Download as PDF, PPTX

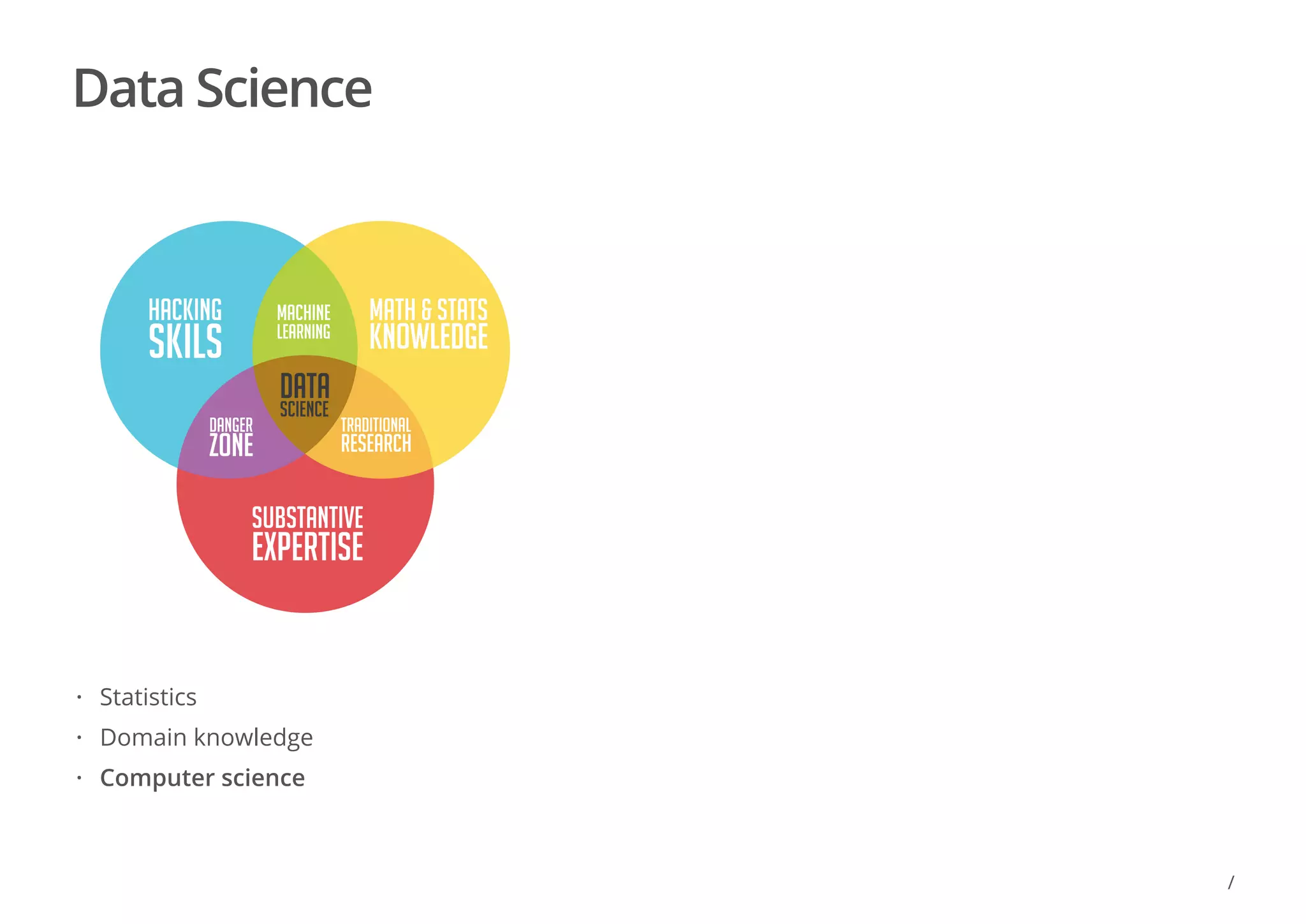













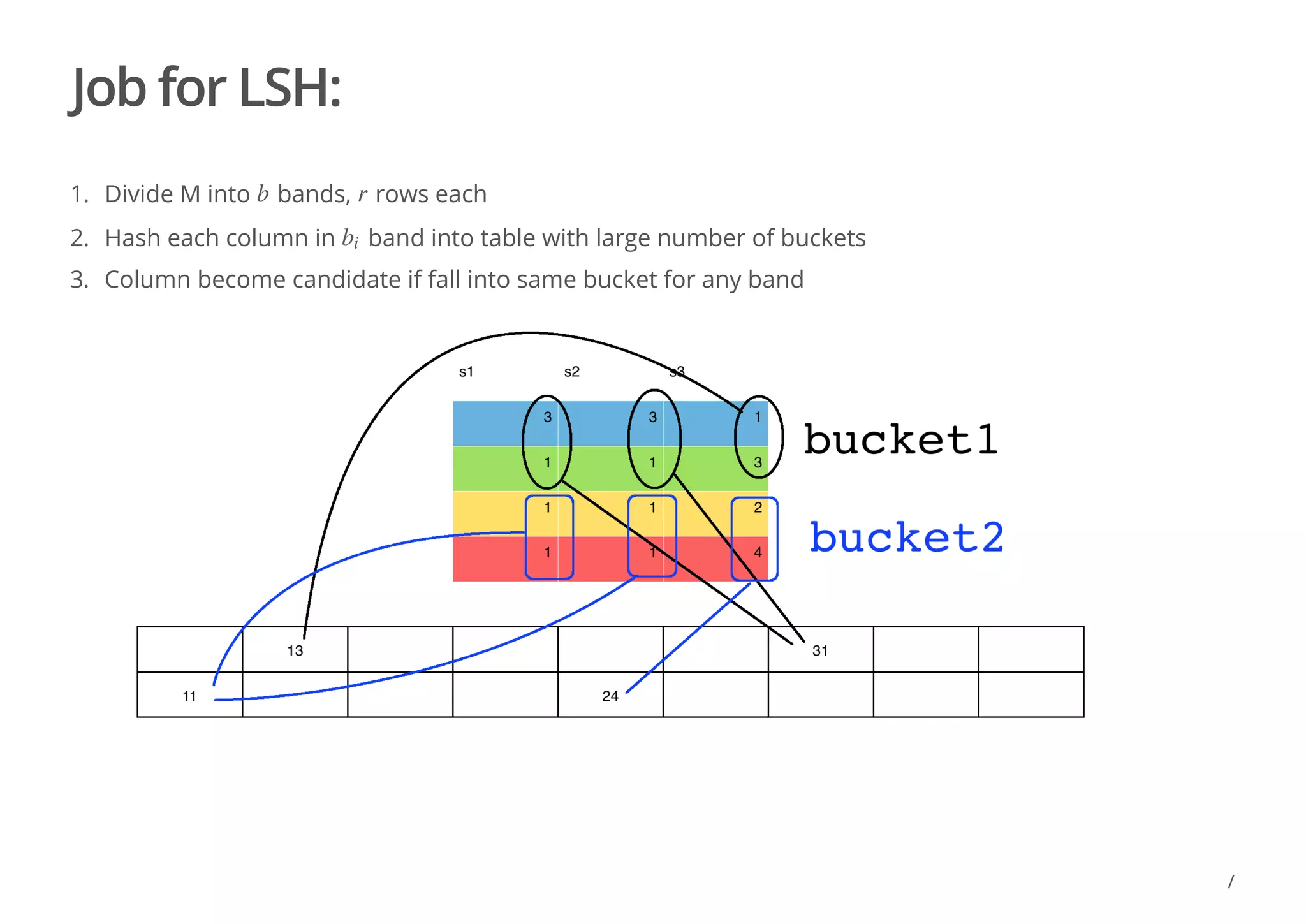





The document discusses locality sensitive hashing (LSH) as a solution for finding similar items in high-dimensional spaces, particularly for tasks such as near-duplicate detection and recommender systems. It outlines challenges like the curse of dimensionality and the need for efficient algorithms to manage large datasets using techniques like shingling and minhashing. Additionally, the document covers LSH implementation, candidate generation, and the probability of signature agreement across bands for effective similarity detection.























































































