Downloaded 83 times












![Smoothing using Binning Methods
* Sorted data for price (in dollars): 4, 8, 9, 15, 21, 21, 24,
25, 26, 28, 29, 34
* Partition into (equi-depth) bins:
- Bin 1: 4, 8, 9, 15
- Bin 2: 21, 21, 24, 25
- Bin 3: 26, 28, 29, 34
* Smoothing by bin means:
- Bin 1: 9, 9, 9, 9
- Bin 2: 23, 23, 23, 23
- Bin 3: 29, 29, 29, 29
* Smoothing by bin boundaries: [4,15],[21,25],[26,34]
- Bin 1: 4, 4, 4, 15
- Bin 2: 21, 21, 25, 25
- Bin 3: 26, 26, 26, 34](https://image.slidesharecdn.com/datapre-processing-170313100854-170315122804/85/Data-pre-processing-13-320.jpg)











![ Min-Max Normalization26
Data Normalization
Suppose that the minA and maxA are the minimum and maximum values of an
attribute A. Min-max normalization maps a value, v, of A to v’ in the new range
[new_minA, new_maxA] by computing
AA
A
min-max
min-
='
v
v (new_maxA – new_minA) + new_minA
Suppose the minimum and maximum values for the attribute income are $12,000 and $98,000,
respectively. We would like to map income to the range [0.0, 1.0]. By min-max normalization, a
value of $73,600 for income will be transformed to
716.0=0+)0.0-0.1(12,000-8,0009
12,000-3,6007
(Eq.4 )](https://image.slidesharecdn.com/datapre-processing-170313100854-170315122804/85/Data-pre-processing-26-320.jpg)











![38
Suppose we have the following data:
1, 3, 4, 7, 2, 8, 3, 6, 3, 6, 8, 2, 1, 6, 3, 5, 3, 4, 7, 2, 6, 7, 2, 9
Create a three-bucket histogram
Sorted (24 data samples in total)
1 1 2 2 2 2 3 3 3 3 3 4 4 5 6 6 6 6 7 7 7 8 8 9
Value 1 2 3 4 5 6 7 8 9
Frequenc
y
2 4 5 2 1 4 3 2 1
Bucket Frequency
[1,3] 11
[4,6] 7
[7,9] 6
Histogram
0
2
4
6
8
10
12
[1,3] [4,6] [7,9]
Bucket
Frequency
Equal-Width Histogram](https://image.slidesharecdn.com/datapre-processing-170313100854-170315122804/85/Data-pre-processing-38-320.jpg)
![39
Value 1 2 3 4 5 6 7 8 9
Frequenc
y
2 4 5 2 1 4 3 2 1
Bucket Frequency
[1,2] 6
[3,5] 8
[6,9] 10
Equal-Depth Histogram
Histogram
0
2
4
6
8
10
12
[1,2] [3,5] [6,9]
Bucket
Frequency](https://image.slidesharecdn.com/datapre-processing-170313100854-170315122804/85/Data-pre-processing-39-320.jpg)
![40
Bucket avg
[1,2] 3
[3,5] 2.67
[6,9] 2.5
V-Optimal Histogram
Value 1 2 3 4 5 6 7 8 9
Frequenc
y
2 4 5 2 1 4 3 2 1
∑
=
2
)-)((
i
i
ub
lbj
iavgjfFor the ith bucket, its weighted variance SSEi =
Suppose the three buckets are [1,2], [3,5], and [6,9]
ubi: the max. value in the ith bucket
lbi: the min. value in the ith bucket
f(j) (j=lbi,…,ubi): the frequency of jth value in the ith bucket
avgi: the average frequency in the ith bucket
2=3)-4(+)3-2(= 22
1SSE
67.8=2.67)-1(+2.67)-2(+).672-5(= 222
2SSE
5=2.5)-1(+2.5)-2(+2.5)-3(+).52-4(= 2222
3SSE
Accumulated weight variance SSE ∑=
i
iSSE
67.15=5+67.8+2=SSE](https://image.slidesharecdn.com/datapre-processing-170313100854-170315122804/85/Data-pre-processing-40-320.jpg)
![41
Value 1 2 3 4 5 6 7 8 9
Frequen
cy
2 4 5 2 1 4 3 2 1
Bucket Frequency
[1,3] 11
[4,5] 3
[6,9] 10
MaxDiff Histogram
Histogram
0
2
4
6
8
10
12
[1,3] [4,5] [6,9]
Bucket
Frequency](https://image.slidesharecdn.com/datapre-processing-170313100854-170315122804/85/Data-pre-processing-41-320.jpg)





![47
A dataset has 64 records, among which 16 records
belong to c1 and 48 records belong to c2
p(c1) = 16/64 =0.25
p(c2) = 48/64 = 0.75
H(D) = -[0.25·log2(0.25) + 0.75·log2(0.75)] = 0.811](https://image.slidesharecdn.com/datapre-processing-170313100854-170315122804/85/Data-pre-processing-47-320.jpg)

![49
A dataset D has 64 records, among which 16 records belong to c1 and 48
records belong to c2
(1) D is divided into two intervals: D1 has 45 records (2 belonging to c1 and 43
belonging to c2) and D2 has 19 records (14 belonging to c1 and 5 belonging
to c2)
(2) D is divided into two intervals: D3 has 40 records (10 belonging to c1 and 30
belonging to c2) and D4 has 24 records (6 belonging to c1 and 18 belonging
to c2)(1)
H(D1) = -[2/45*log2(2/45)+43/45*log2(43/45)] =
0.2623
H(D2) = -[14/19*log2(14/19)+5/19*log2(5/19)] =
0.8315
H(D,T1) = (45/64)*0.2623+(19/64)*0.8315 = 0.4313
(2)
H(D3) = -[10/40*log2(10/40)+30/40*log2(30/40)] =
0.8113
H(D4) = -[6/24*log2(6/24)+18/24*log2(18/24)] =
0.8113
H(D,T2) = (40/64)*0.8113+(24/64)*0.8113 = 0.8113
H(D,T1) < H(D,T2), so T1 is better than T2](https://image.slidesharecdn.com/datapre-processing-170313100854-170315122804/85/Data-pre-processing-49-320.jpg)

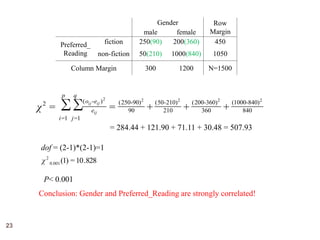
The document discusses various techniques for data pre-processing. It begins by explaining why pre-processing is important for obtaining clean and consistent data needed for quality data mining results. It then covers topics such as data cleaning, integration, transformation, reduction, and discretization. Data cleaning involves techniques for handling missing values, outliers, and inconsistencies. Data integration combines data from multiple sources. Transformation techniques include normalization, aggregation, and generalization. Data reduction aims to reduce data volume while maintaining analytical quality. Discretization includes binning of continuous variables.















































































