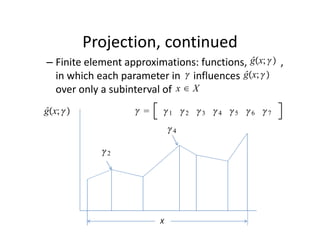
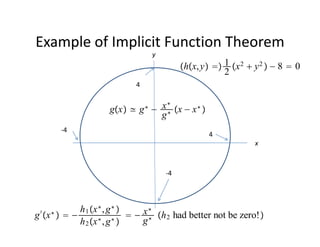
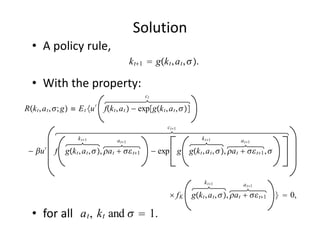
The document discusses methods for solving dynamic stochastic general equilibrium (DSGE) models. It outlines perturbation and projection methods for approximating the solution to DSGE models. Perturbation methods use Taylor series approximations around a steady state to derive linear approximations of the model. Projection methods find parametric functions that best satisfy the model equations. The document also provides an example of applying the implicit function theorem to derive a Taylor series approximation of a policy rule for a neoclassical growth model.
























































![Lecture on nk [compatibility mode]](https://cdn.slidesharecdn.com/ss_thumbnails/lectureonnkcompatibilitymode-110825092241-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)


































































