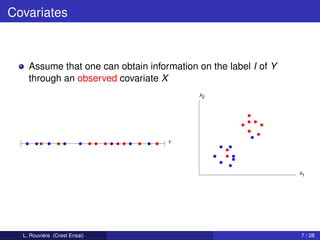
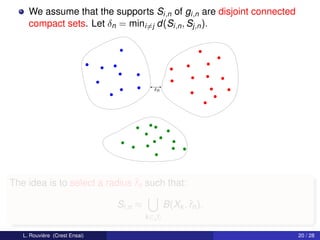
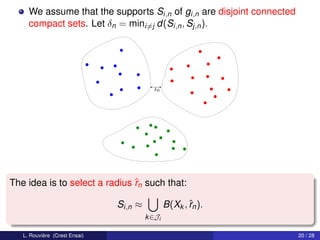
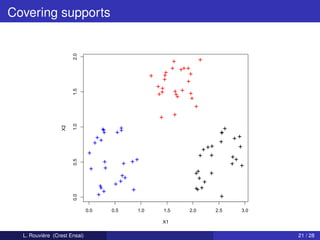
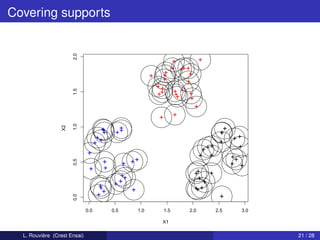
This document describes a clustering procedure and nonparametric mixture estimation. It introduces a mixture density model where the goal is to efficiently estimate the mixture weights (αi) and component densities (fi). A two-stage clustering algorithm is proposed: 1) perform clustering on covariates (X) to estimate labels (Ik), and 2) estimate component densities (fi) using kernel density estimation within each cluster. The performance of this approach depends on the clustering method's misclassification error. A toy example with two components having disjoint support densities for X is provided to illustrate the model.
























![A toy example
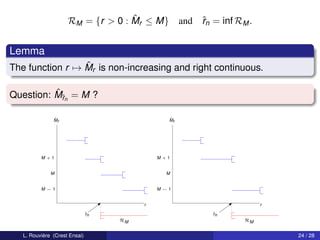
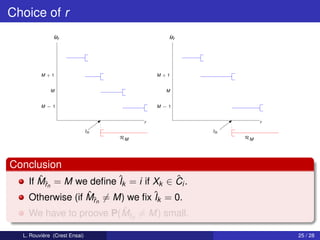
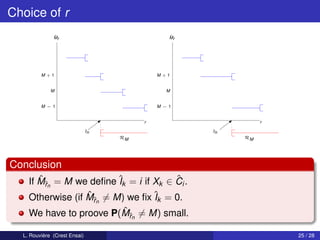
Here M = 2 and the conditionnal distributions gi,n are given by
g1,n (x) = g1 (x) = 1[0,1] (x) and g2,n (x) = 1[1−λn ,2−λn ] (x).
L. Rouvière (Crest Ensai) 12 / 28](https://image.slidesharecdn.com/rouviere-130228114145-phpapp01/85/Rouviere-25-320.jpg)
![A toy example
Here M = 2 and the conditionnal distributions gi,n are given by
g1,n (x) = g1 (x) = 1[0,1] (x) and g2,n (x) = 1[1−λn ,2−λn ] (x).
Ik = 1 Ik = 1 or 2 Ik = 2
ˆ = 1
Ik ˆ = 0
Ik ˆ = 2
Ik
0 1 2
λn λn
ˆ
λn ˆ
λn
L. Rouvière (Crest Ensai) 12 / 28](https://image.slidesharecdn.com/rouviere-130228114145-phpapp01/85/Rouviere-26-320.jpg)
![A toy example
Here M = 2 and the conditionnal distributions gi,n are given by
g1,n (x) = g1 (x) = 1[0,1] (x) and g2,n (x) = 1[1−λn ,2−λn ] (x).
Ik = 1 Ik = 1 or 2 Ik = 2
ˆ = 1
Ik ˆ = 0
Ik ˆ = 2
Ik
0 1 2
λn λn
ˆ
λn ˆ
λn
L. Rouvière (Crest Ensai) 12 / 28](https://image.slidesharecdn.com/rouviere-130228114145-phpapp01/85/Rouviere-27-320.jpg)




![Lipschitz class
Definition
Let s ∈ N and C > 0. We call W(s, C) the Lipschitz with parameters
s, C the class of all densities on [0, 1] with s − 1 asolutely continous
derivatives for which for all x, y ∈ R,
|f (s) (x) − f (s) (y )| ≤ C|x − y |.
Optimal rate
The minimax L1 risk for compactly supported Lipschitz class W(s, L) is
of order n−s/(2s+1) (see Devroye and Györfi, 1985).
L. Rouvière (Crest Ensai) 15 / 28](https://image.slidesharecdn.com/rouviere-130228114145-phpapp01/85/Rouviere-32-320.jpg)
![Lipschitz class
Definition
Let s ∈ N and C > 0. We call W(s, C) the Lipschitz with parameters
s, C the class of all densities on [0, 1] with s − 1 asolutely continous
derivatives for which for all x, y ∈ R,
|f (s) (x) − f (s) (y )| ≤ C|x − y |.
Optimal rate
The minimax L1 risk for compactly supported Lipschitz class W(s, L) is
of order n−s/(2s+1) (see Devroye and Györfi, 1985).
L. Rouvière (Crest Ensai) 15 / 28](https://image.slidesharecdn.com/rouviere-130228114145-phpapp01/85/Rouviere-33-320.jpg)



![Here M = 2 and the conditionnal distributions gi,n are given by
g1,n (x) = g1 (x) = 1[0,1] (x) and g2,n (x) = 1[1−λn ,2−λn ] (x).
L. Rouvière (Crest Ensai) 18 / 28](https://image.slidesharecdn.com/rouviere-130228114145-phpapp01/85/Rouviere-37-320.jpg)
![Here M = 2 and the conditionnal distributions gi,n are given by
g1,n (x) = g1 (x) = 1[0,1] (x) and g2,n (x) = 1[1−λn ,2−λn ] (x).
Ik = 1 Ik = 1 or 2 Ik = 2
ˆ = 1
Ik ˆ = 0
Ik ˆ = 2
Ik
0 1 2
λn λn
ˆ
λn ˆ
λn
L. Rouvière (Crest Ensai) 18 / 28](https://image.slidesharecdn.com/rouviere-130228114145-phpapp01/85/Rouviere-38-320.jpg)
![Here M = 2 and the conditionnal distributions gi,n are given by
g1,n (x) = g1 (x) = 1[0,1] (x) and g2,n (x) = 1[1−λn ,2−λn ] (x).
Ik = 1 Ik = 1 or 2 Ik = 2
ˆ = 1
Ik ˆ = 0
Ik ˆ = 2
Ik
0 1 2
λn λn
ˆ
λn ˆ
λn
ˆ
We choose λn = 2 − X(n) and
ˆ
1 if Xk ≤ 1 − λn
ˆk = 0 if 1 − λn < Xk < 1
I ˆ
2 if Xk ≥ 1.
L. Rouvière (Crest Ensai) 18 / 28](https://image.slidesharecdn.com/rouviere-130228114145-phpapp01/85/Rouviere-39-320.jpg)
![Here M = 2 and the conditionnal distributions gi,n are given by
g1,n (x) = g1 (x) = 1[0,1] (x) and g2,n (x) = 1[1−λn ,2−λn ] (x).
Ik = 1 Ik = 1 or 2 Ik = 2
ˆ = 1
Ik ˆ = 0
Ik ˆ = 2
Ik
0 1 2
λn λn
ˆ
λn ˆ
λn
ˆ
We choose λn = 2 − X(n) and
ˆ
1 if Xk ≤ 1 − λn
ˆk = 0 if 1 − λn < Xk < 1
I ˆ
2 if Xk ≥ 1.
Find an upper boud of
ϕn = max max P(ˆk = j|Ik = j).
I
1≤k ≤n 1≤i≤M
L. Rouvière (Crest Ensai) 18 / 28](https://image.slidesharecdn.com/rouviere-130228114145-phpapp01/85/Rouviere-40-320.jpg)


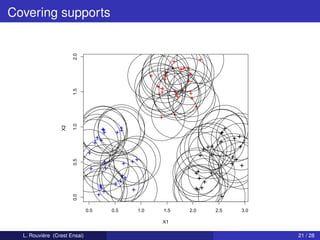
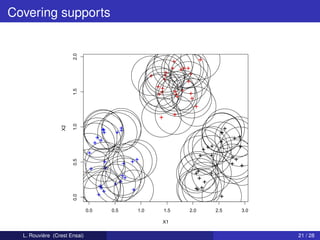
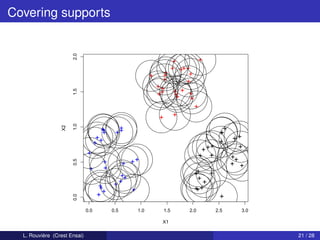
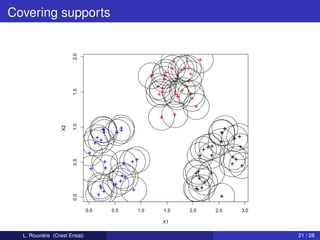













![Example
Corollary
Assume that gi,n are univariate densities and
tn = n−γ , γ ∈]0, 1[.
Then the kernel density estimate ˆi achieves the optimal rate over the
f
class W(s, L) provided
1/d
(log n)2
δn > 2 .
n1−γ
L. Rouvière (Crest Ensai) 28 / 28](https://image.slidesharecdn.com/rouviere-130228114145-phpapp01/85/Rouviere-67-320.jpg)
![H2
H2 implies that the covering number M should verify
n
N ≤ (c1 c2 )−1 .
(log n)2
H2 is clearly satisfied for d = 1.
However for higher dimensions, even if Sn is assumed to be
compact, its diameter can be as large as we want
hn (x, y ) = 1[1−a−1 ,an ] (x)1[0,1/x 2 ] (y ).
n
L. Rouvière (Crest Ensai) 29 / 28](https://image.slidesharecdn.com/rouviere-130228114145-phpapp01/85/Rouviere-68-320.jpg)







![11.[104 111]analytical solution for telegraph equation by modified of sumudu ...](https://cdn.slidesharecdn.com/ss_thumbnails/11-104-111analyticalsolutionfortelegraphequationbymodifiedofsumudutransformelzakitransform-120513000219-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)

























































