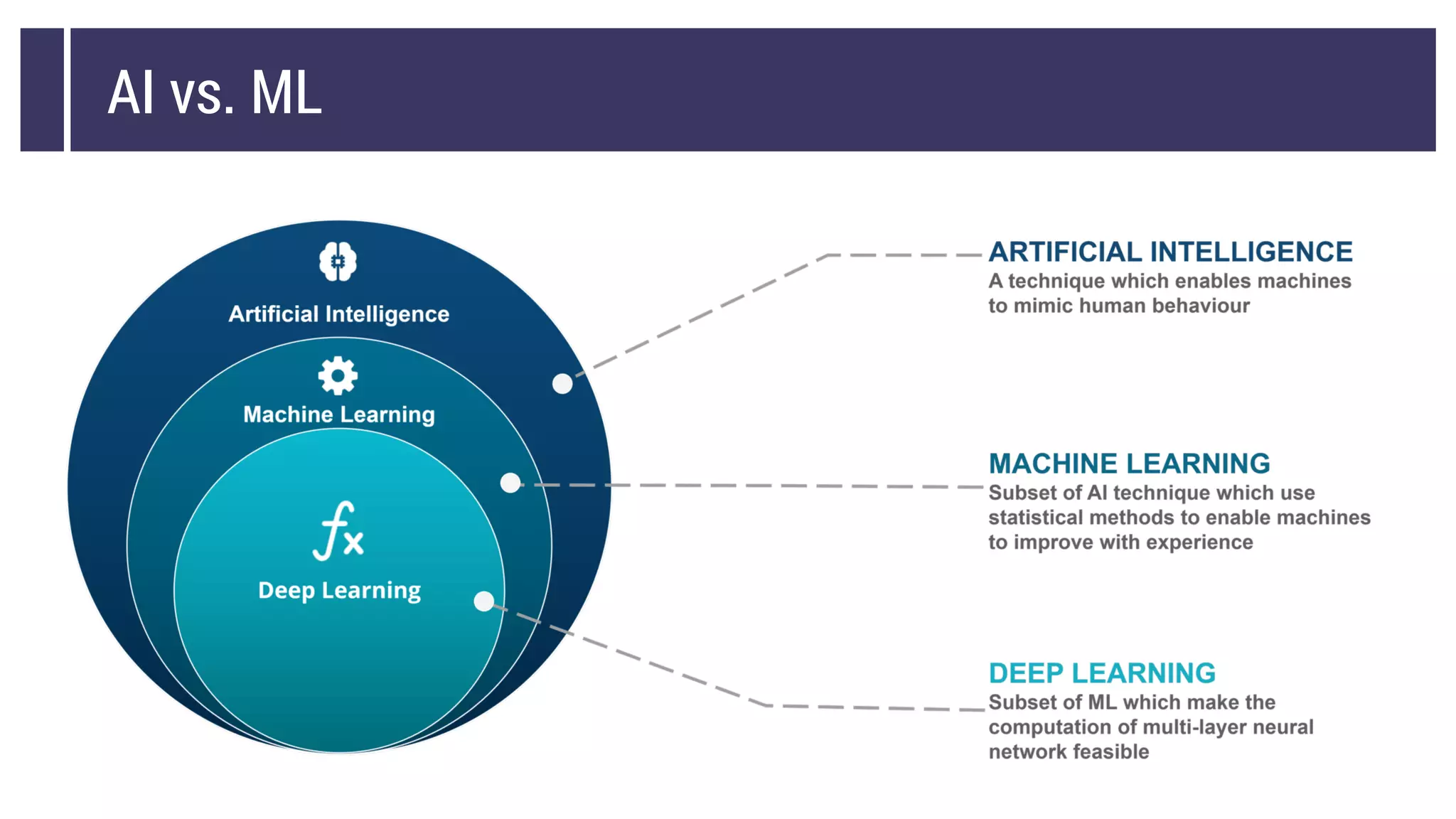
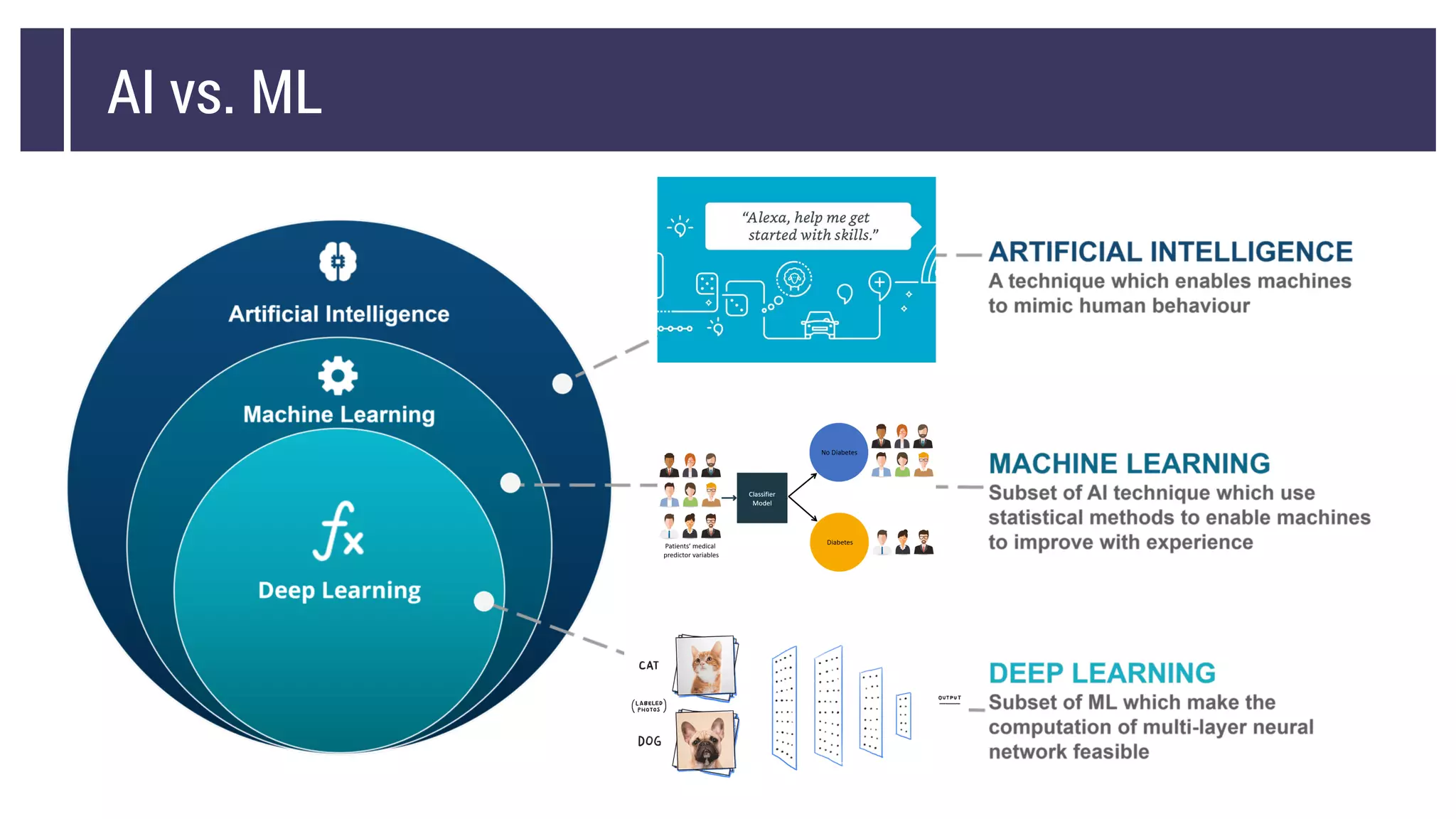
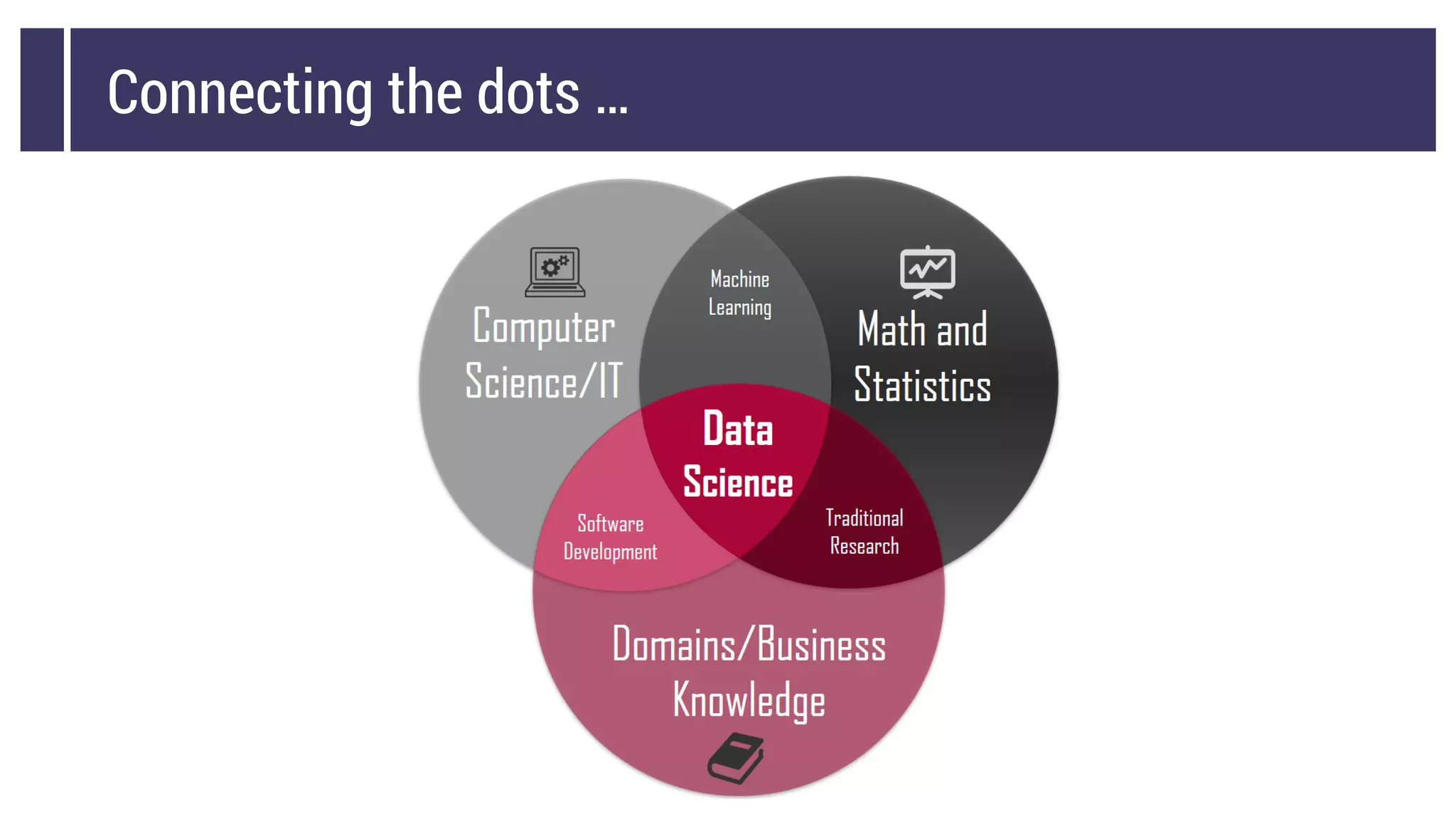
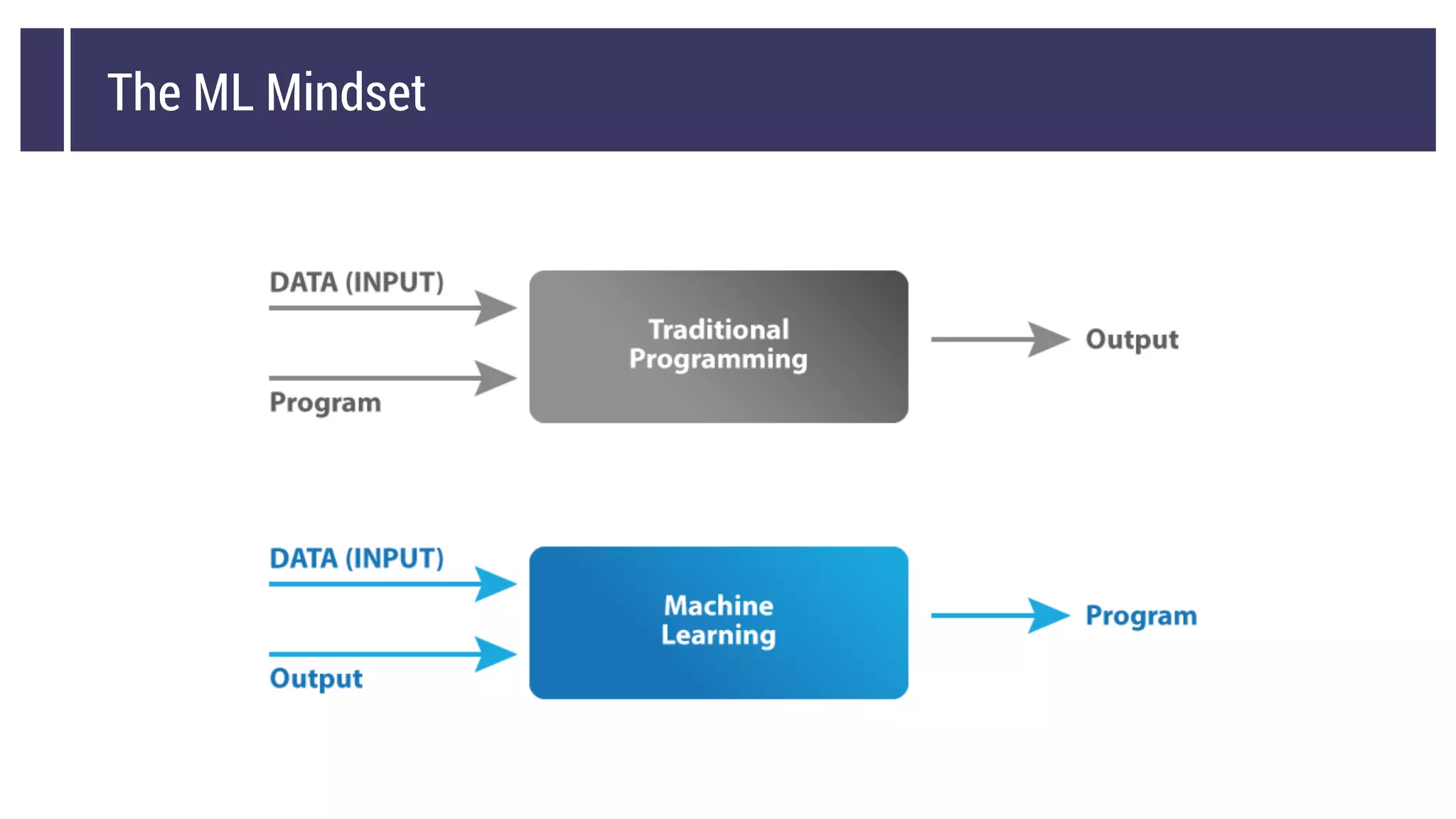
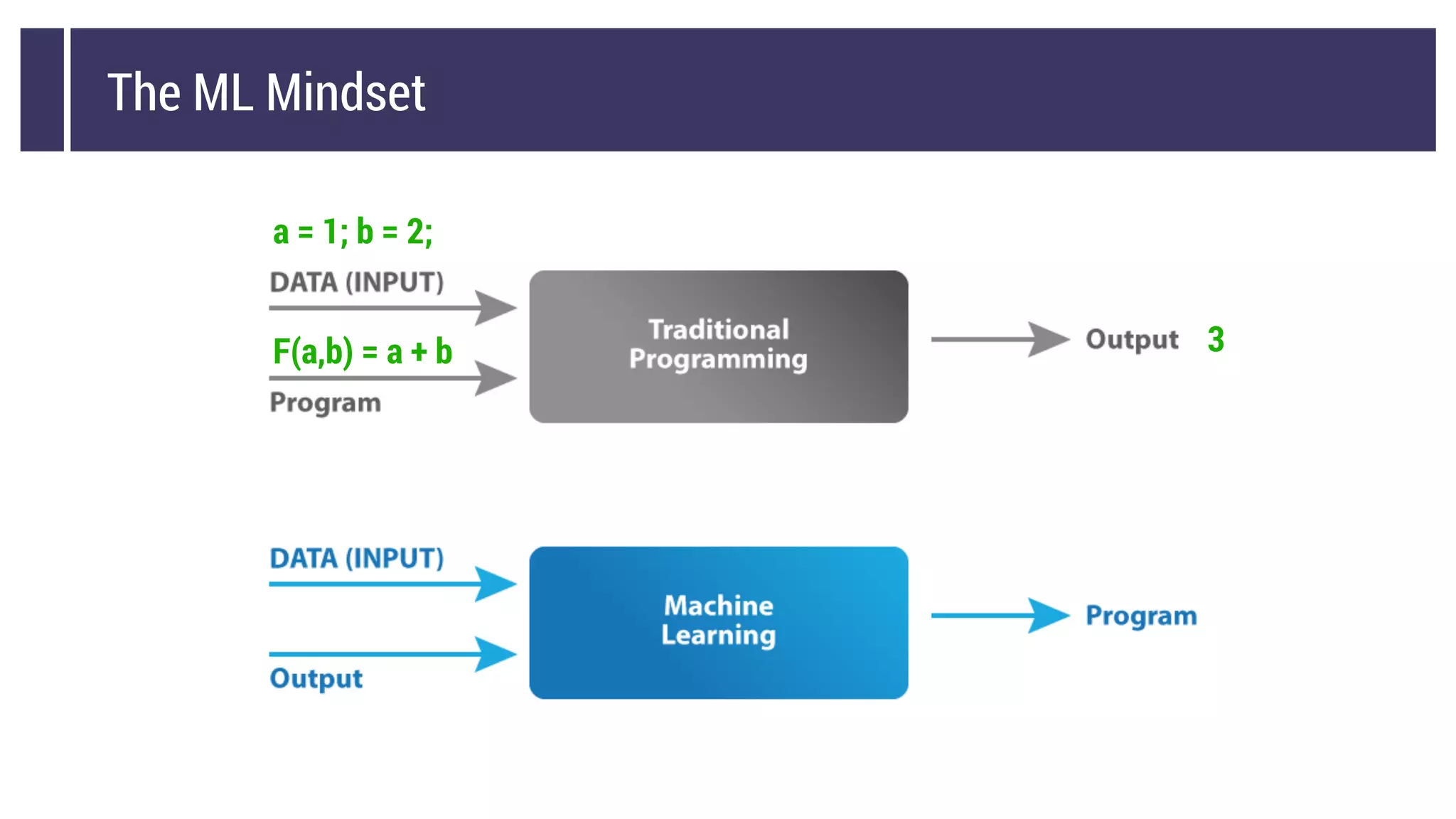
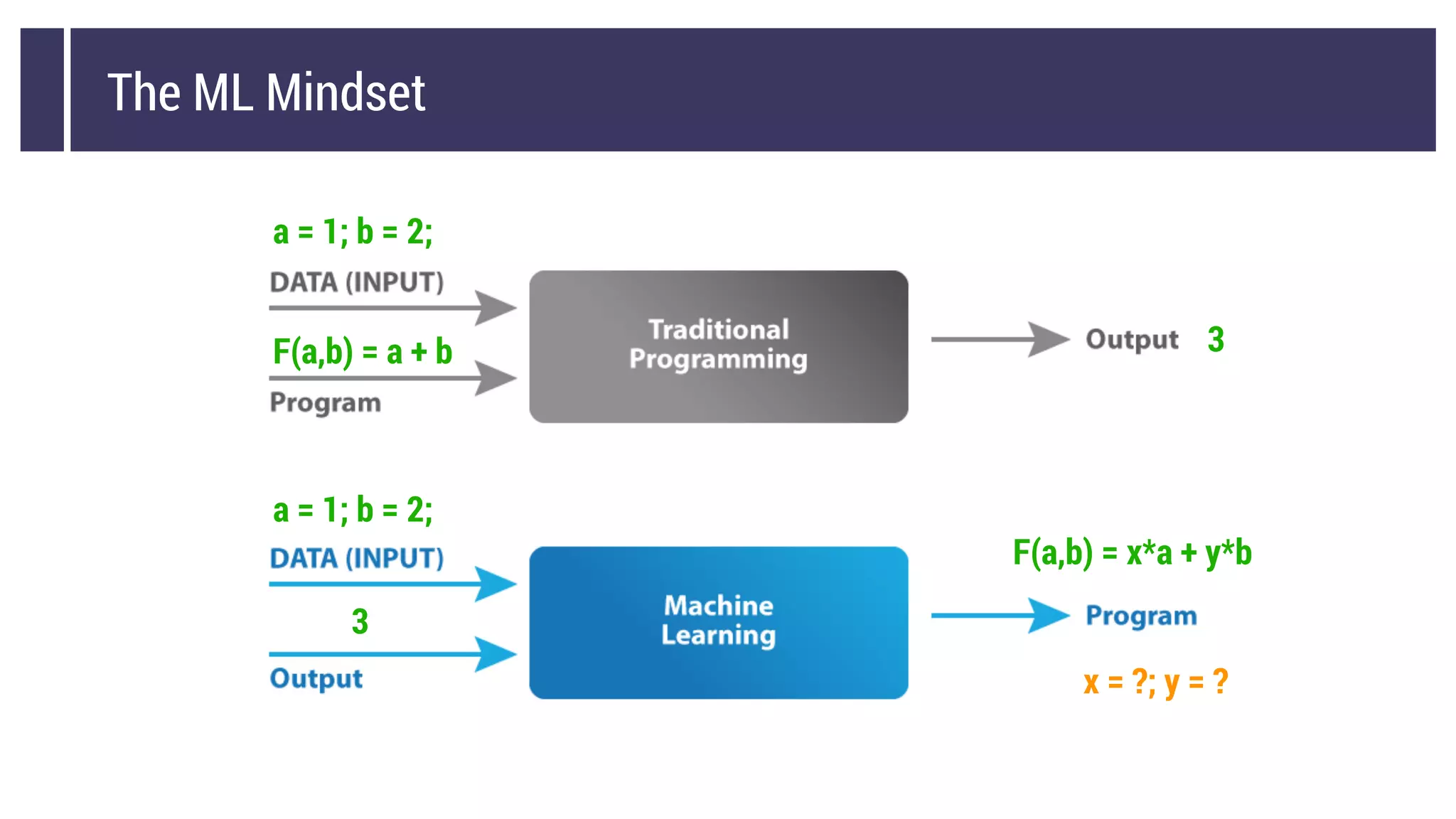
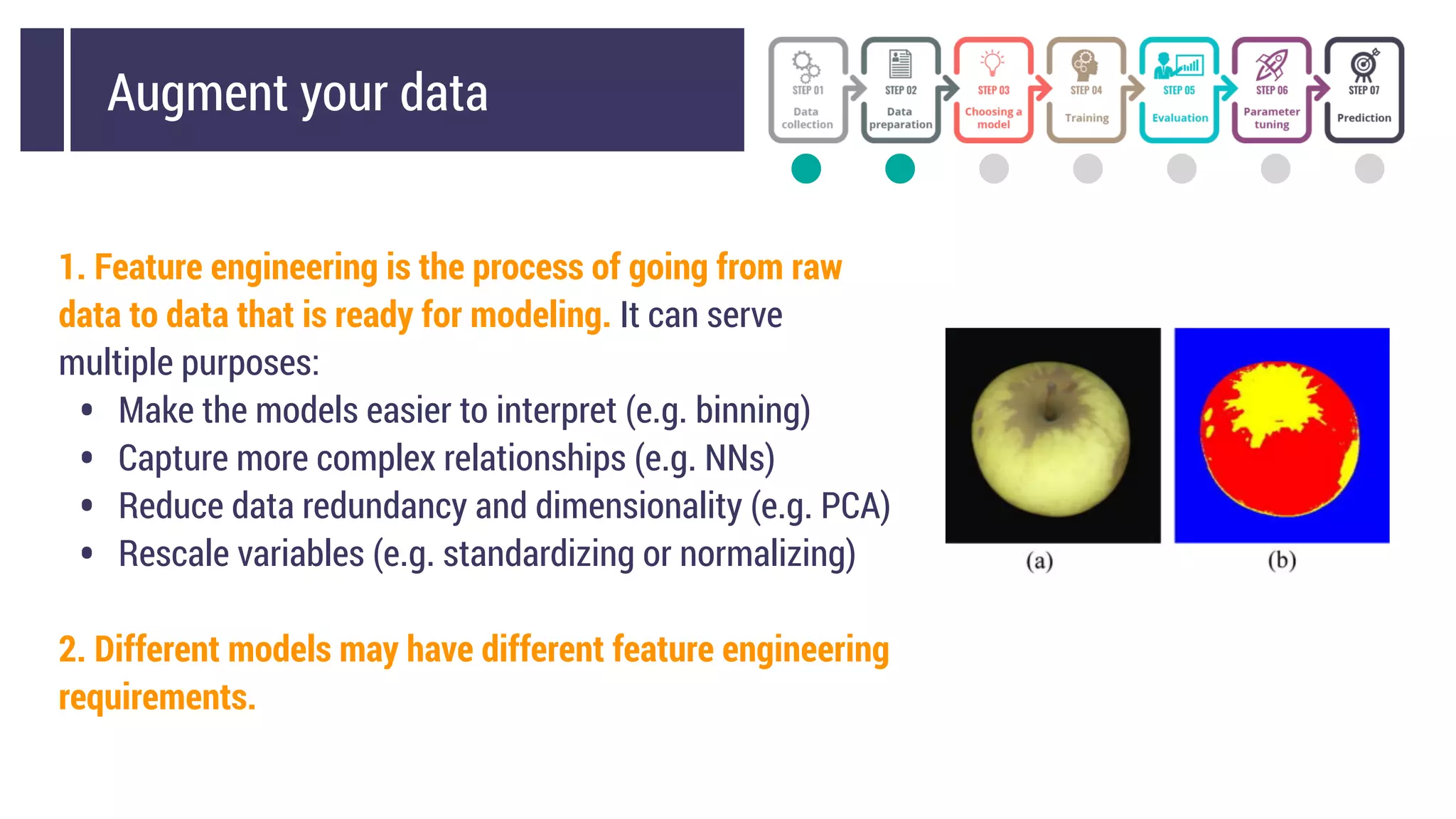
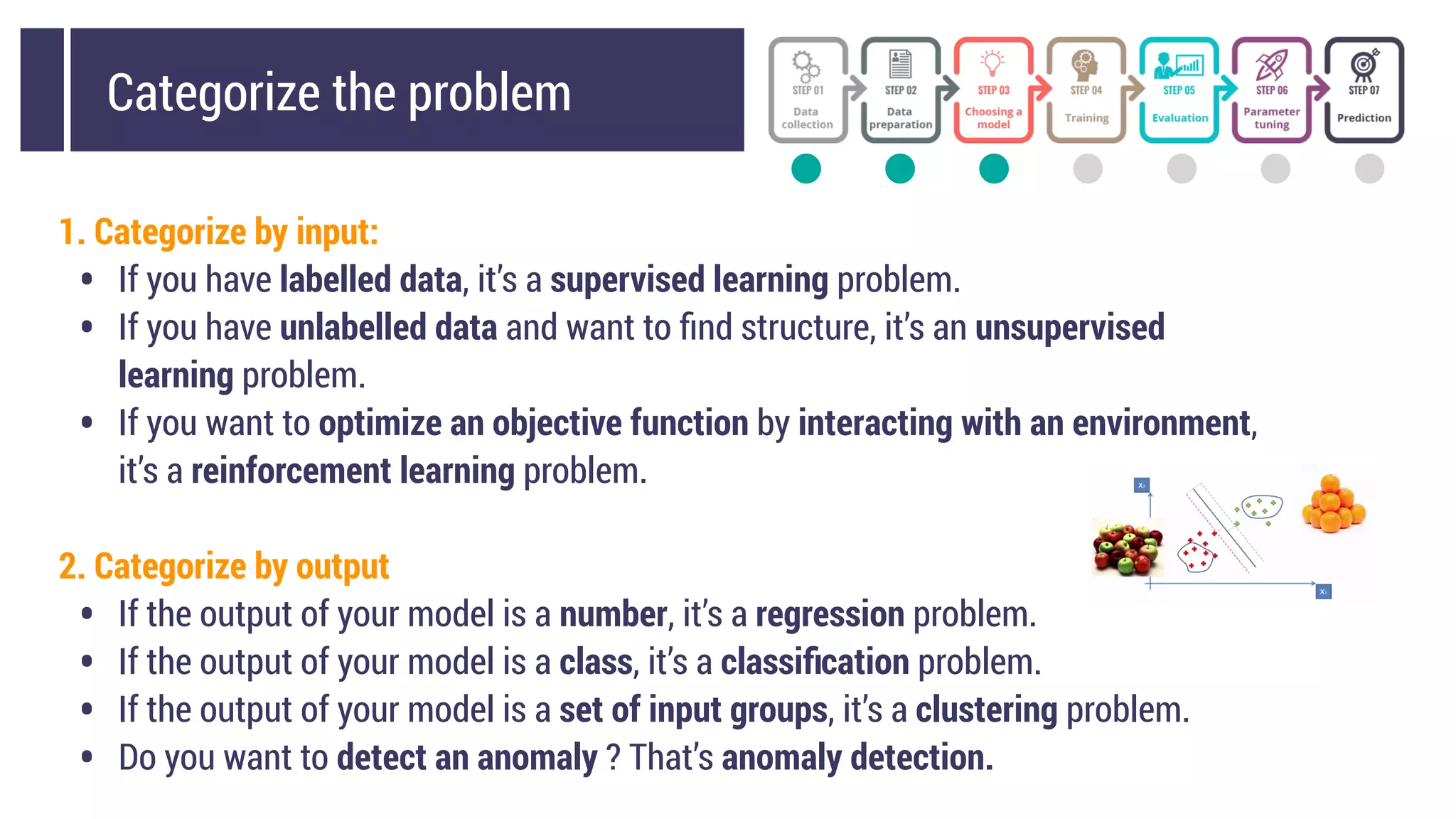
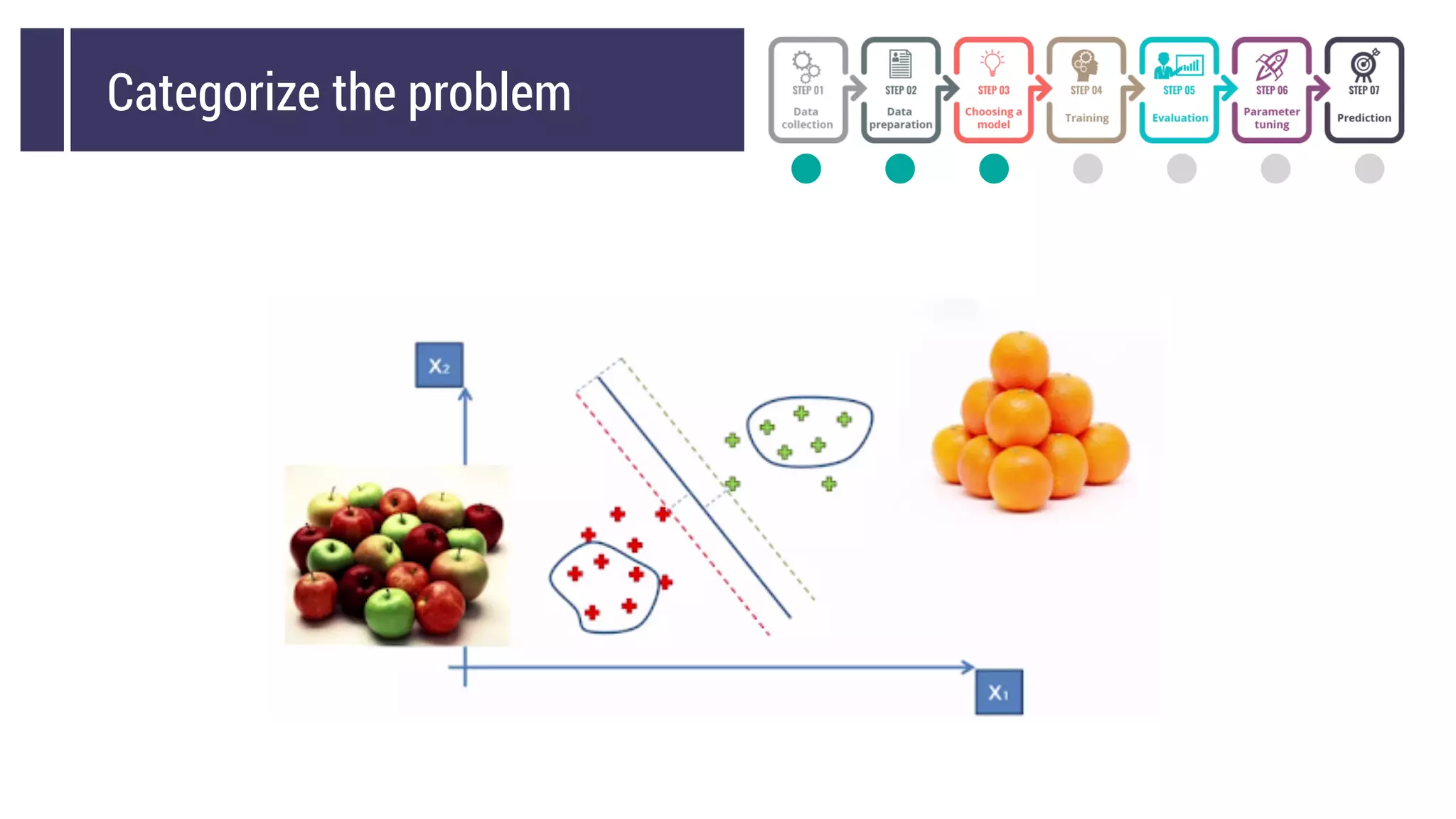
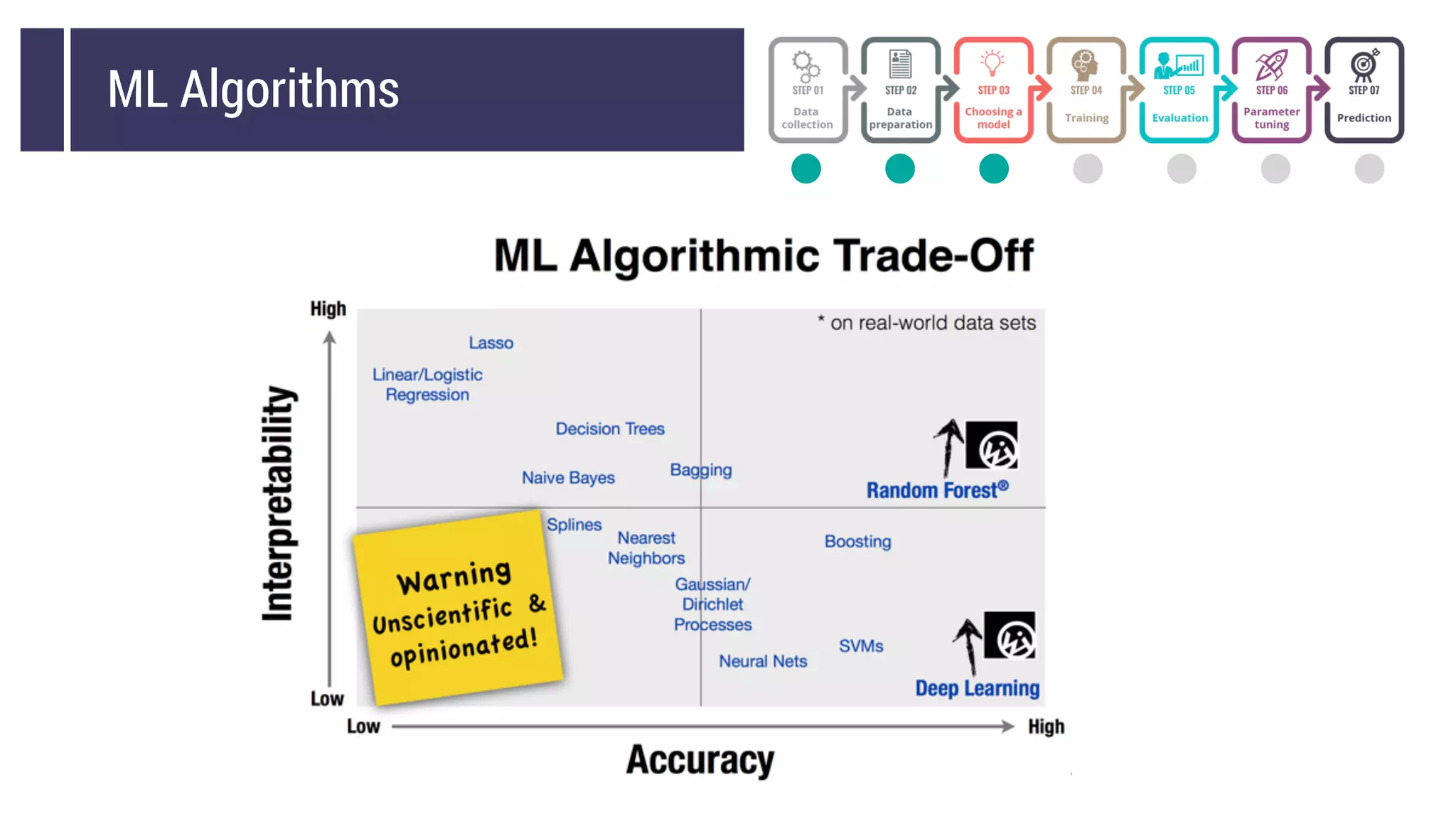
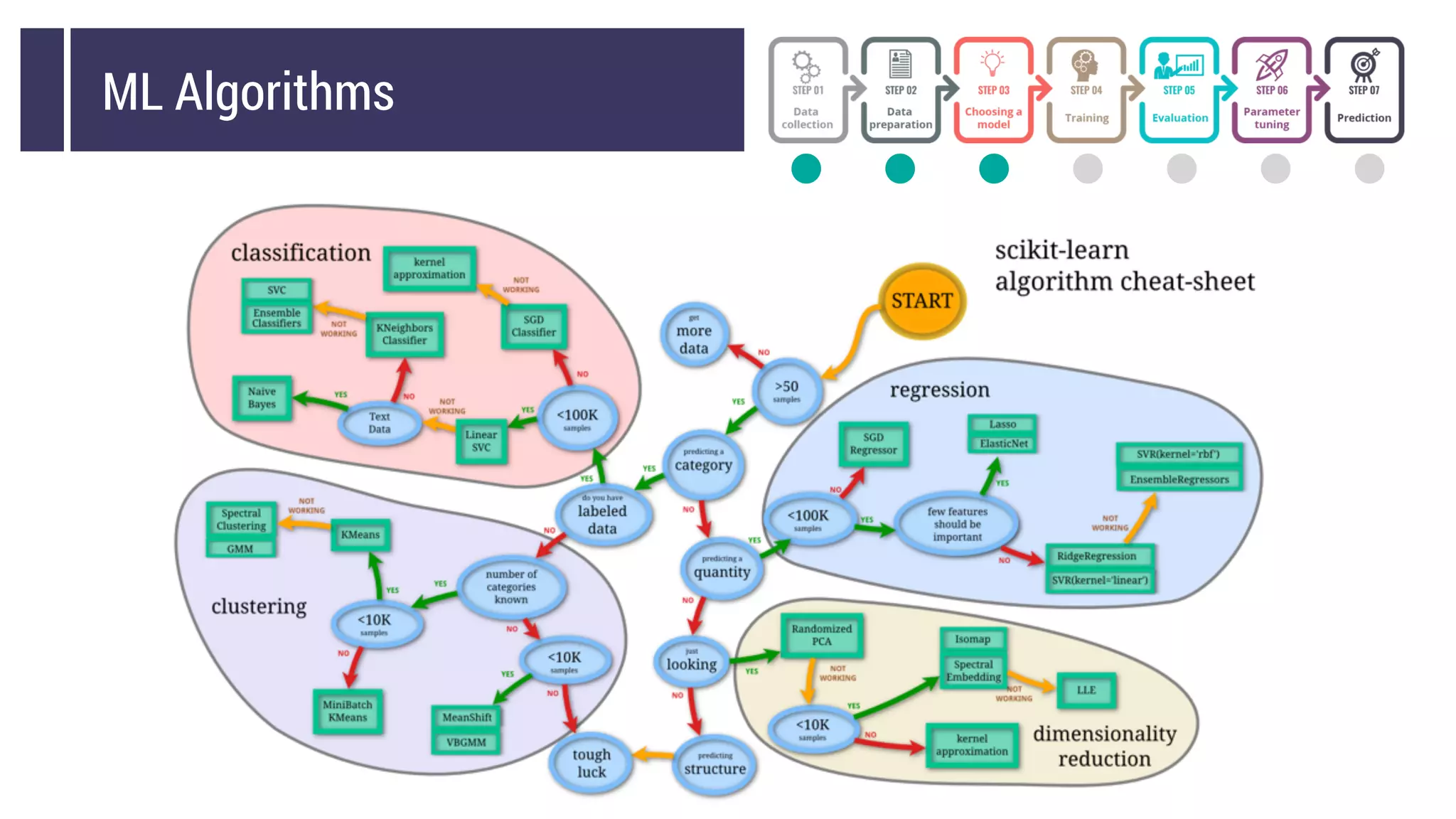
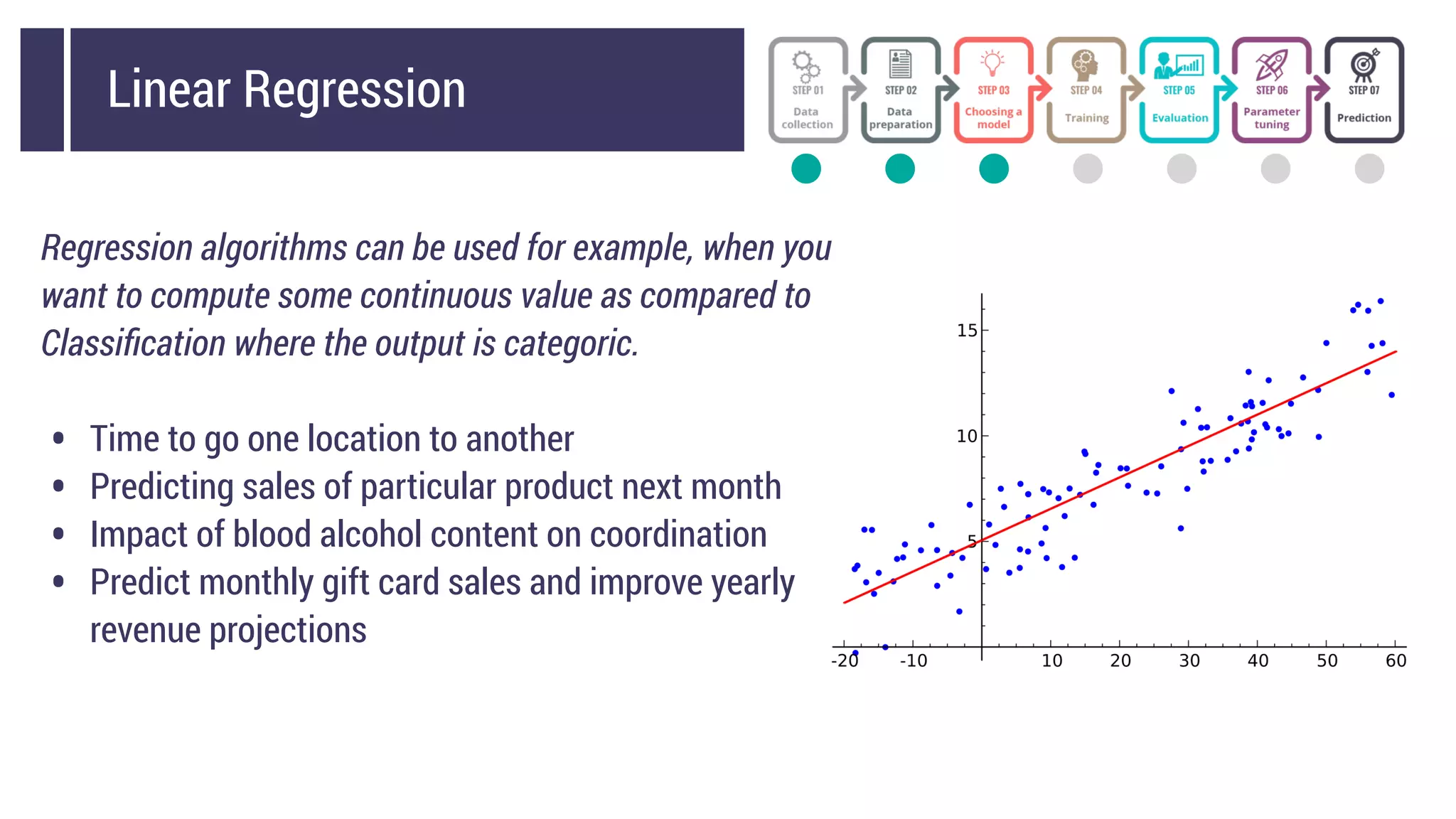
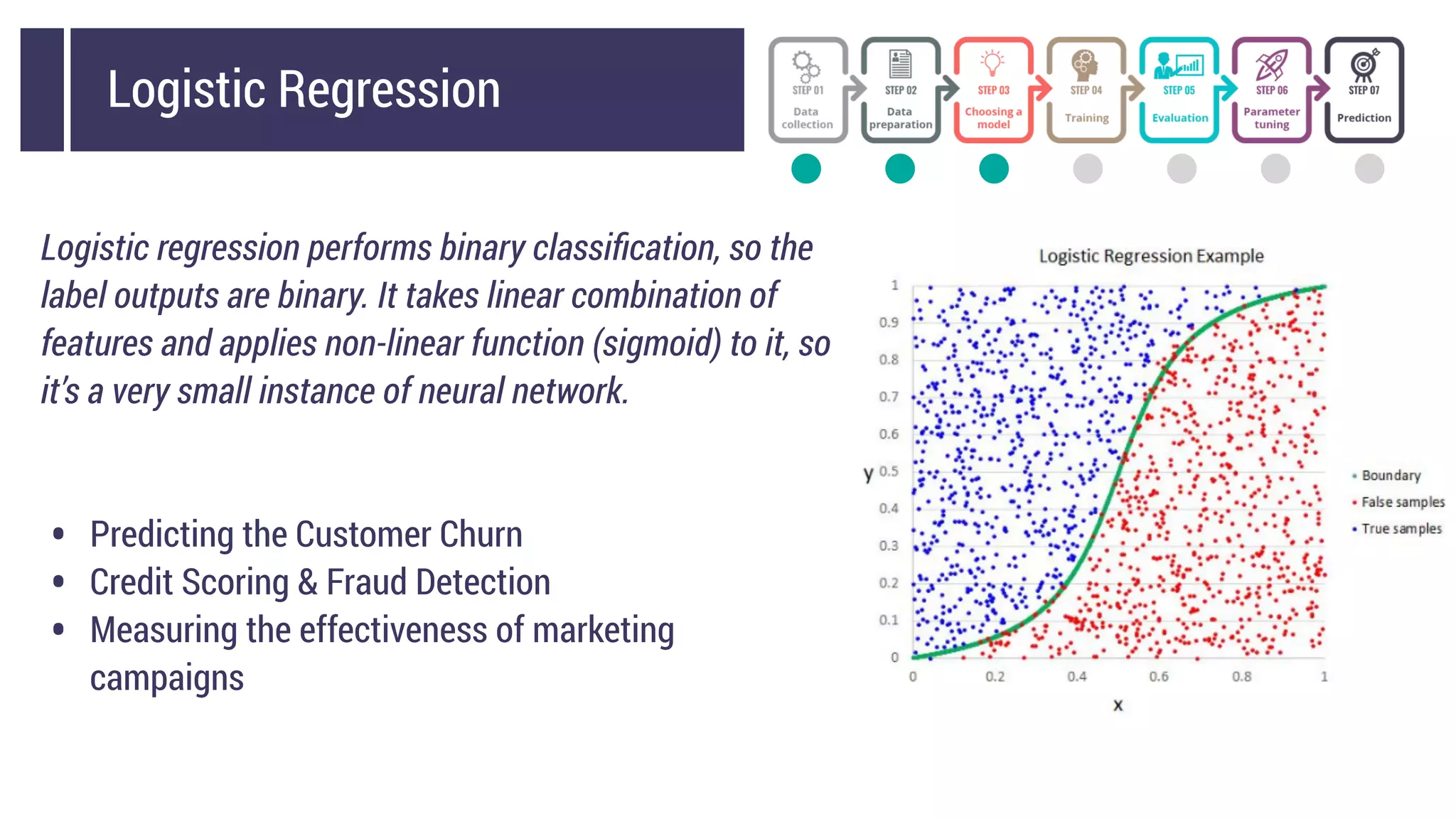
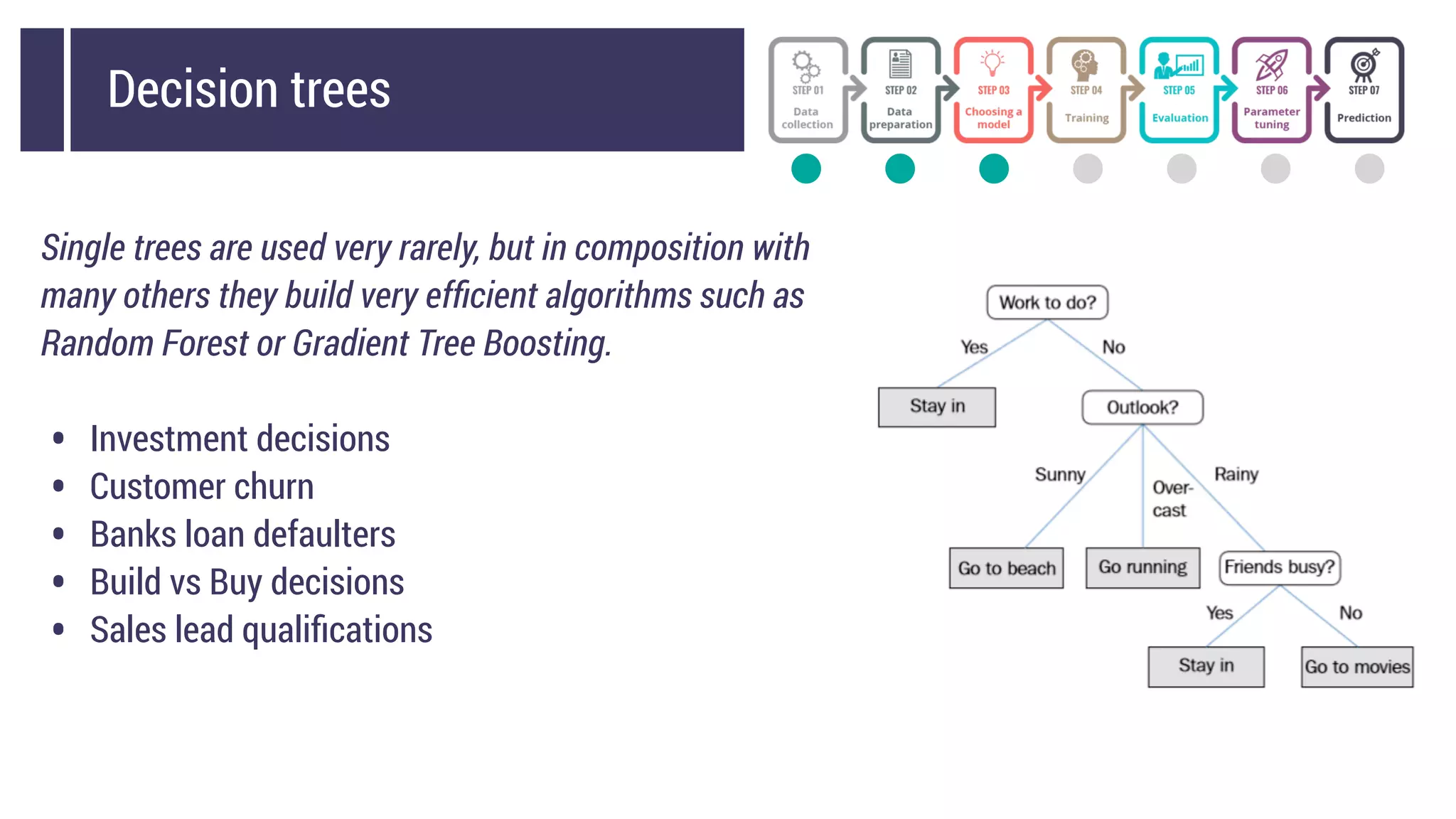
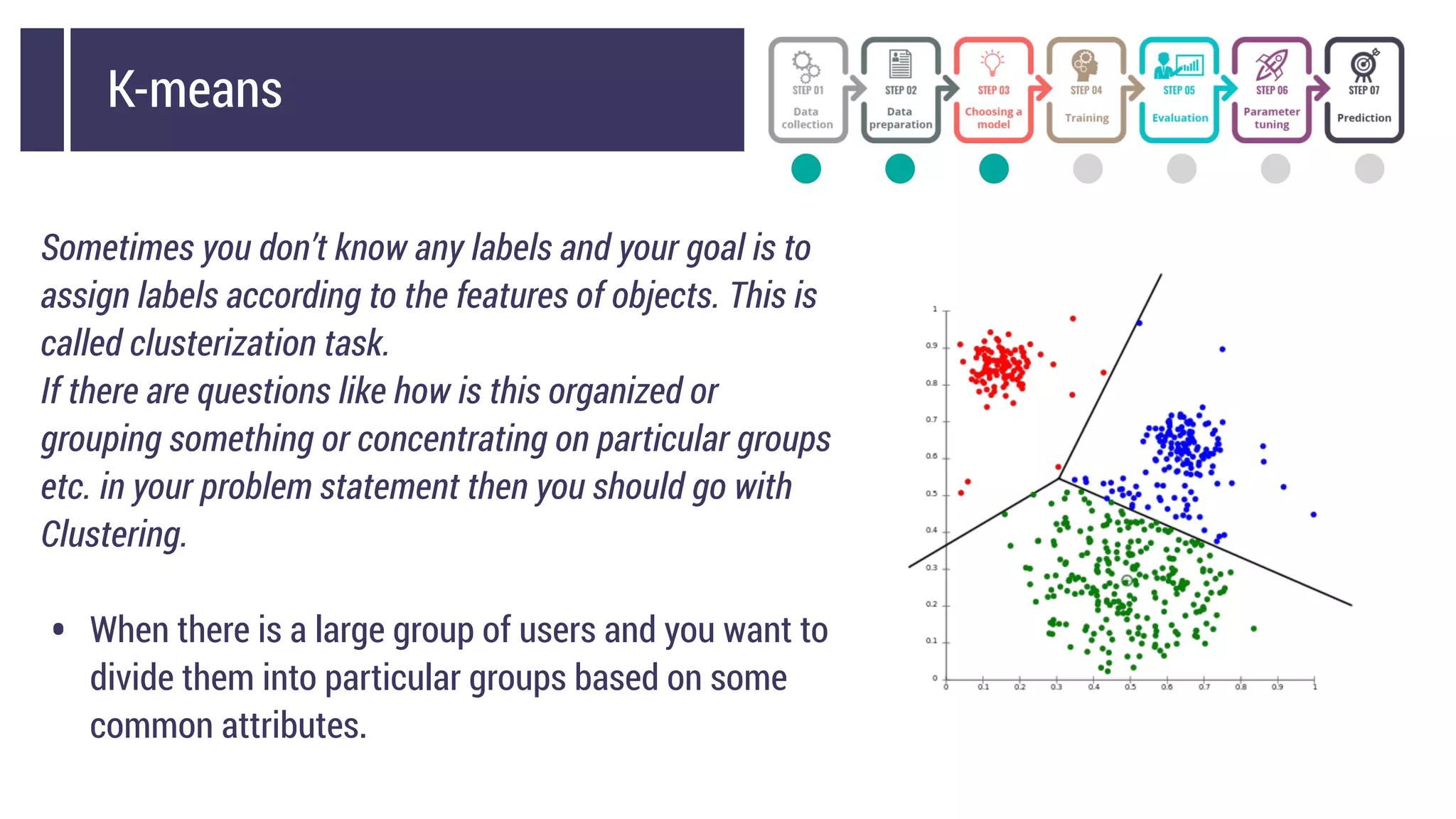
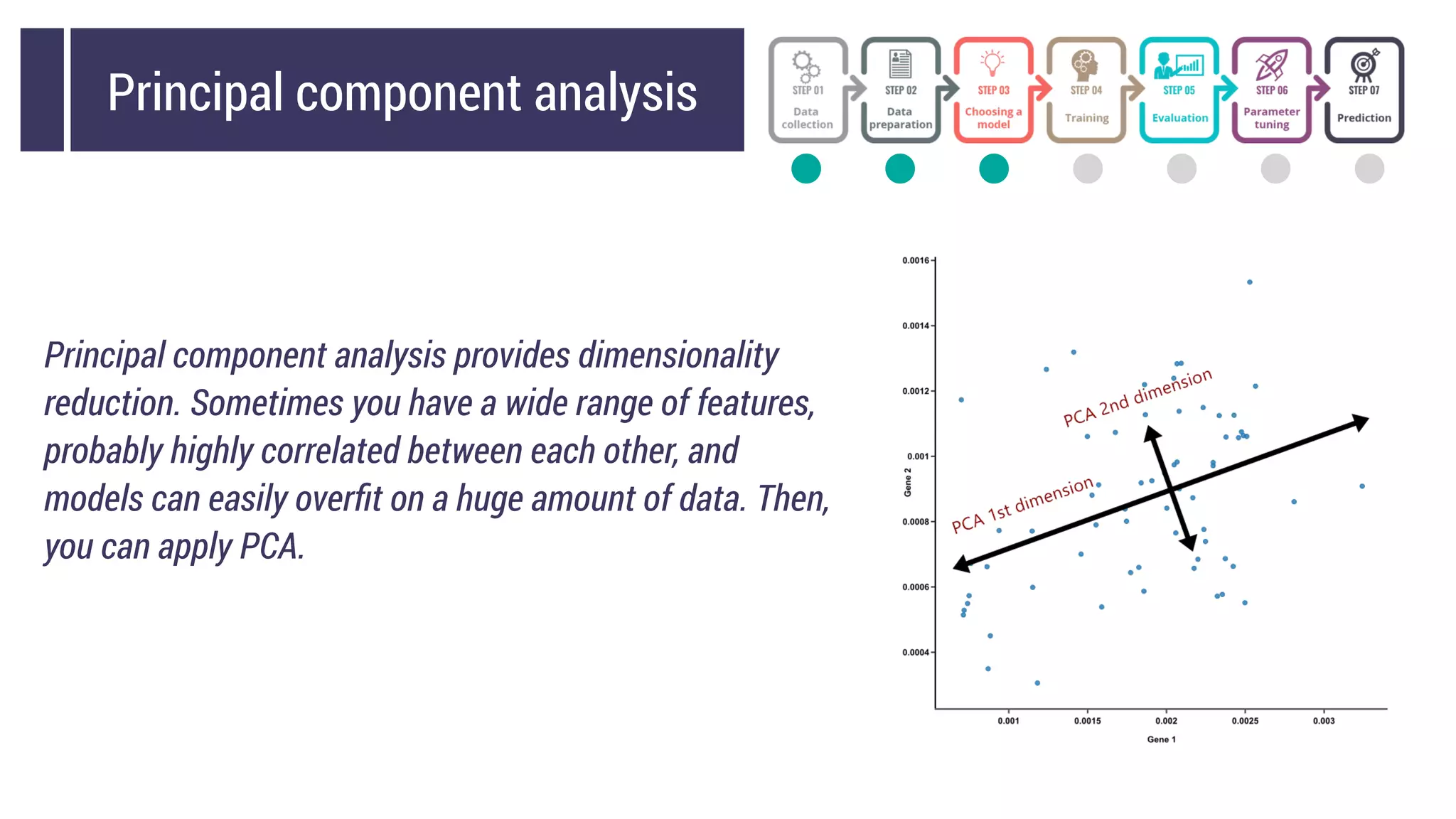
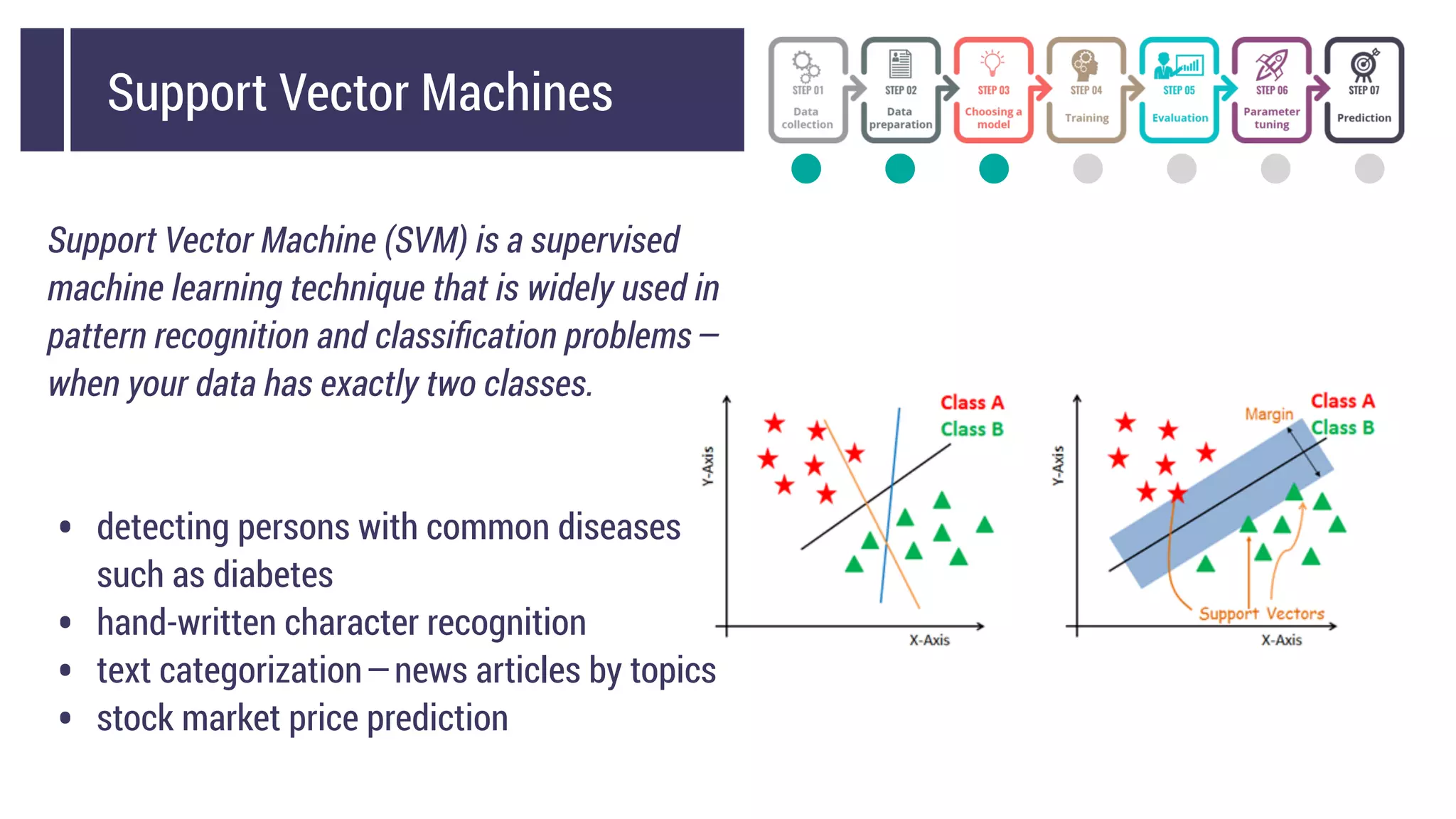
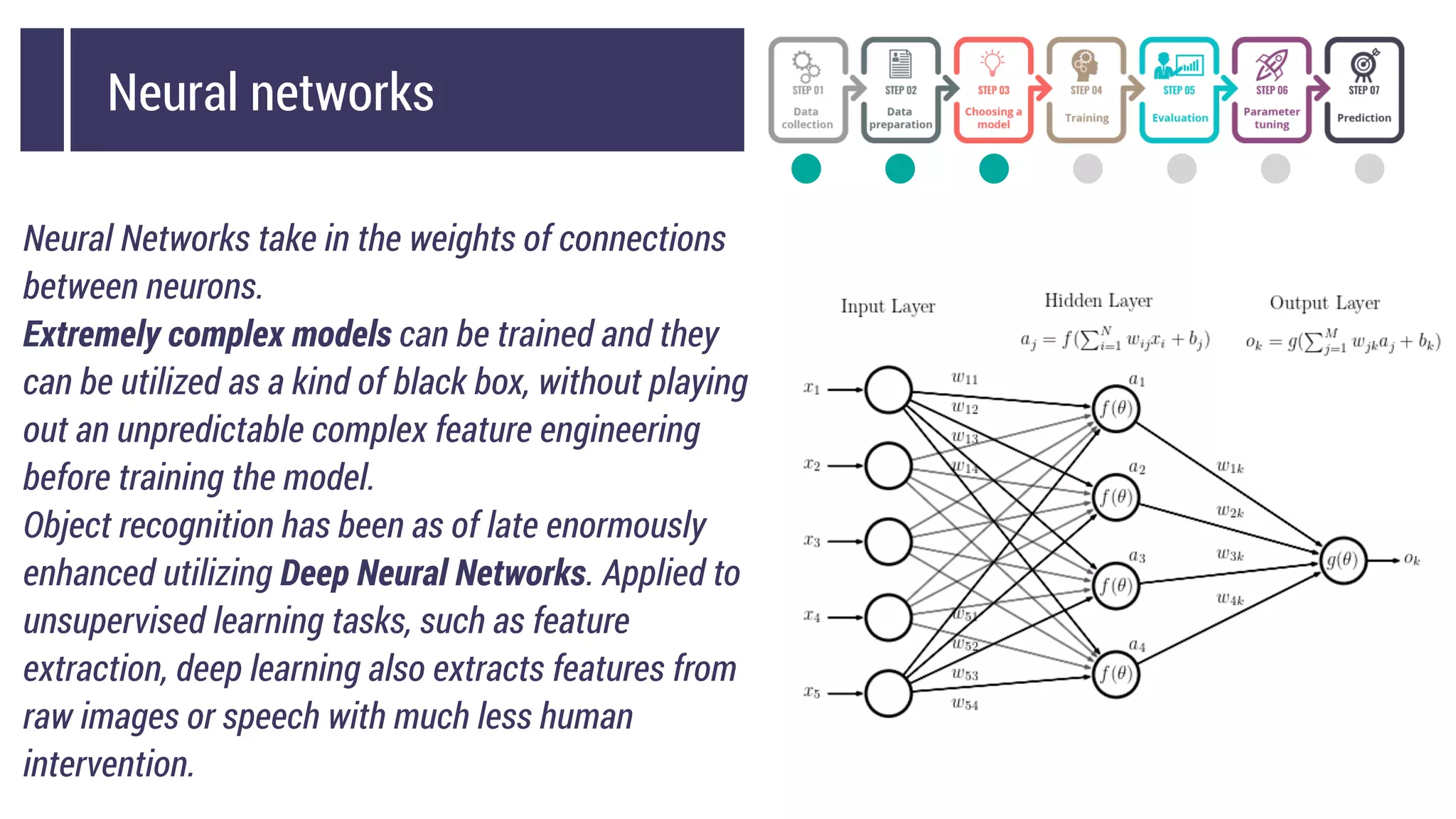
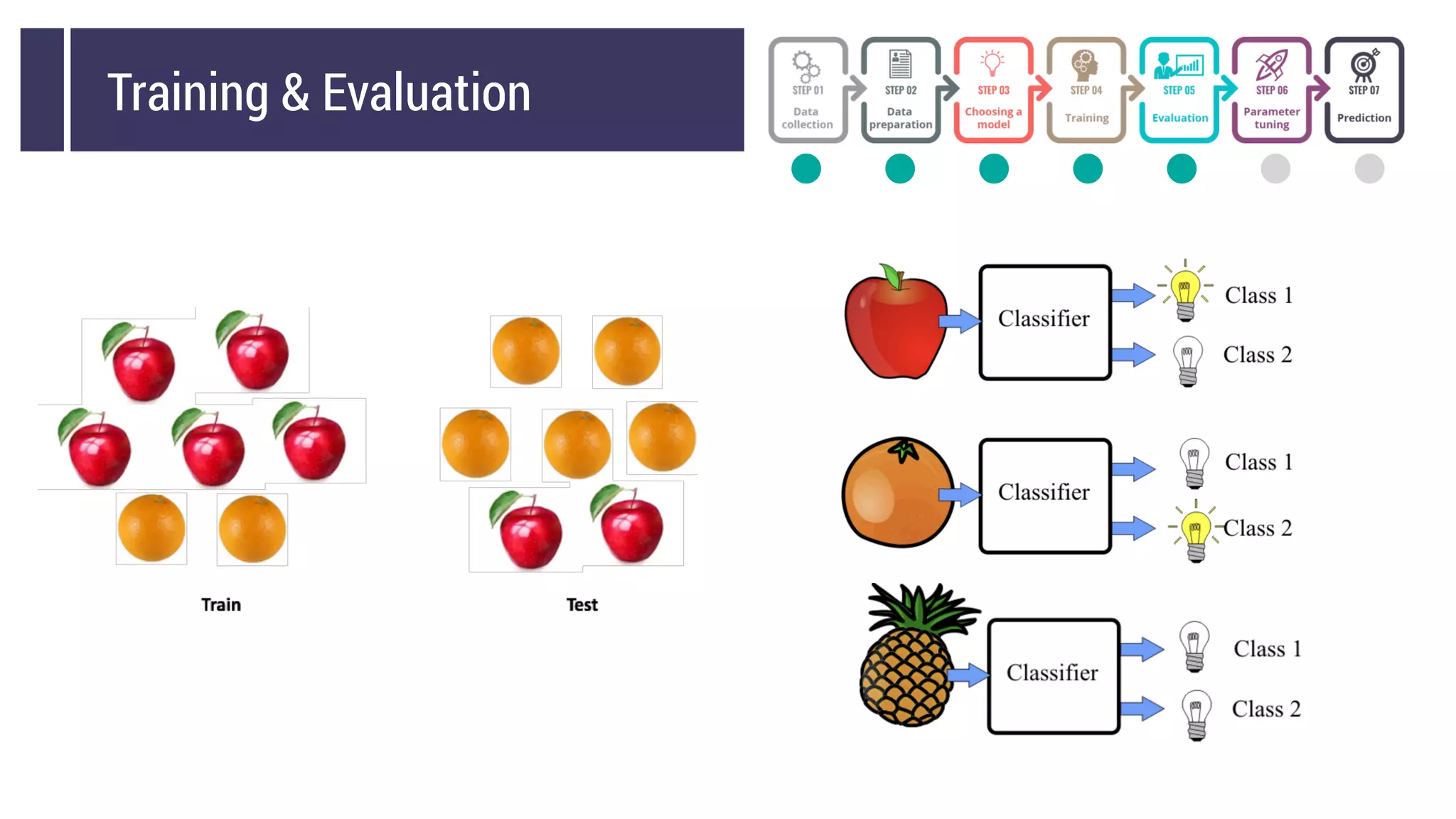
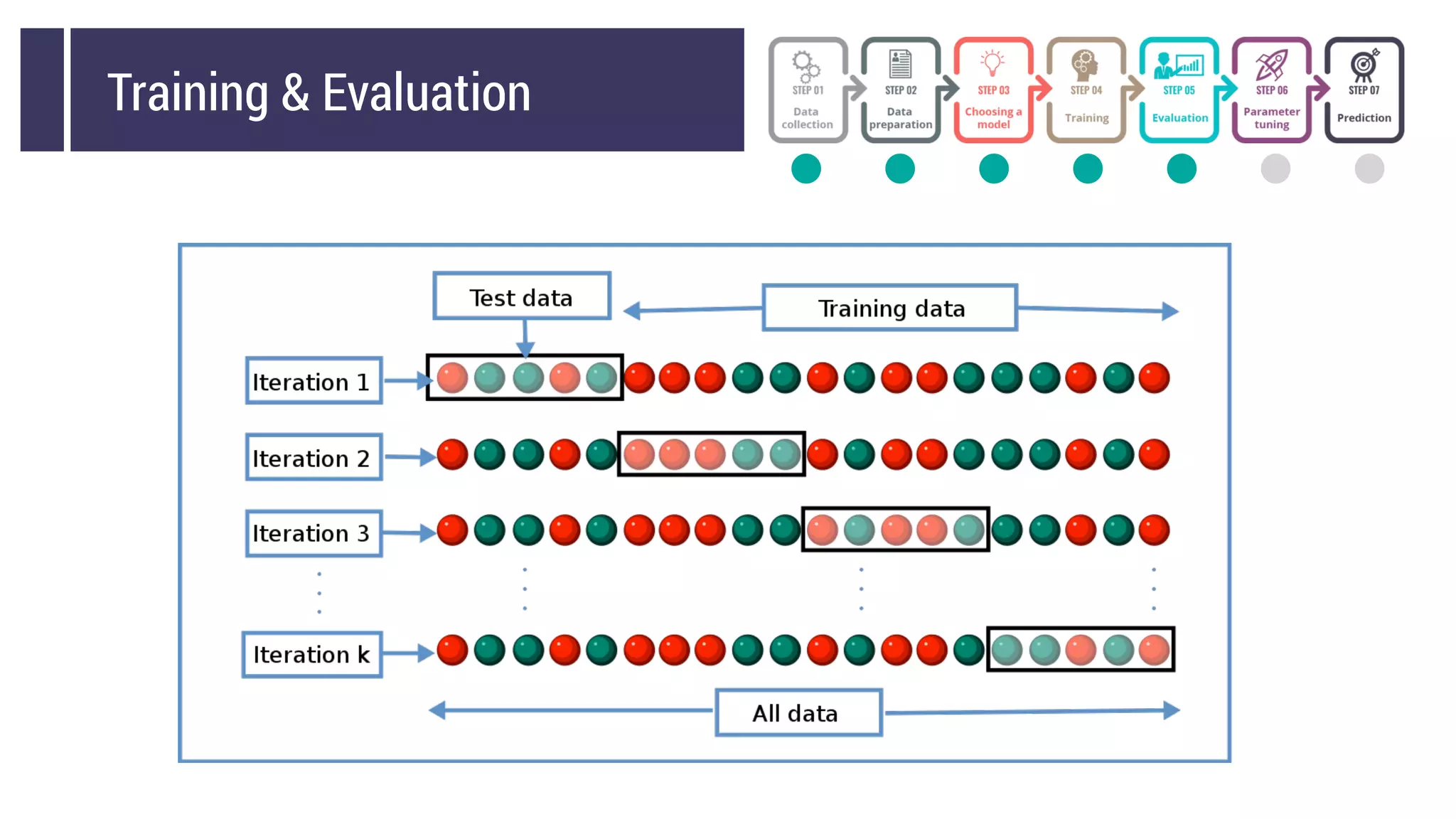
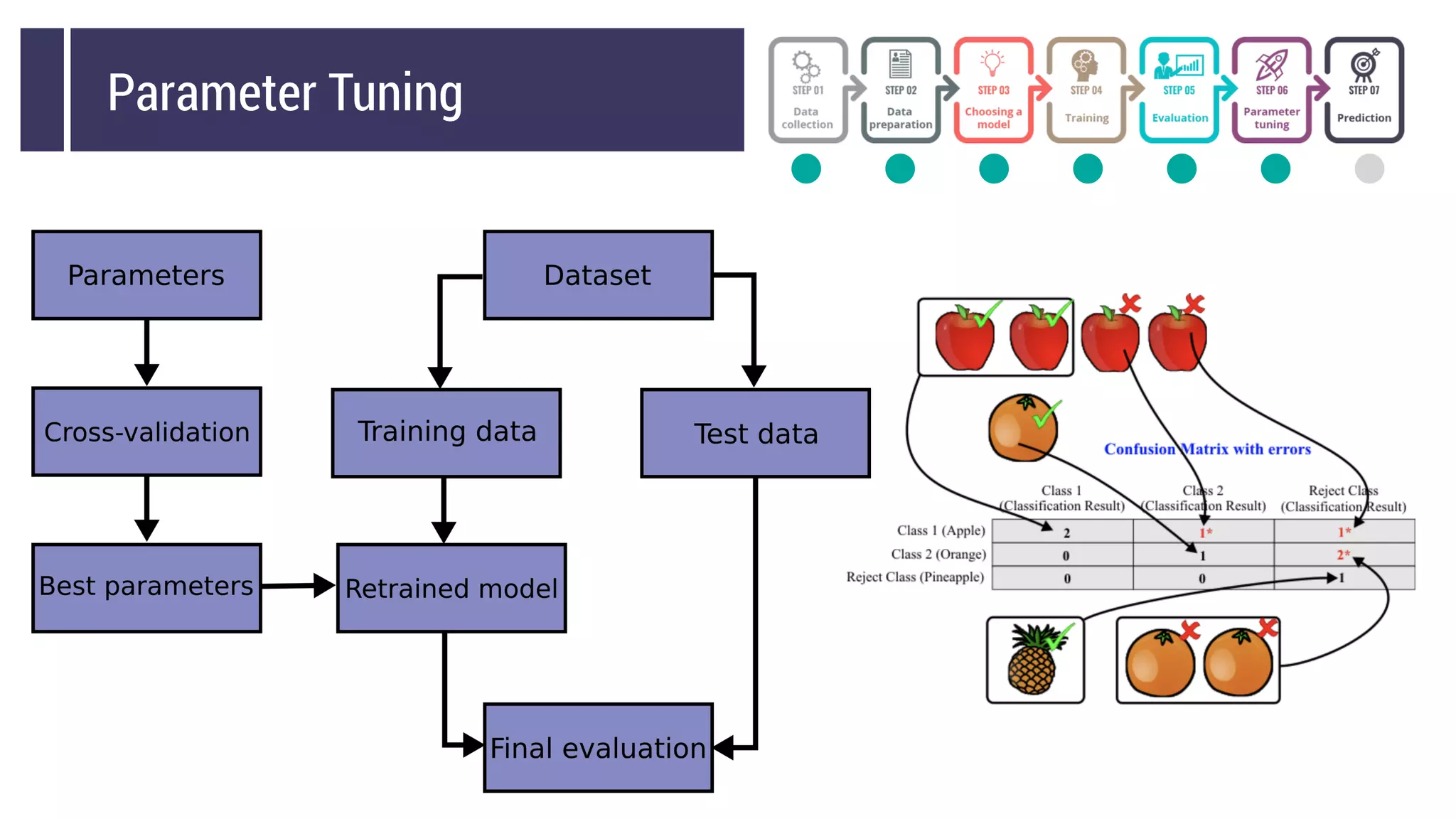
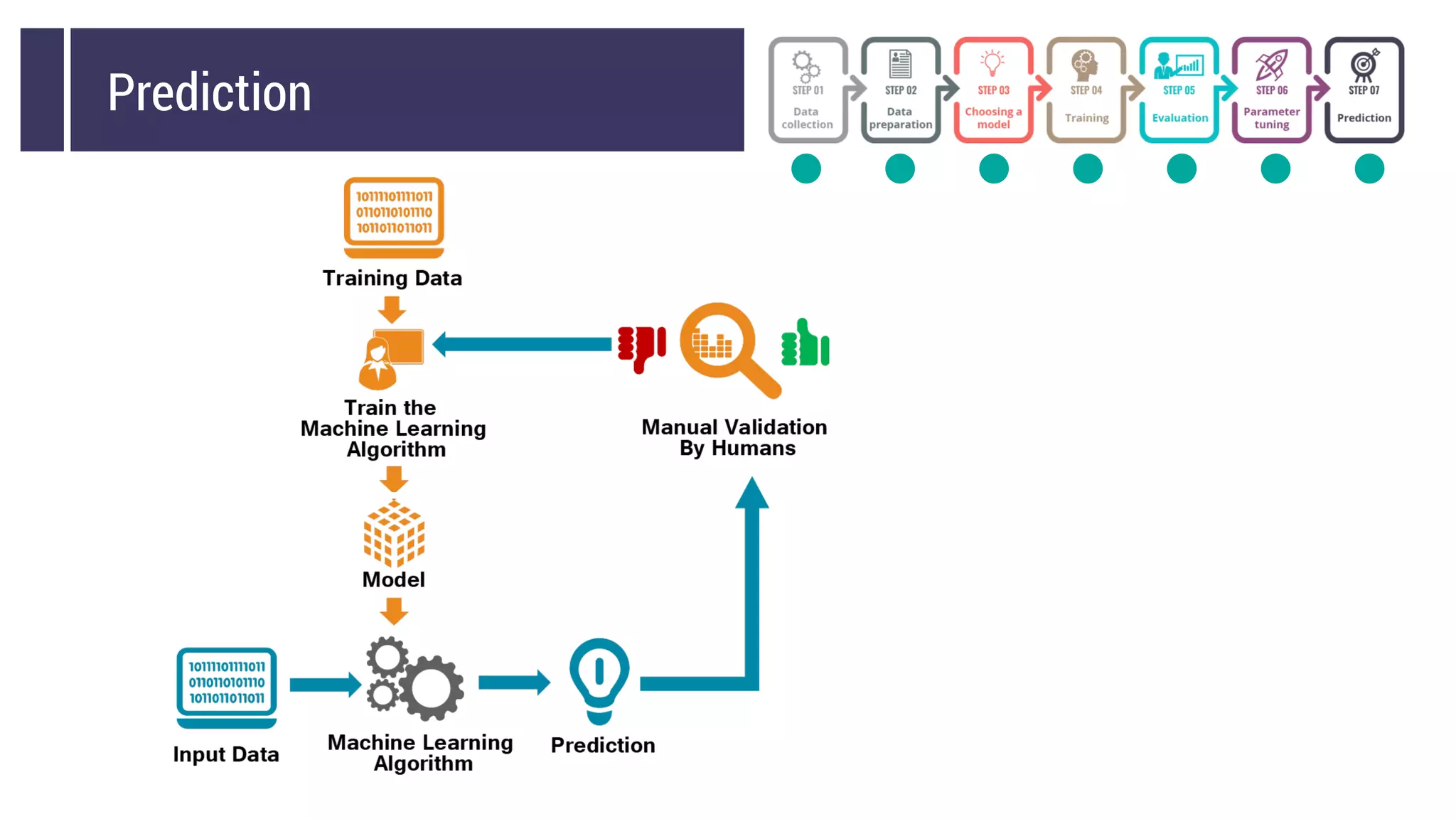
This document discusses choosing a machine learning technique to solve a problem. It begins with an overview of machine learning and popular approaches like linear regression, logistic regression, decision trees, k-means clustering, principal component analysis, support vector machines, and neural networks. It then discusses important considerations like knowing your data, cleaning your data, categorizing the problem, understanding constraints, choosing an algorithm, and evaluating models. Programming languages like Python and libraries, datasets, and cloud support resources are also mentioned.