Downloaded 42 times















![19
How to select a good k
• How to measure the “goodness”?
– Minimize the timec + E[timeFP ]under the space constraint
• Let’s investigate how the query time and space usage will
react when we increase k](https://image.slidesharecdn.com/lsh-131205223353-phpapp02/75/LSH-19-2048.jpg)



![1. Determine the largest possible value kmax for k without
violating the space constraint
2. Find k* in [1..kmax] mininizing timec(k) + E[timeFP(k)]
– In practice, timec and timeFP is measured experimentally by
• constructing a data structure T
• running several queries sampled from S on T
Procedure for optimizing k](https://image.slidesharecdn.com/lsh-131205223353-phpapp02/75/LSH-23-2048.jpg)
![• Let ∆ 𝑘time 𝑐 = timec(k) – timec(k-1)
• Let ∆ 𝑘timeFP = E[timeFP(k-1)] – E[timeFP(k)]
• Observation:
– If ∆ 𝑘time𝑐 is increasing and ∆ 𝑘timeFP is decreasing, then k*
would be the largest k such that ∆ 𝑘timeFP > ∆ 𝑘time 𝑐 and can
be found using binary search.
• Question:
– in which situation will ∆ 𝑘timeFP = E[timeFP(k-1)] – E[timeFP(k)] be increasing?
Observation & Question
k
∆ 𝑘time 𝑐
∆ 𝑘timeFP](https://image.slidesharecdn.com/lsh-131205223353-phpapp02/75/LSH-24-2048.jpg)







Locality sensitive hashing (LSH) is a technique to improve the efficiency of near neighbor searches in high-dimensional spaces. LSH works by hash functions that map similar items to the same buckets with high probability. The document discusses applications of near neighbor searching, defines the near neighbor reporting problem, and introduces LSH. It also covers techniques like gap amplification to improve LSH performance and parameter optimization to minimize query time.
Introduction to Locality Sensitive Hashing with applications in near neighbor reporting.
Discusses real-world applications: recommendation systems and malicious website detection.
Covers nearest neighbor searching and approximate nearest neighbor techniques, highlighting classical results.
Overview of the presentation’s structure, involving near neighbor reporting and the locality sensitive hashing concepts.
Details the formal and relaxed formulations of near neighbor reporting with goals and input specifications.
Defines LSH informally and formally, emphasizing its sensitivity criteria in hash functions.
Applying LSH to angular distance and Jaccard distance using random projections and MinHash.
Randomized algorithm for NNR using LSH, detailing the construction of hash tables and query time calculations.
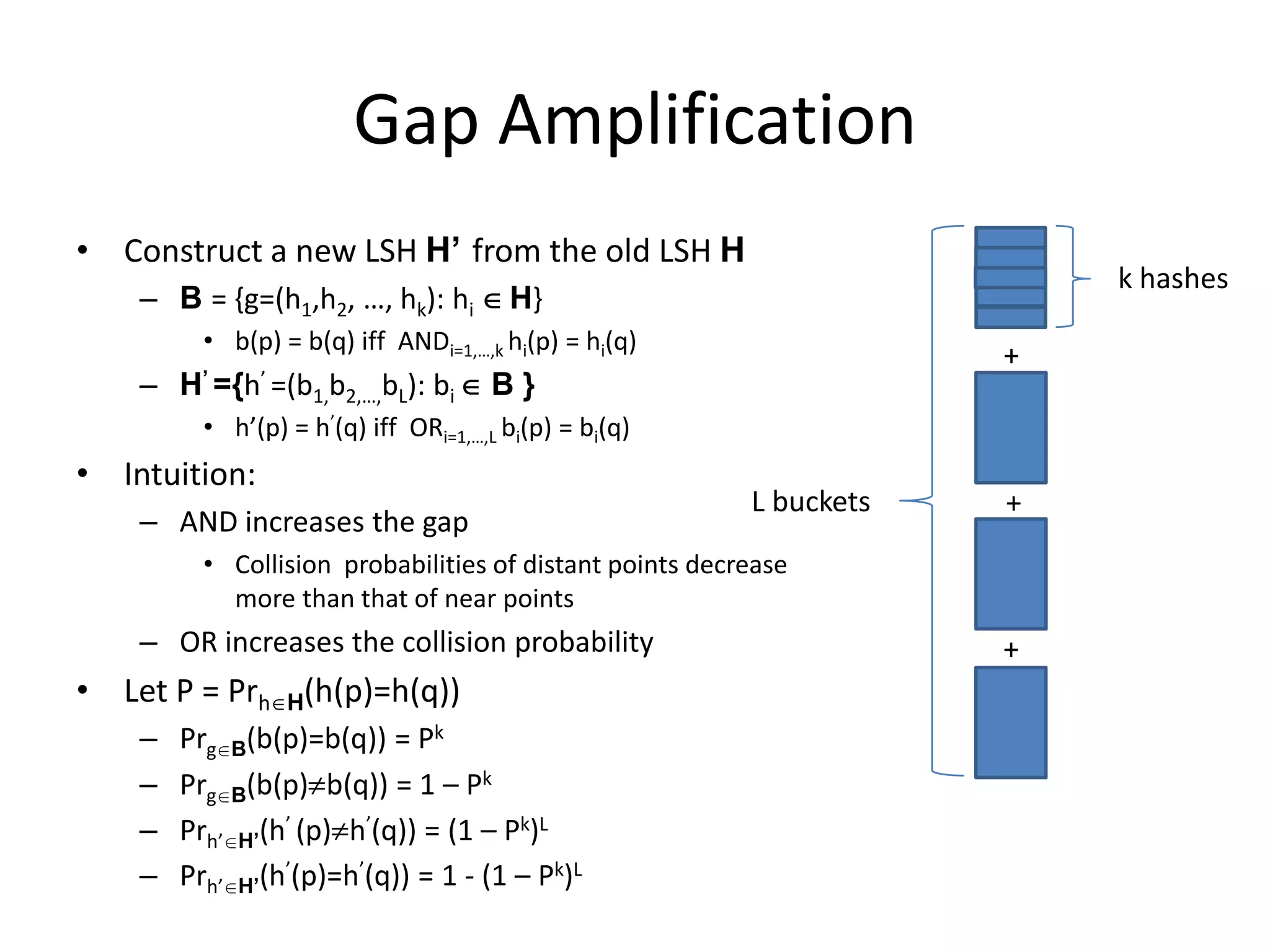
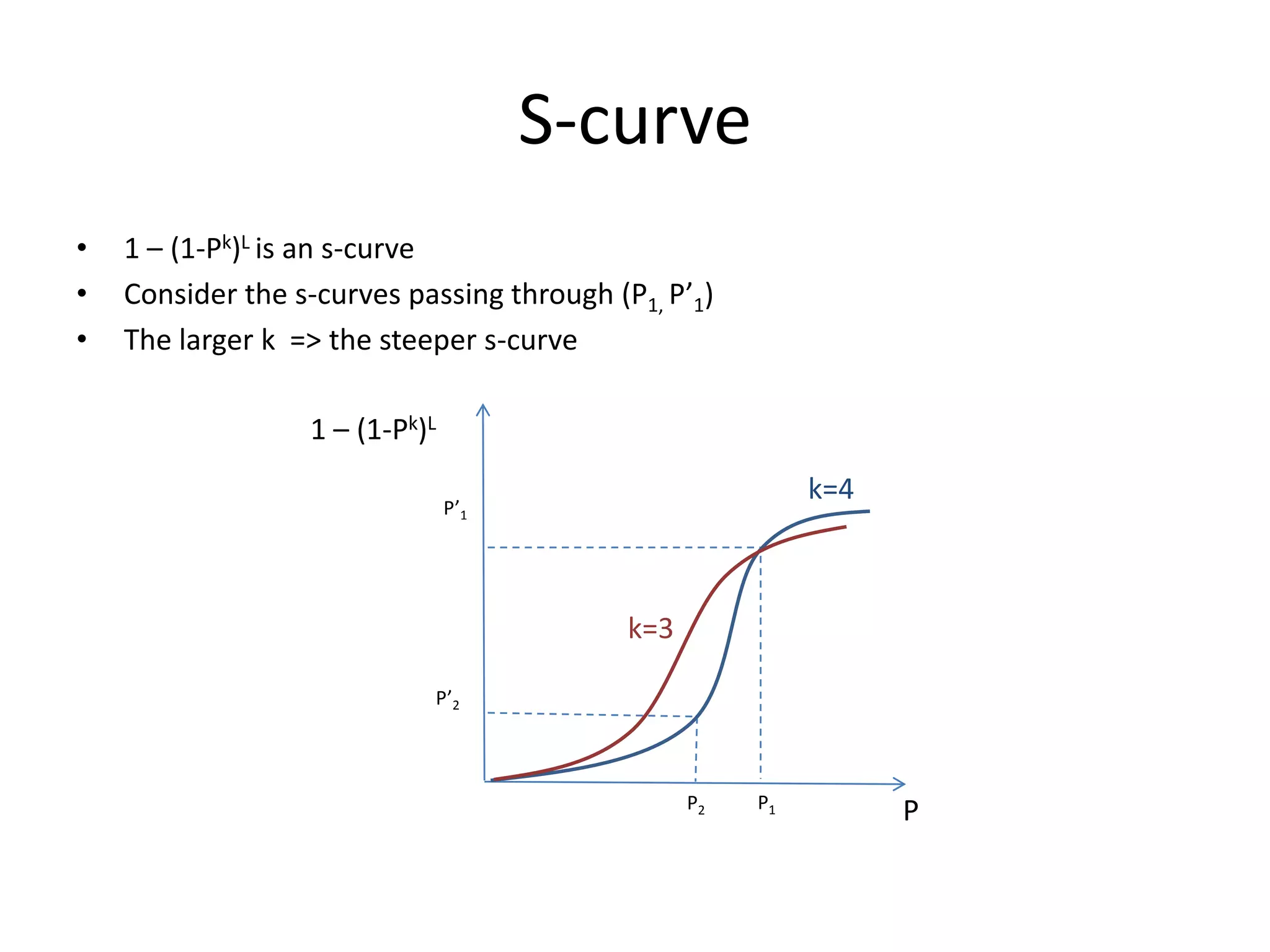
Describes enhancement techniques like gap amplification and parameter optimization for improved query performance.
Summarizes the importance of near neighbor reporting, LSH techniques, and performance tuning methods.
Presents various dimensionality reduction techniques such as PCA, SVD, and ISOMAP.
Lists references for further exploration of concepts discussed in the presentation.
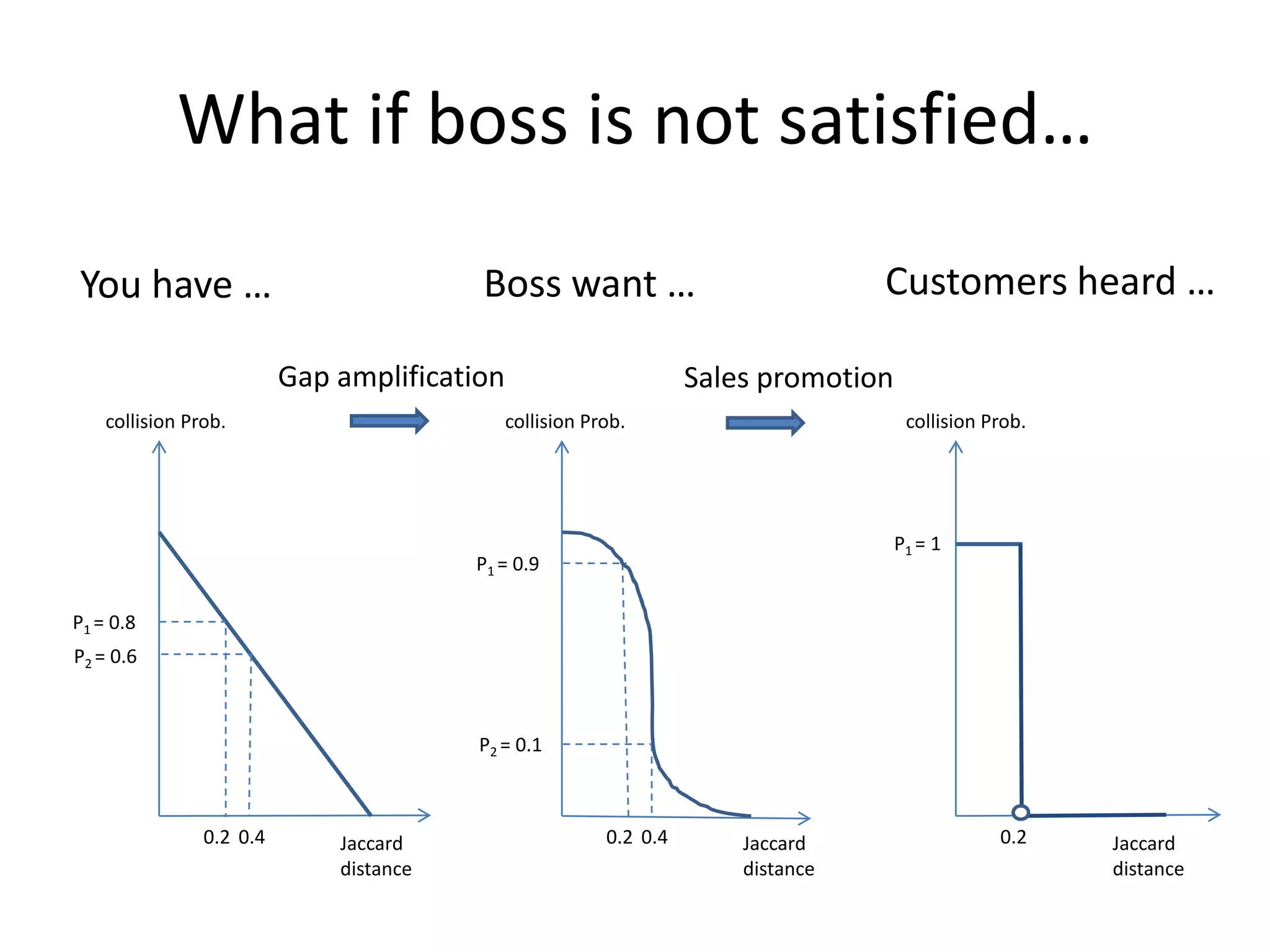
Discusses amplification of LSH and its impact on bucket number and collision error in detail.























































![[BDD 2025 - Mobile Development] Crafting Immersive UI with E2E and AGSL Shade...](https://cdn.slidesharecdn.com/ss_thumbnails/md-craftingimmersiveuiwithe2eandagslshaderveronicaputrianggraini-251124030840-0c677f44-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Full-Stack Development] The Modern Stack: Building Web & AI Appli...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-themodernstackbuildingwebaiapplicationswithserverless-251124030844-388cf04f-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Artificial Intelligence] Building AI Systems That Users (and Comp...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-buildingaisystemsthatusersandcompanieslove-251124030845-038f7732-thumbnail.jpg?width=640&height=640&fit=bounds)



![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)




