Download as PDF, PPTX
















![Apache Druid - Batch Task
.
.
.
"pref
i
xes": [
"s3
:
/
/
sku/topics/skus/y=2022/m=09/"
],
.
.
.
"intervals": [
"2022-09-01T00
:
00
:
00/2022-10-01T00
:
00
:
00"
]
.
.
.](https://image.slidesharecdn.com/neilbuesingbr06220221004final-221023135950-f37e5f38/75/Don-t-Forget-About-Your-Past-Optimizing-Apache-Druid-Performance-With-Neil-Buesing-Current-2022-36-2048.jpg)

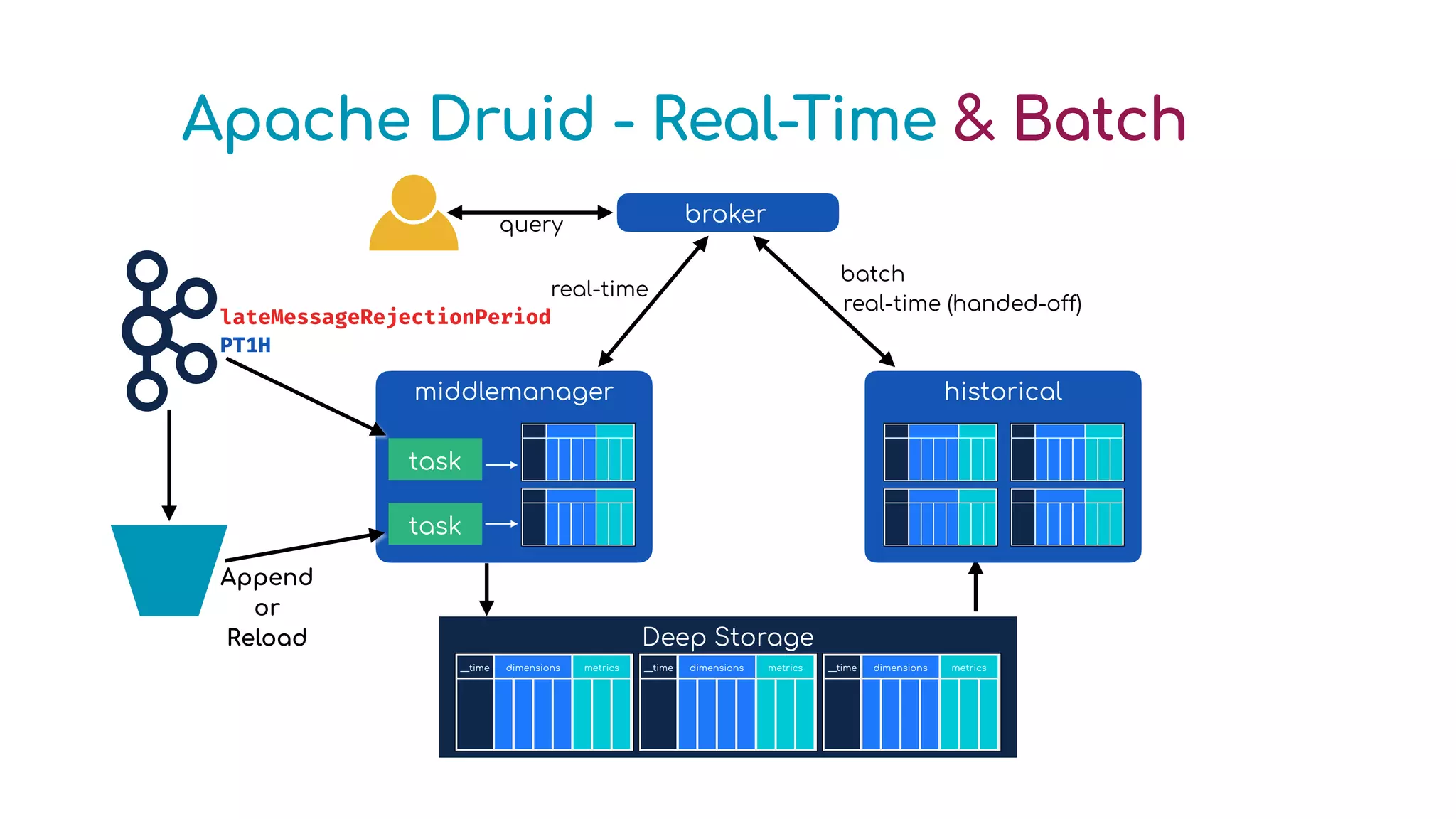



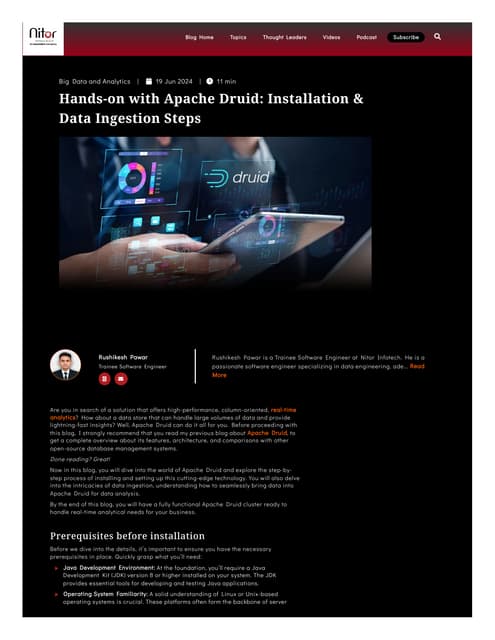
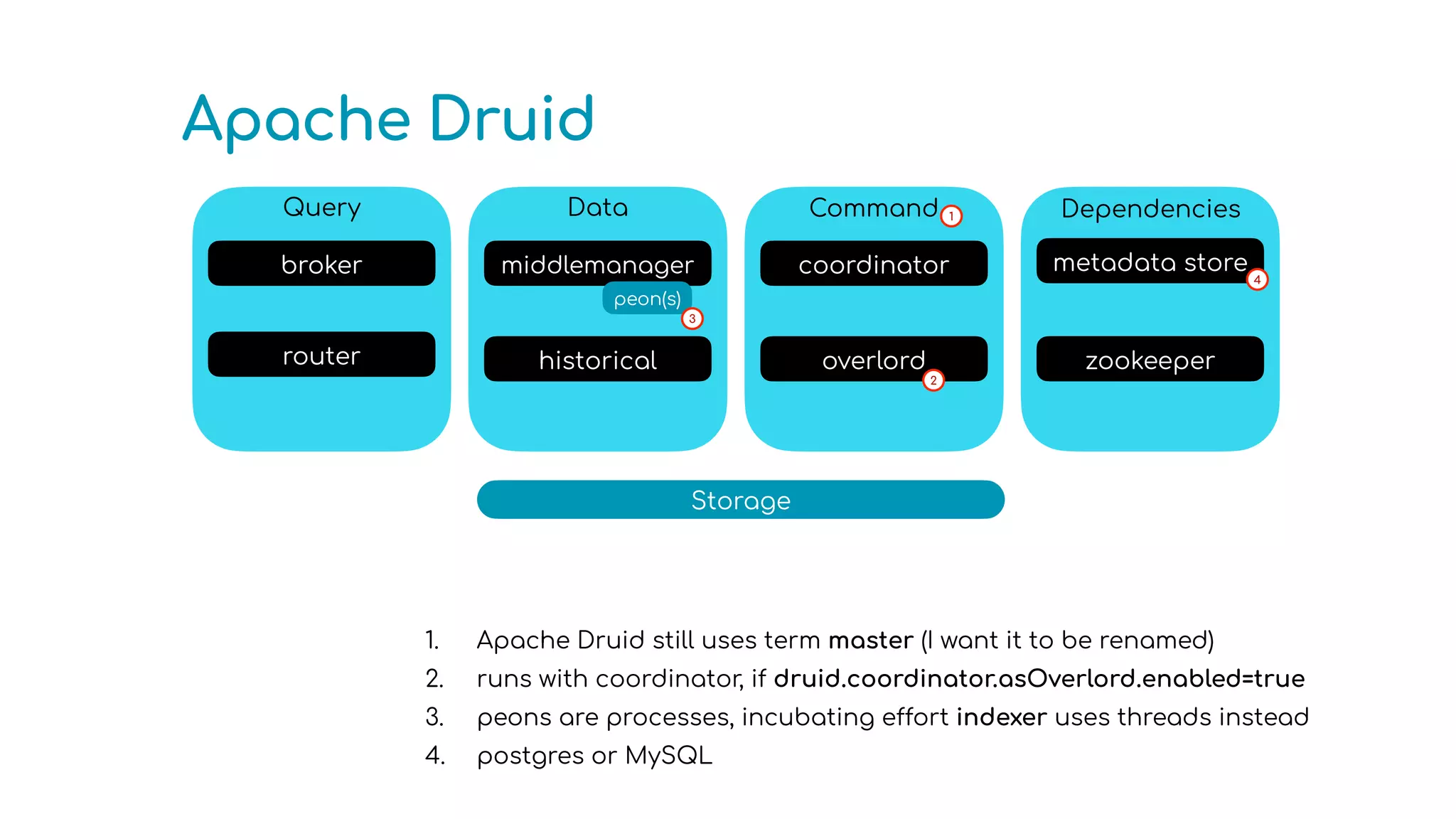
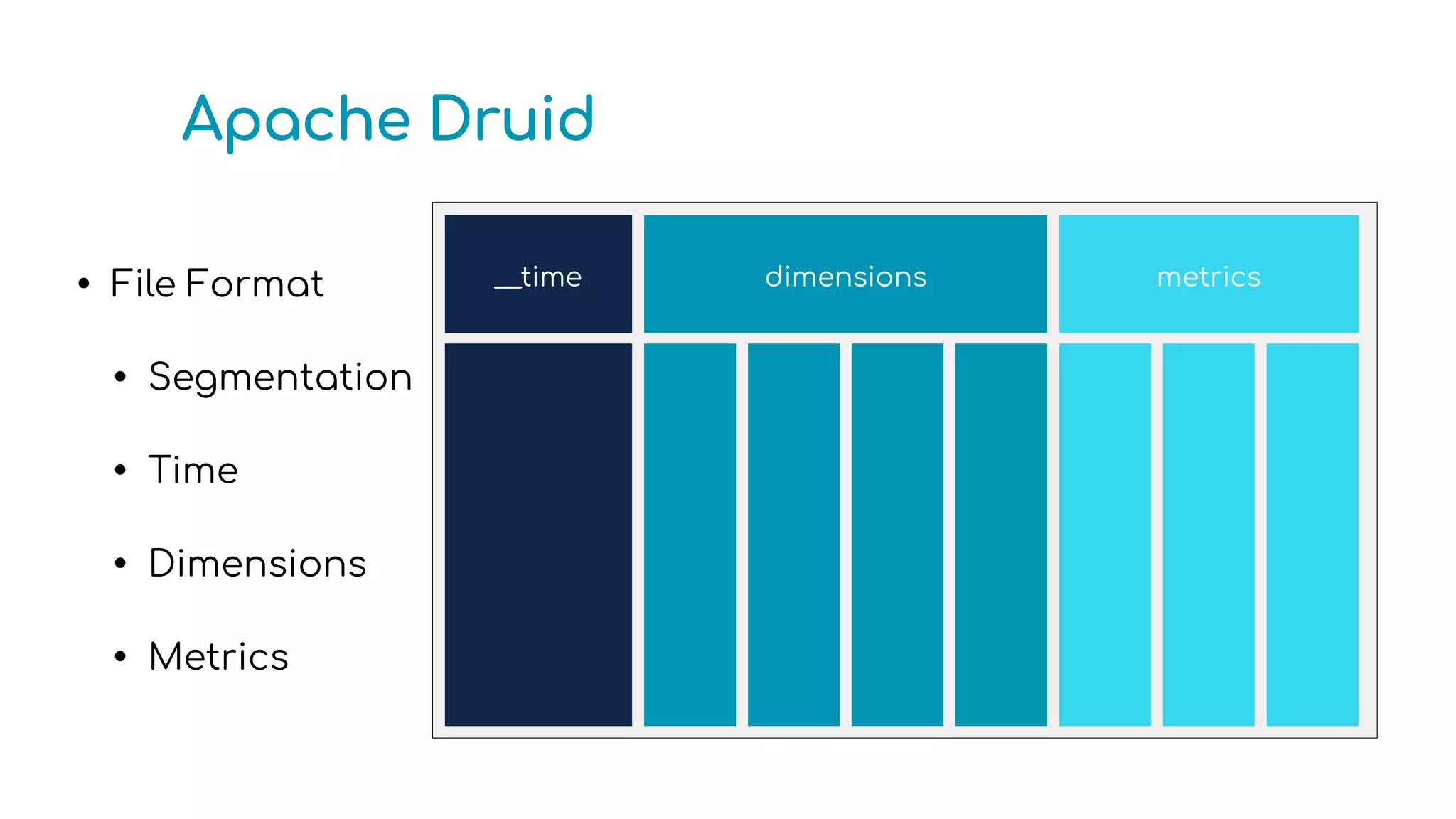
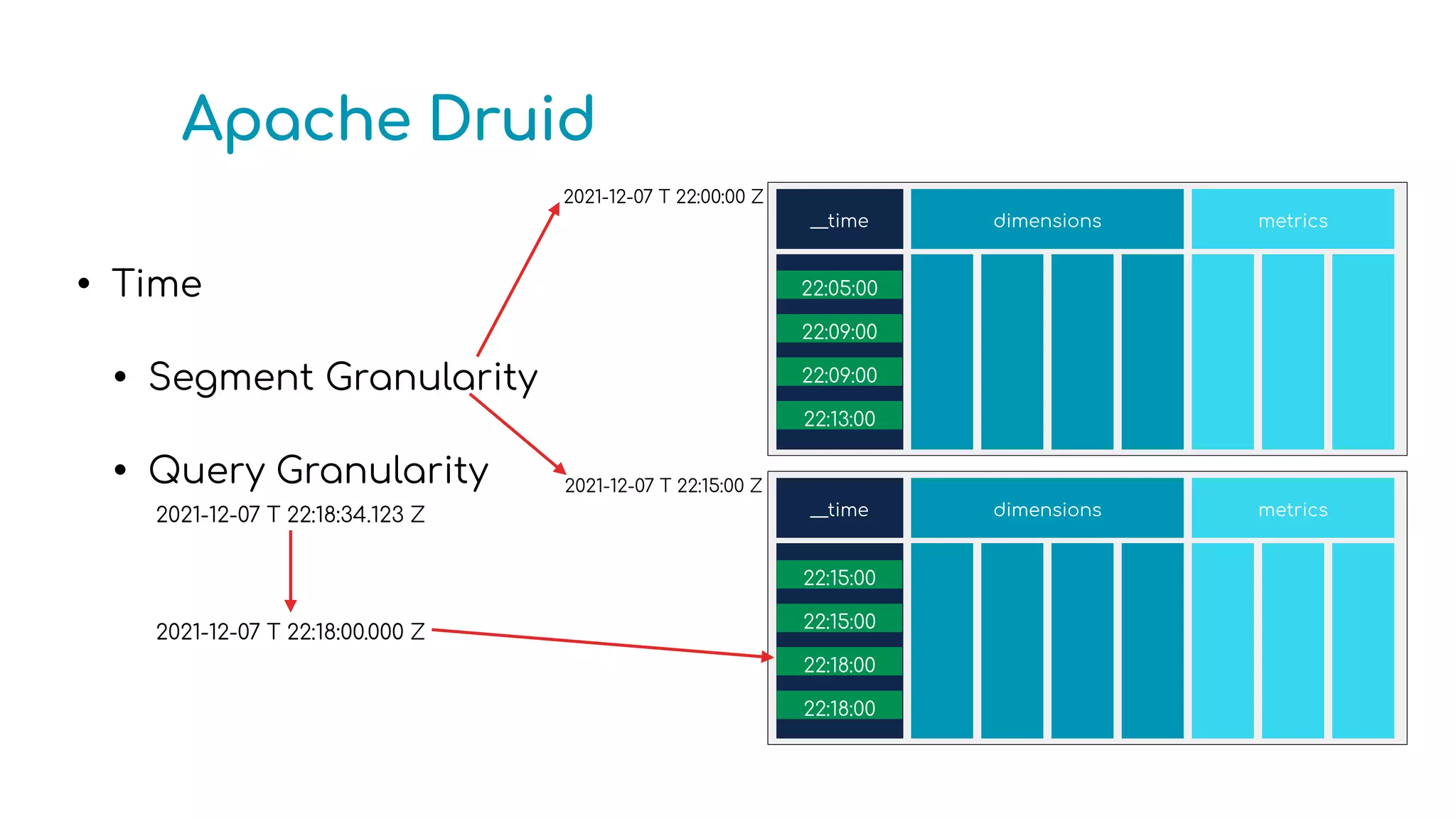
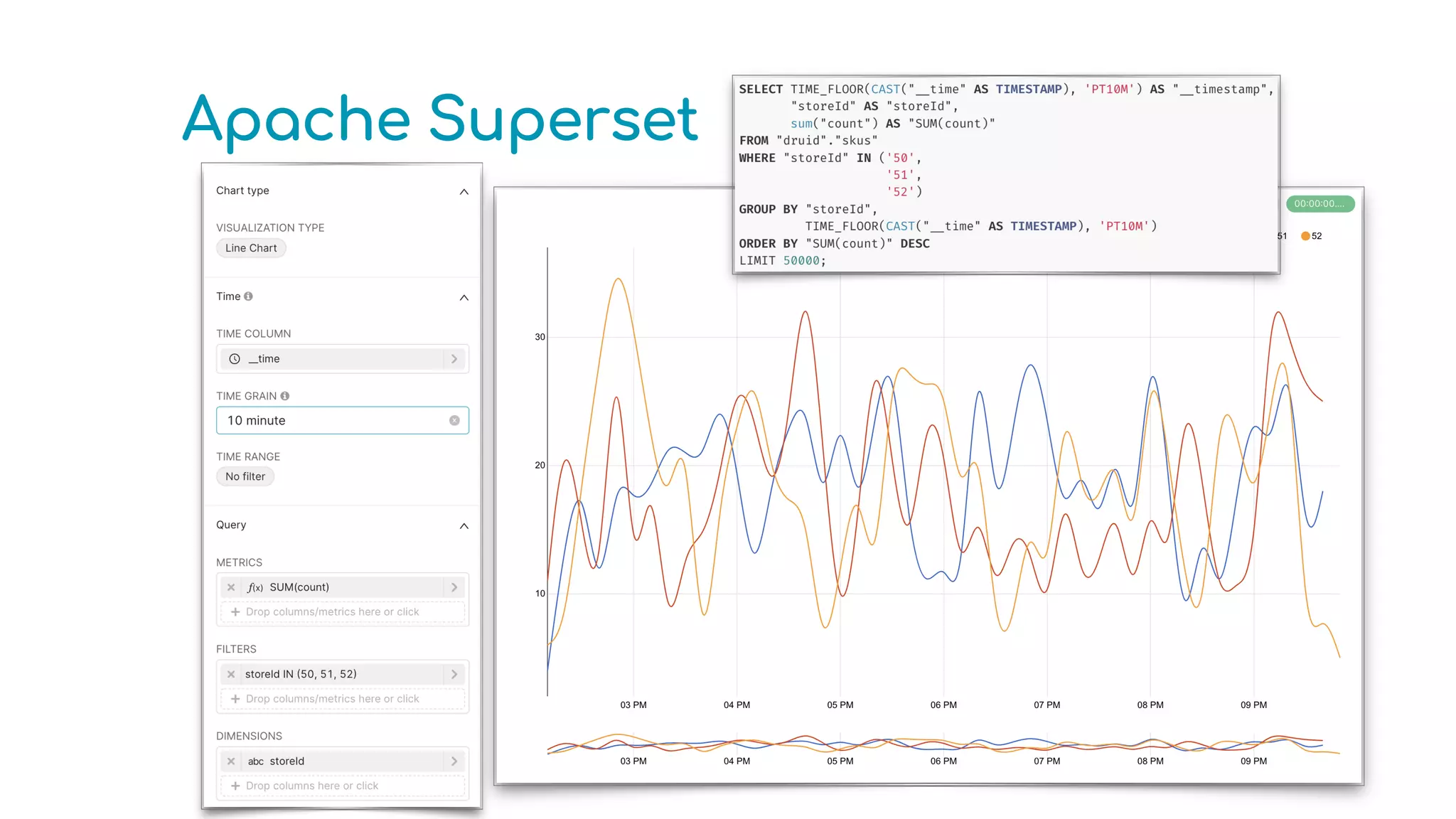
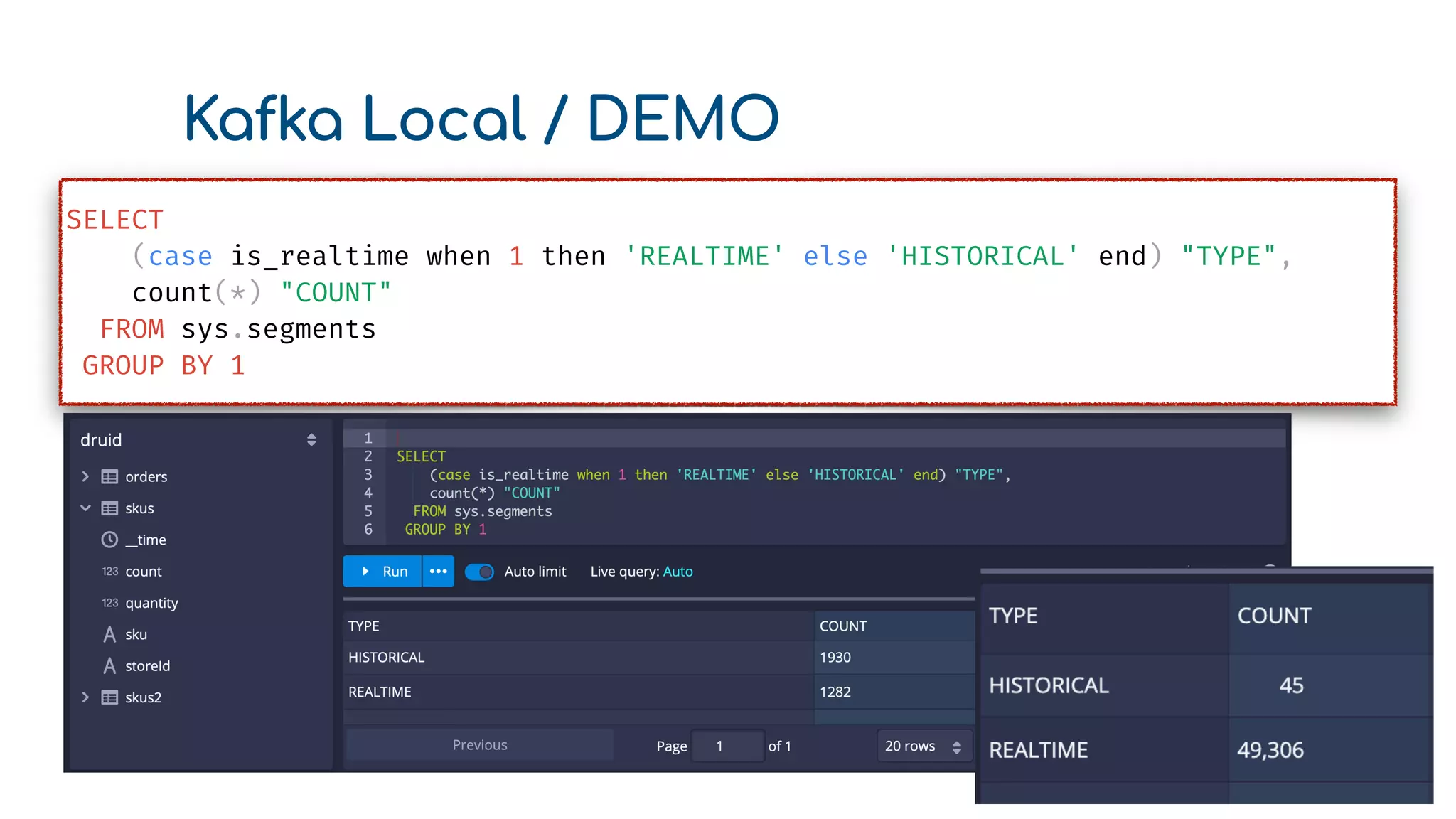
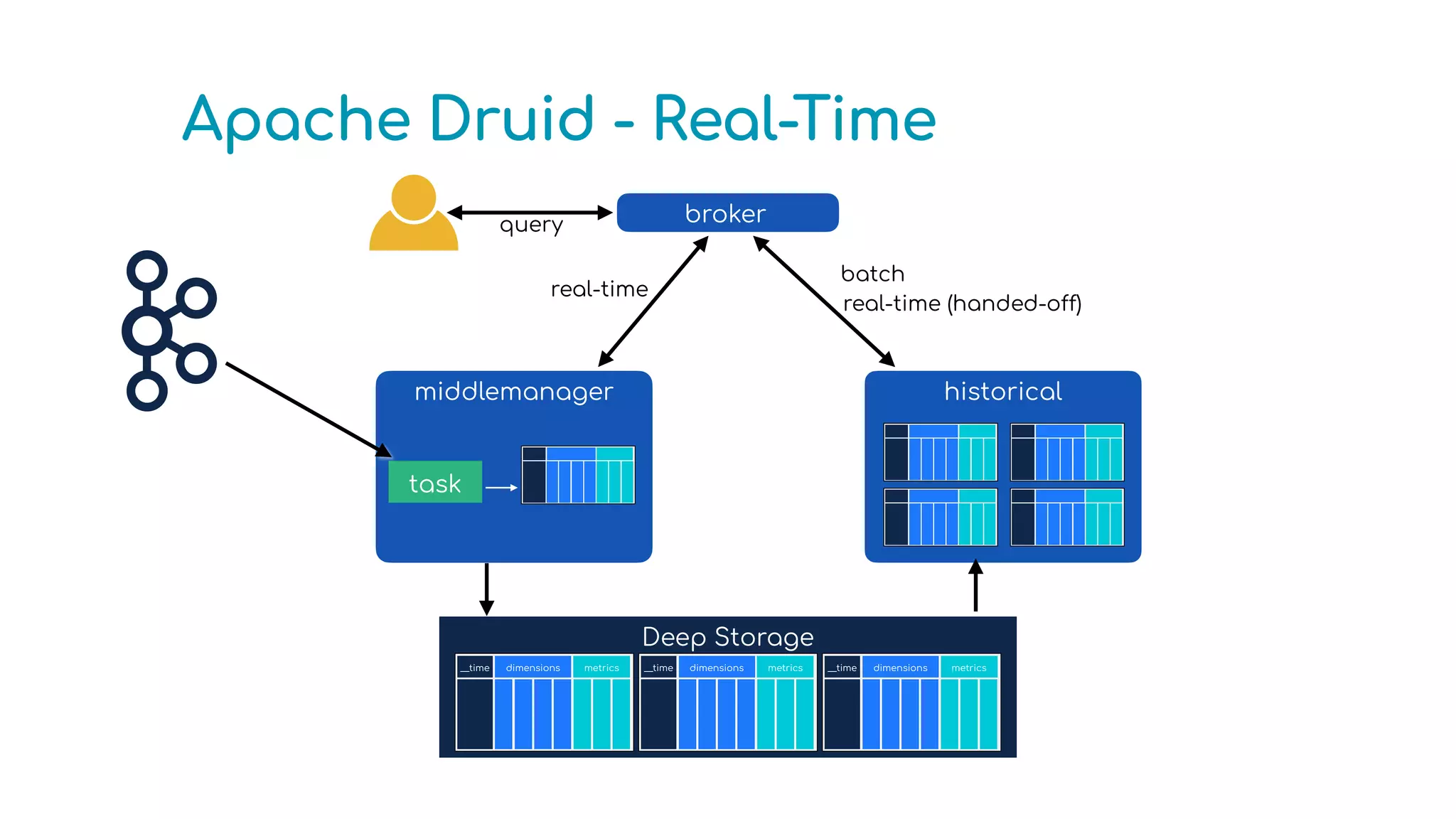
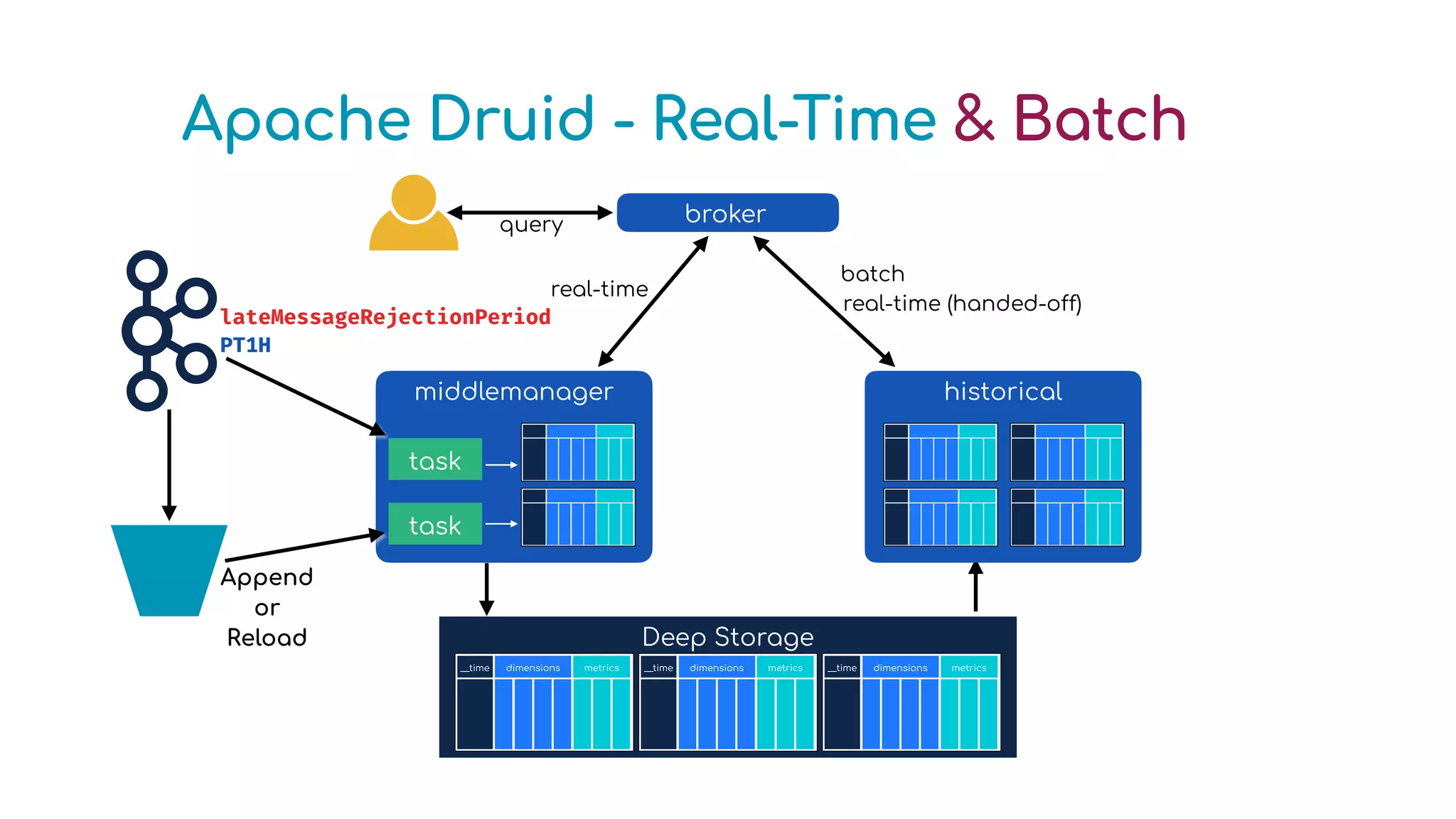
The document provides an overview of optimizing Apache Druid performance using batch and real-time ingestion, along with a technological overview of Apache Druid and Kafka. It covers setup instructions, data querying, and configuration for safe historical data reloading, as well as key considerations for real-time and batch processing. Additionally, the document includes practical examples and links to development resources for local environments.