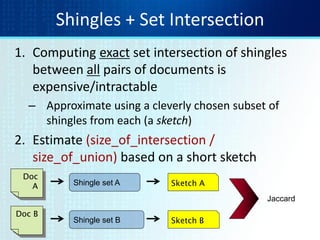
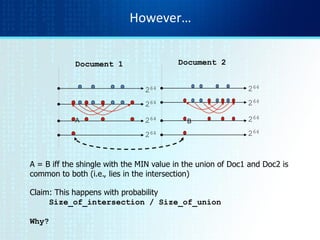
The document discusses techniques for detecting duplicate and near-duplicate documents. It describes how near duplicates can be identified by computing syntactic similarity using measures like edit distance. Shingling transforms documents into sets of n-grams that can be used for similarity comparisons. Sketches provide a compact representation of a document's shingles using a subset chosen by permutations, allowing efficient estimation of resemblance between documents. MinHash signatures exploit the relationship between resemblance of sets and the probability of matching minhash values to detect near duplicates in one pass over the data.








![Multiple Sketches
• Let pi be a random permutation on 0..2m
• For doc D, sketchD[ i ] is as follows:
– Let f map all shingles in the universe to 0..2m (e.g.,
f = fingerprinting)
– Let pi be a random permutation on 0..2m
– Pick MIN {pi(f(s))} over all shingles s in D](https://image.slidesharecdn.com/tutorial4duplicatedetection-130928091933-phpapp02/85/Tutorial-4-duplicate-detection-9-320.jpg)
![Computing Sketch[i] for Doc1
Document 1
264
264
264
264
Start with 64-bit f(shingles)
Permute on the number line
with pi
Pick the min value](https://image.slidesharecdn.com/tutorial4duplicatedetection-130928091933-phpapp02/85/Tutorial-4-duplicate-detection-10-320.jpg)
![Test if Doc1.Sketch[i] = Doc2.Sketch[i]
Document 1 Document 2
264
264
264
264
264
264
264
264
Are these equal?
Test for 200 random permutations: p1, p2,… p200
A B](https://image.slidesharecdn.com/tutorial4duplicatedetection-130928091933-phpapp02/85/Tutorial-4-duplicate-detection-11-320.jpg)



![Min-Hash sketches
• Pick P random row permutations
• MinHash sketch
SketchD = list of P indexes of first rows with 1 in
column C
• Similarity of signatures
– Let sim[sketch(Ci),sketch(Cj)] = fraction of
permutations where MinHash values agree
– Observe E[sim(sig(Ci),sig(Cj))] = Jaccard(Ci,Cj)](https://image.slidesharecdn.com/tutorial4duplicatedetection-130928091933-phpapp02/85/Tutorial-4-duplicate-detection-16-320.jpg)




















































![[2014 CodeEngn Conference 11] 김기홍 - 빅데이터 기반 악성코드 자동 분석 플랫폼](https://cdn.slidesharecdn.com/ss_thumbnails/2014codeengnconference11-141202123608-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)


















































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)

