Downloaded 202 times

























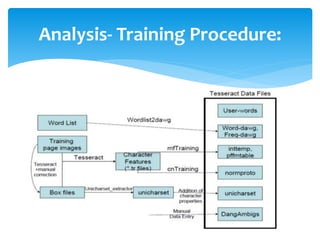

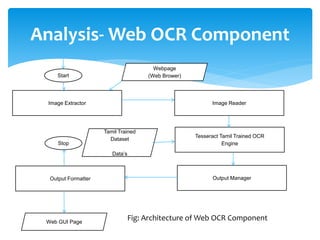


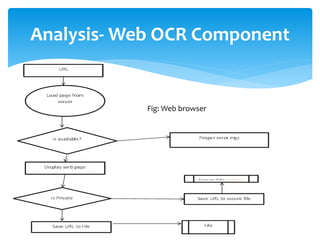

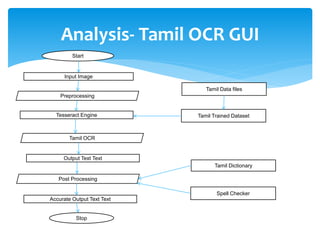
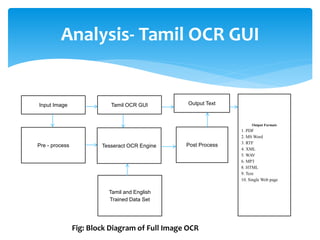
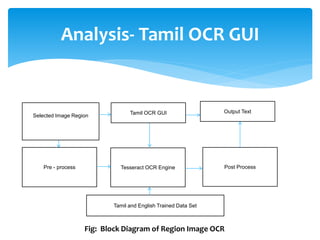
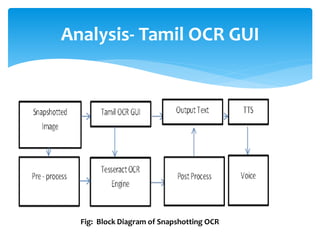
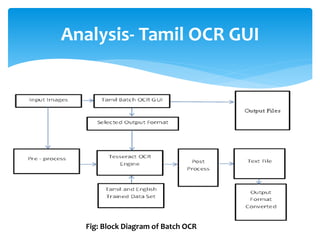
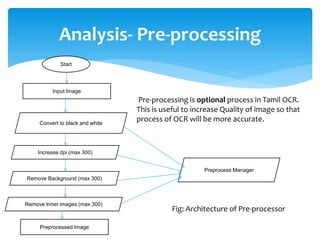








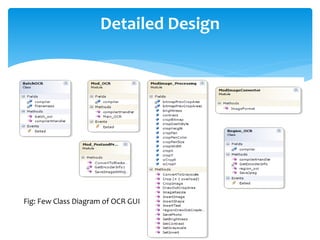
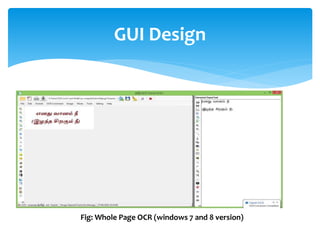
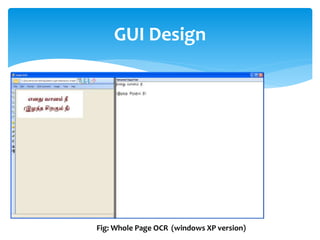
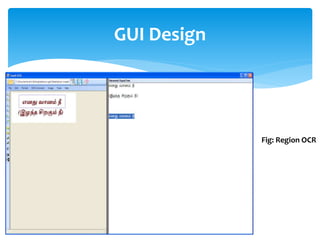
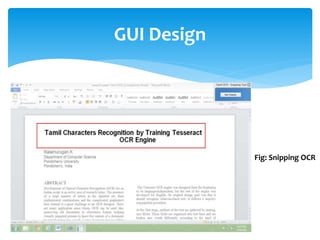
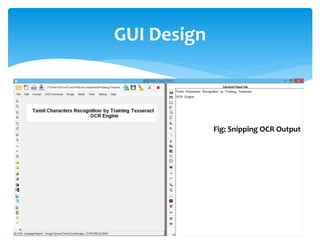
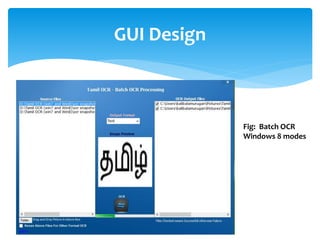
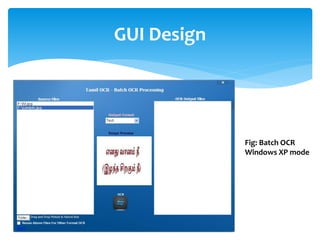
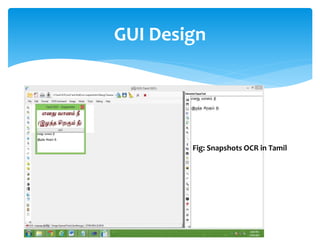
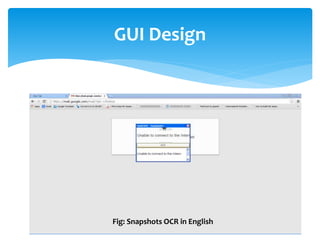

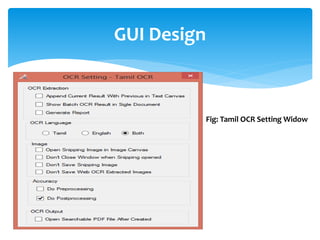

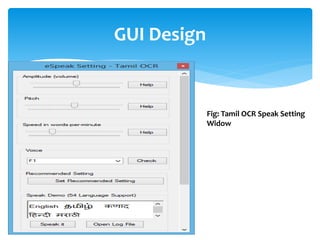
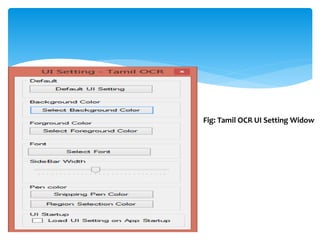
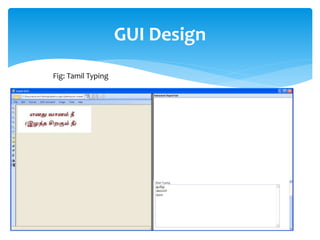
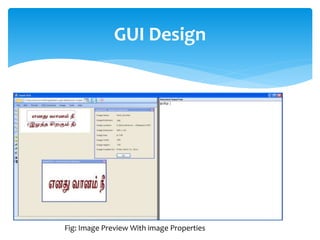

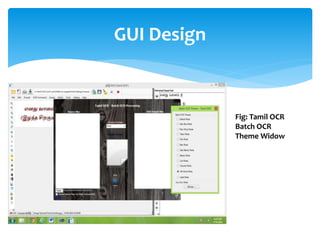
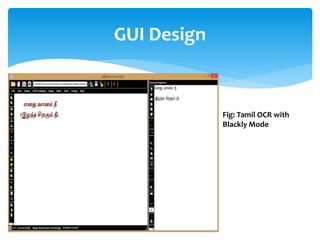
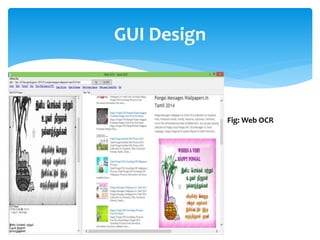
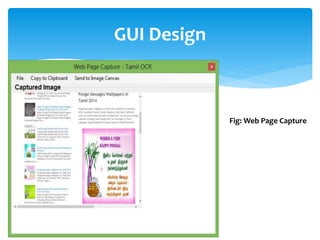
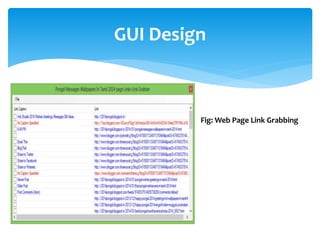
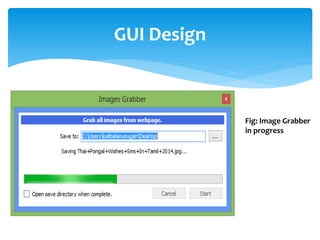
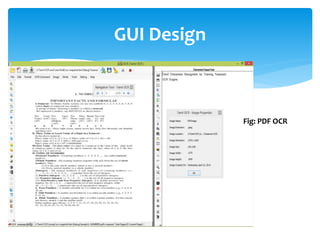
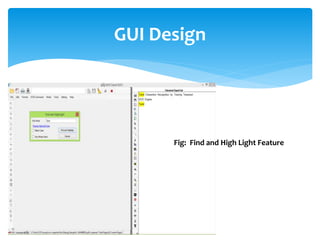
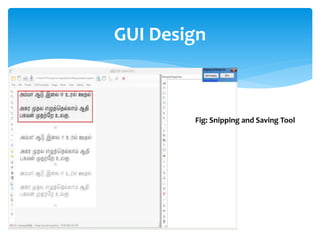

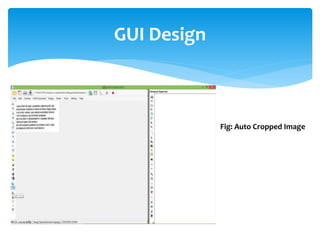
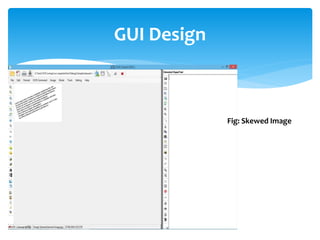








The document discusses a project titled 'Tamil OCR using Multidimensional Interactive Learning Model,' which involves developing an optical character recognition software specifically for Tamil language, utilizing the Tesseract OCR engine. It outlines the software and hardware requirements, discusses existing systems and the advantages of the developed GUI for ease of use, especially for visually impaired users. Additionally, it details the mechanics of the OCR process and training procedures for the Tesseract engine to accurately recognize Tamil characters.

































































































