Download to read offline















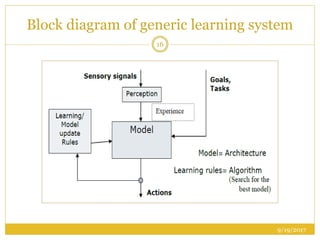
























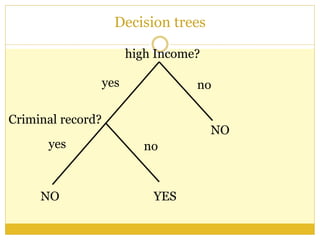
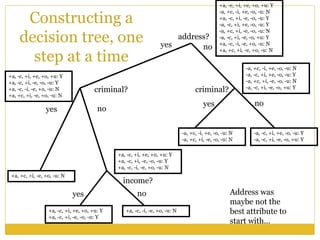
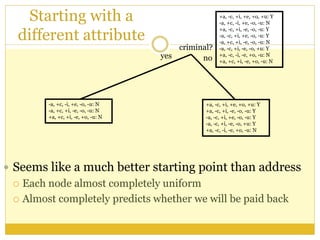












The document outlines foundational concepts of artificial intelligence (AI) and machine learning (ML), emphasizing the importance of learning from experience in AI applications. It distinguishes between deductive and inductive reasoning, explaining various learning types such as supervised, unsupervised, active, and reinforcement learning. Additionally, it discusses the critical role of machine learning in overcoming knowledge acquisition challenges and the significance of decision trees in making predictions based on learned data.























































































