Download as PDF, PPTX





![[Kafka] [Kinesis]
6](https://image.slidesharecdn.com/20160531kafkakinesispub-160601054833/85/Kafka-AWS-Kinesis-7-320.jpg)
![[Kafka] [Kinesis]
6](https://image.slidesharecdn.com/20160531kafkakinesispub-160601054833/85/Kafka-AWS-Kinesis-8-320.jpg)
![[Kafka] [Kinesis]
Kafka Connect
Kafka-rest
Kafka-Pixy
Kastle
AWS
API Gateway
HTTP API
ETL ETL 7](https://image.slidesharecdn.com/20160531kafkakinesispub-160601054833/85/Kafka-AWS-Kinesis-9-320.jpg)
![[Kafka] [Kinesis]
Kafka Connect
Kafka-rest
Kafka-Pixy
Kastle
AWS
API Gateway
HTTP API
ETL ETL
OSS
•Kafka Streams
•PipelineDB
AWS
•Kinesis Analytics
7](https://image.slidesharecdn.com/20160531kafkakinesispub-160601054833/85/Kafka-AWS-Kinesis-10-320.jpg)
![[Kafka] [Kinesis]
JMX Reporter
Kerberos
Cloudwatch
AWS
7
← →
← →
← →
8](https://image.slidesharecdn.com/20160531kafkakinesispub-160601054833/85/Kafka-AWS-Kinesis-11-320.jpg)
![[Kafka] [Kinesis]
JMX Reporter
Kerberos
Cloudwatch
AWS
7
← →
← →
← →
8](https://image.slidesharecdn.com/20160531kafkakinesispub-160601054833/85/Kafka-AWS-Kinesis-12-320.jpg)
![[ ]
http://insightdataengineering.com/blog/ingestion-comparison/
X](https://image.slidesharecdn.com/20160531kafkakinesispub-160601054833/85/Kafka-AWS-Kinesis-13-320.jpg)




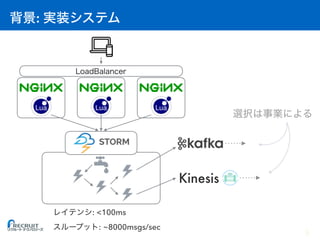
This document compares Apache Kafka and AWS Kinesis for message streaming. It outlines that Kafka is an open source publish-subscribe messaging system designed as a distributed commit log, while Kinesis provides streaming data services. It also notes some key differences like Kafka typically handling over 8000 messages/second while Kinesis can handle under 100 messages/second.















































































