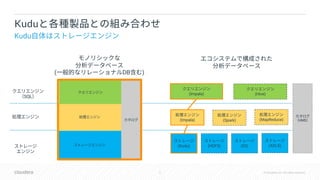
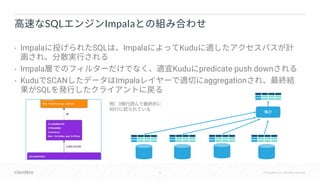
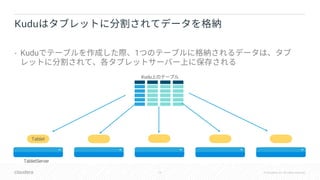
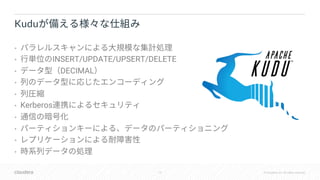
Downloaded 22 times


















![31 © Cloudera, Inc. All rights reserved.
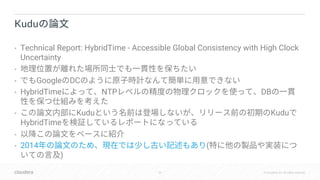
• Google Spanner DC
• Amazon Dynamo Cassandra DB
Eventual Consistency
•
•
•
[ ] DC DB](https://image.slidesharecdn.com/kudu-hybrid-timedbts2018-181015141706/85/DB-Apache-Kudu-DB-HybridTime-31-320.jpg)

![33 © Cloudera, Inc. All rights reserved.
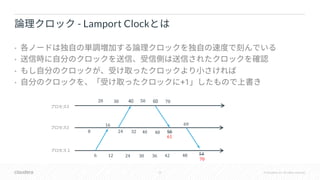
• Lamport Clocks Vector Clocks
•
•
•
• RDB Point-in-Time
• Vector Clocks
[ ]](https://image.slidesharecdn.com/kudu-hybrid-timedbts2018-181015141706/85/DB-Apache-Kudu-DB-HybridTime-33-320.jpg)
![34 © Cloudera, Inc. All rights reserved.
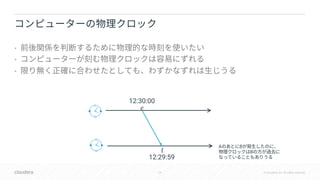
• Spinnaker Paxos
•
•
• Spanner commit-wait
•
• GPS
•
[ ]](https://image.slidesharecdn.com/kudu-hybrid-timedbts2018-181015141706/85/DB-Apache-Kudu-DB-HybridTime-34-320.jpg)
![35 © Cloudera, Inc. All rights reserved.
• HybridTime
•
•
• Pint-in-time
• Lamport Clock
• HybridTime
• Vector Clocks Lamport Clocks 2
( commit-wait )
[ ] HybridTime
HTC: { , }](https://image.slidesharecdn.com/kudu-hybrid-timedbts2018-181015141706/85/DB-Apache-Kudu-DB-HybridTime-35-320.jpg)

![37 © Cloudera, Inc. All rights reserved.
• !"# $ i e
• !"'() $ e
• *# $ i e
• 1:
• 2:
[ ] HybridTime](https://image.slidesharecdn.com/kudu-hybrid-timedbts2018-181015141706/85/DB-Apache-Kudu-DB-HybridTime-37-320.jpg)






![47 © Cloudera, Inc. All rights reserved.
• UPDATE
• 2
• HybridTime
+1
[ ] HybridTime](https://image.slidesharecdn.com/kudu-hybrid-timedbts2018-181015141706/85/DB-Apache-Kudu-DB-HybridTime-47-320.jpg)
![48 © Cloudera, Inc. All rights reserved.
• !" #, % !" HTC #, %
[ ] HybridTime](https://image.slidesharecdn.com/kudu-hybrid-timedbts2018-181015141706/85/DB-Apache-Kudu-DB-HybridTime-48-320.jpg)
![49 © Cloudera, Inc. All rights reserved.
• HTC
• HTC
• ) ! → #
• −%& ! < !(()( # < %* #
[ ] Kudu HybridTime
j
i
#
−%& !
%* #−%& !
!
%& !](https://image.slidesharecdn.com/kudu-hybrid-timedbts2018-181015141706/85/DB-Apache-Kudu-DB-HybridTime-49-320.jpg)



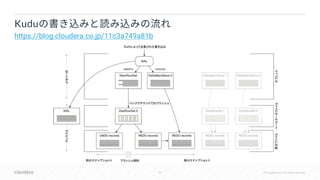
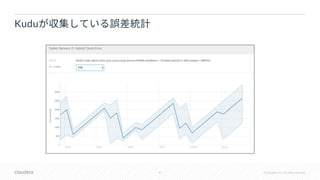
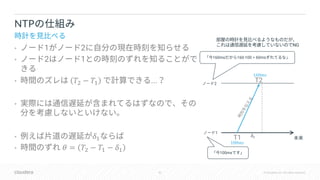
![54 © Cloudera, Inc. All rights reserved.
• YCSB
•
• 3 8
• insert 60%, update 20%, single-row read 20%
•
• GCE: nl-standard-8 x10
• RAM 30GB
• Disk 350GB
• NTP
• GCE
[ ]
NTP](https://image.slidesharecdn.com/kudu-hybrid-timedbts2018-181015141706/85/DB-Apache-Kudu-DB-HybridTime-54-320.jpg)
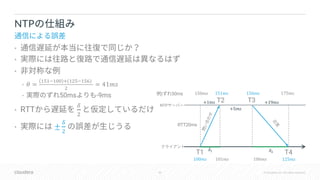
![55 © Cloudera, Inc. All rights reserved.
[ ]
HybridTime Commit Wait Commit Wait
Clock Error](https://image.slidesharecdn.com/kudu-hybrid-timedbts2018-181015141706/85/DB-Apache-Kudu-DB-HybridTime-55-320.jpg)



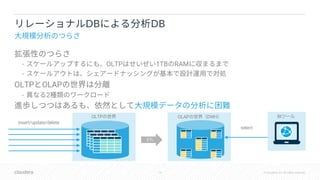
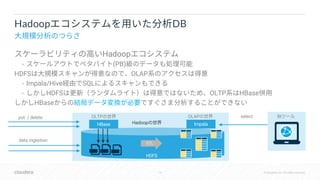
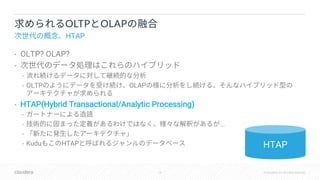
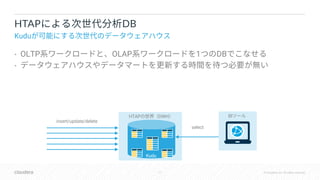
The document discusses Apache Kudu, a hybrid database designed for both OLTP and OLAP processing, emphasizing its HTAP (Hybrid Transactional/Analytic Processing) capabilities. It touches on integration with various tools like Impala and Spark, and delves into concepts such as consistency, hybridtime, and commit protocols. Additionally, it compares Kudu's features against other databases like Google Spanner, focusing on global consistency and clock synchronization issues.



















![[Cloudera World Tokyo 2018] Cloudera on Oracle Cloud Infrastructure](https://cdn.slidesharecdn.com/ss_thumbnails/clouderaonoraclecloudinfrastructure181105publish-181113073618-thumbnail.jpg?width=640&height=640&fit=bounds)


































































