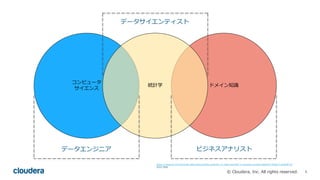
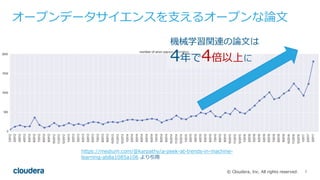
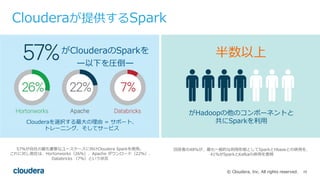
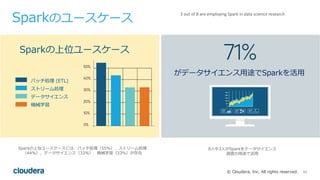
Cloudera Data Science WorkbenchとPySparkで 好きなPythonライブラリを 分散で使う #cadeda
Data Engineering and Data Analysis Workshop #1 での有賀 (@chezou)の発表です。
https://cyberagent.connpass.com/event/58808/
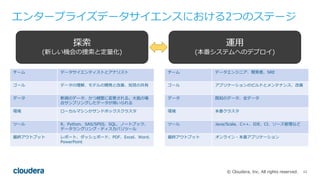
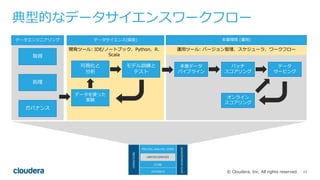
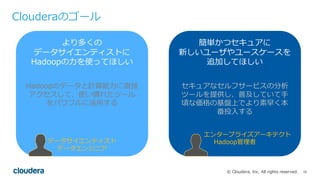
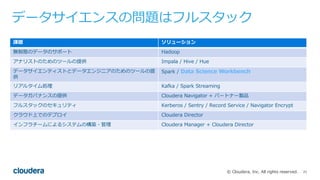
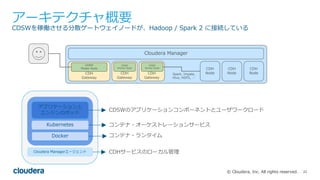
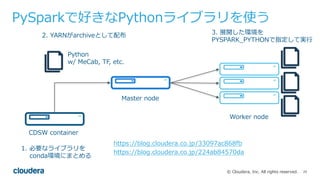
Cloudera Data Science WorkbenchとPySparkを使い、Pythonで好きなライブラリを分散実行する方法についてです。日本語の形態素解析ライブラリMeCabをPySparkから実行します。