This document summarizes the key steps in the locality sensitive hashing (LSH) algorithm for finding similar documents:
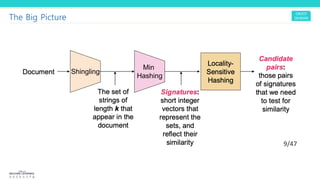
1. Documents are converted to sets of shingles (sequences of tokens) to represent them as high-dimensional data points.
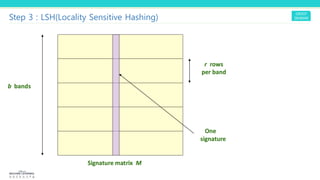
2. MinHashing is applied to generate signatures (hashes) for each document such that similar documents are likely to have the same signatures. This compresses the data into a signature matrix.
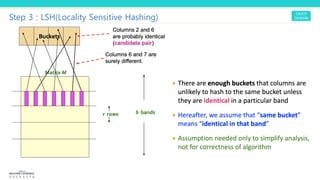
3. LSH uses the signature matrix to hash similar documents into the same buckets with high probability, finding candidate pairs for further similarity evaluation and filtering out dissimilar pairs from consideration. This improves the computation efficiency over directly comparing all pairs.






![Step 1 : Shingling
• A k-shingle for a document is a sequence of k-tokens that appea
rs in the document
• Example : k=2 document D=abcab
• Shingling -> {ab, bc, ca, ab} -> {ab, bc, ca}
• Hash the shingles -> {1, 5, 7} = [1, 0, 0, 0, 1, 0, 1]
• If you worry about order of shingles yet, pich k large enough
• K=5 is OK for short documents](https://image.slidesharecdn.com/lshlocalitysensitivehashing-200420143441/85/Locality-sensitive-hashing-9-320.jpg)




















































































![[DSC Europe 25] Andrzej Kowalczyk - AI - how to start small and grow in the f...](https://cdn.slidesharecdn.com/ss_thumbnails/oy1zmo94qv6vpcqjvno2-andrzej-kowalczyk-ai-how-to-start-small-and-grow-in-the-future-1-260119121559-cf093b23-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DSC Europe 25] Milovan Jovicic - Beyond AI's Reach: The Enduring Value of Ev...](https://cdn.slidesharecdn.com/ss_thumbnails/pyeij0hurgwq5jugmtnv-2-milovan-jovicic-beyond-ais-reach-the-enduring-value-of-evergreen-design-v2-260120105856-d6ee57e5-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Laila Kakar - Leveraging AI for Strategic Excellence: Enhanci...](https://cdn.slidesharecdn.com/ss_thumbnails/eykmhrtsqmaaftwkexh7-dsc-lailakakar-1-260119101520-5f3b5616-thumbnail.jpg?width=640&height=640&fit=bounds)




