Download to read offline

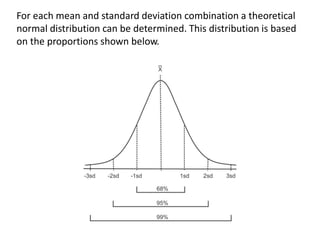
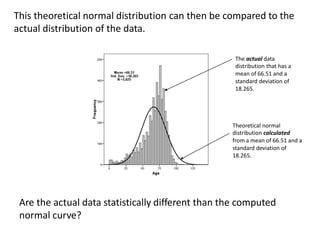

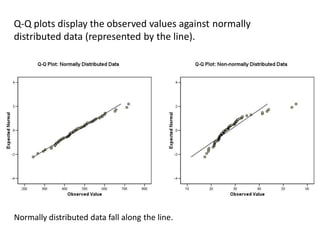
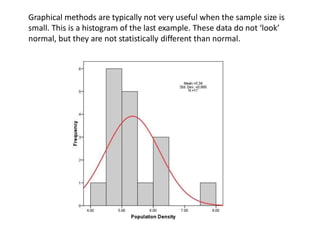



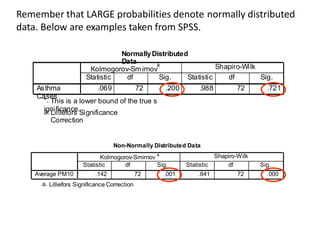

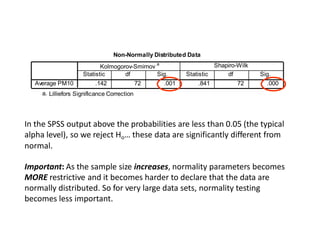


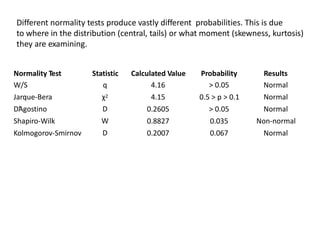






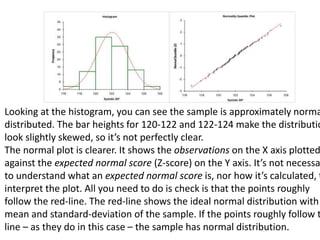

This document discusses testing for normality in statistical data. It describes comparing an actual data distribution to a theoretical normal distribution based on the data's mean and standard deviation. Several graphical and statistical tests for normality are presented, including Q-Q plots, Kolmogorov-Smirnov tests, and Shapiro-Wilk tests. Large p-values from these tests indicate the data are normally distributed, while small p-values show the data are non-normal. The document emphasizes that normality testing is more important for smaller sample sizes and provides guidelines for selecting an appropriate normality test.































































![ict_presentation_final_final_final[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/ictpresentationfinalfinalfinal1-251230145259-2b4839bd-thumbnail.jpg?width=640&height=640&fit=bounds)



