Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Cloudera Japan
PDF, PPTX
23,185 views
Apache Kuduは何がそんなに「速い」DBなのか? #dbts2017
db tech showcase Tokyo 2017 の発表で使用した資料です。
Data & Analytics
◦
Read more
42
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 110
2
/ 110
3
/ 110
4
/ 110
5
/ 110
6
/ 110
7
/ 110
8
/ 110
9
/ 110
10
/ 110
11
/ 110
12
/ 110
13
/ 110
14
/ 110
15
/ 110
16
/ 110
17
/ 110
18
/ 110
19
/ 110
20
/ 110
21
/ 110
22
/ 110
23
/ 110
24
/ 110
25
/ 110
26
/ 110
27
/ 110
28
/ 110
29
/ 110
30
/ 110
31
/ 110
32
/ 110
33
/ 110
34
/ 110
35
/ 110
36
/ 110
37
/ 110
38
/ 110
39
/ 110
40
/ 110
41
/ 110
42
/ 110
43
/ 110
44
/ 110
45
/ 110
46
/ 110
47
/ 110
48
/ 110
49
/ 110
50
/ 110
51
/ 110
52
/ 110
53
/ 110
54
/ 110
55
/ 110
56
/ 110
57
/ 110
58
/ 110
59
/ 110
60
/ 110
61
/ 110
62
/ 110
63
/ 110
64
/ 110
65
/ 110
66
/ 110
67
/ 110
68
/ 110
69
/ 110
70
/ 110
71
/ 110
72
/ 110
73
/ 110
74
/ 110
75
/ 110
76
/ 110
77
/ 110
78
/ 110
79
/ 110
80
/ 110
81
/ 110
82
/ 110
83
/ 110
84
/ 110
85
/ 110
86
/ 110
87
/ 110
88
/ 110
89
/ 110
90
/ 110
91
/ 110
92
/ 110
93
/ 110
94
/ 110
95
/ 110
96
/ 110
97
/ 110
98
/ 110
99
/ 110
100
/ 110
101
/ 110
102
/ 110
103
/ 110
104
/ 110
105
/ 110
106
/ 110
107
/ 110
108
/ 110
109
/ 110
110
/ 110
More Related Content
PDF
ヤフー社内でやってるMySQLチューニングセミナー大公開
by
Yahoo!デベロッパーネットワーク
PDF
Dockerからcontainerdへの移行
by
Kohei Tokunaga
PDF
Apache Sparkに手を出してヤケドしないための基本 ~「Apache Spark入門より」~ (デブサミ 2016 講演資料)
by
NTT DATA OSS Professional Services
PDF
NTT DATA と PostgreSQL が挑んだ総力戦
by
NTT DATA OSS Professional Services
PDF
詳説データベース輪読会: 分散合意その2
by
Sho Nakazono
PPT
Cassandraのしくみ データの読み書き編
by
Yuki Morishita
PPTX
分散システムについて語らせてくれ
by
Kumazaki Hiroki
PPTX
え、まって。その並列分散処理、Kafkaのしくみでもできるの? Apache Kafkaの機能を利用した大規模ストリームデータの並列分散処理
by
NTT DATA Technology & Innovation
ヤフー社内でやってるMySQLチューニングセミナー大公開
by
Yahoo!デベロッパーネットワーク
Dockerからcontainerdへの移行
by
Kohei Tokunaga
Apache Sparkに手を出してヤケドしないための基本 ~「Apache Spark入門より」~ (デブサミ 2016 講演資料)
by
NTT DATA OSS Professional Services
NTT DATA と PostgreSQL が挑んだ総力戦
by
NTT DATA OSS Professional Services
詳説データベース輪読会: 分散合意その2
by
Sho Nakazono
Cassandraのしくみ データの読み書き編
by
Yuki Morishita
分散システムについて語らせてくれ
by
Kumazaki Hiroki
え、まって。その並列分散処理、Kafkaのしくみでもできるの? Apache Kafkaの機能を利用した大規模ストリームデータの並列分散処理
by
NTT DATA Technology & Innovation
What's hot
PDF
Apache Kuduを使った分析システムの裏側
by
Cloudera Japan
PDF
Hadoop/Spark で Amazon S3 を徹底的に使いこなすワザ (Hadoop / Spark Conference Japan 2019)
by
Noritaka Sekiyama
PDF
YugabyteDBを使ってみよう(NewSQL/分散SQLデータベースよろず勉強会 #1 発表資料)
by
NTT DATA Technology & Innovation
PPTX
ポスト・ラムダアーキテクチャの切り札? Apache Hudi(NTTデータ テクノロジーカンファレンス 2020 発表資料)
by
NTT DATA Technology & Innovation
PDF
B-Treeのアーキテクチャ解説 (第49回PostgreSQLアンカンファレンス@東京 発表資料)
by
NTT DATA Technology & Innovation
PPTX
NTTデータが考えるデータ基盤の次の一手 ~AI活用のために知っておくべき新潮流とは?~(NTTデータ テクノロジーカンファレンス 2020 発表資料)
by
NTT DATA Technology & Innovation
PPTX
Apache Spark on Kubernetes入門(Open Source Conference 2021 Online Hiroshima 発表資料)
by
NTT DATA Technology & Innovation
PPTX
本当は恐ろしい分散システムの話
by
Kumazaki Hiroki
PPTX
Spring Boot ユーザの方のための Quarkus 入門
by
tsukasamannen
PPTX
ビッグデータ処理データベースの全体像と使い分け 2018年version
by
Tetsutaro Watanabe
PDF
SolrとElasticsearchを比べてみよう
by
Shinsuke Sugaya
PPT
インフラエンジニアのためのcassandra入門
by
Akihiro Kuwano
PDF
Kubernetesのしくみ やさしく学ぶ 内部構造とアーキテクチャー
by
Toru Makabe
PDF
Python 3.9からの新定番zoneinfoを使いこなそう
by
Ryuji Tsutsui
PPTX
初心者向けMongoDBのキホン!
by
Tetsutaro Watanabe
PPTX
大規模データ活用向けストレージレイヤソフトのこれまでとこれから(NTTデータ テクノロジーカンファレンス 2019 講演資料、2019/09/05)
by
NTT DATA Technology & Innovation
PPTX
グラフデータベース入門
by
Masaya Dake
PPTX
境界付けられたコンテキスト 概念編 (ドメイン駆動設計用語解説シリーズ)
by
Koichiro Matsuoka
PDF
実運用して分かったRabbit MQの良いところ・気をつけること #jjug
by
Yahoo!デベロッパーネットワーク
PDF
At least onceってぶっちゃけ問題の先送りだったよね #kafkajp
by
Yahoo!デベロッパーネットワーク
Apache Kuduを使った分析システムの裏側
by
Cloudera Japan
Hadoop/Spark で Amazon S3 を徹底的に使いこなすワザ (Hadoop / Spark Conference Japan 2019)
by
Noritaka Sekiyama
YugabyteDBを使ってみよう(NewSQL/分散SQLデータベースよろず勉強会 #1 発表資料)
by
NTT DATA Technology & Innovation
ポスト・ラムダアーキテクチャの切り札? Apache Hudi(NTTデータ テクノロジーカンファレンス 2020 発表資料)
by
NTT DATA Technology & Innovation
B-Treeのアーキテクチャ解説 (第49回PostgreSQLアンカンファレンス@東京 発表資料)
by
NTT DATA Technology & Innovation
NTTデータが考えるデータ基盤の次の一手 ~AI活用のために知っておくべき新潮流とは?~(NTTデータ テクノロジーカンファレンス 2020 発表資料)
by
NTT DATA Technology & Innovation
Apache Spark on Kubernetes入門(Open Source Conference 2021 Online Hiroshima 発表資料)
by
NTT DATA Technology & Innovation
本当は恐ろしい分散システムの話
by
Kumazaki Hiroki
Spring Boot ユーザの方のための Quarkus 入門
by
tsukasamannen
ビッグデータ処理データベースの全体像と使い分け 2018年version
by
Tetsutaro Watanabe
SolrとElasticsearchを比べてみよう
by
Shinsuke Sugaya
インフラエンジニアのためのcassandra入門
by
Akihiro Kuwano
Kubernetesのしくみ やさしく学ぶ 内部構造とアーキテクチャー
by
Toru Makabe
Python 3.9からの新定番zoneinfoを使いこなそう
by
Ryuji Tsutsui
初心者向けMongoDBのキホン!
by
Tetsutaro Watanabe
大規模データ活用向けストレージレイヤソフトのこれまでとこれから(NTTデータ テクノロジーカンファレンス 2019 講演資料、2019/09/05)
by
NTT DATA Technology & Innovation
グラフデータベース入門
by
Masaya Dake
境界付けられたコンテキスト 概念編 (ドメイン駆動設計用語解説シリーズ)
by
Koichiro Matsuoka
実運用して分かったRabbit MQの良いところ・気をつけること #jjug
by
Yahoo!デベロッパーネットワーク
At least onceってぶっちゃけ問題の先送りだったよね #kafkajp
by
Yahoo!デベロッパーネットワーク
Viewers also liked
PDF
ストリーム処理を支えるキューイングシステムの選び方
by
Yoshiyasu SAEKI
PDF
爆速クエリエンジン”Presto”を使いたくなる話
by
Kentaro Yoshida
PDF
Apache Kafka 0.11 の Exactly Once Semantics
by
Yoshiyasu SAEKI
PDF
基礎から学ぶ超並列SQLエンジンImpala #cwt2015
by
Cloudera Japan
PDF
フリーでやろうぜ!セキュリティチェック!
by
zaki4649
PDF
#cwt2016 Apache Kudu 構成とテーブル設計
by
Cloudera Japan
PDF
“確率的最適化”を読む前に知っておくといいかもしれない関数解析のこと
by
Hiroaki Kudo
PDF
Sparkで始めるお手軽グラフデータ分析
by
Nagato Kasaki
PPTX
A/B Testing at Pinterest: Building a Culture of Experimentation
by
WrangleConf
PDF
論文紹介@ Gunosyデータマイニング研究会 #97
by
圭輔 大曽根
PDF
マイクロサービスとABテスト
by
圭輔 大曽根
PDF
WebDB Forum 2016 gunosy
by
Hiroaki Kudo
PDF
Gunosyデータマイニング研究会 #118 これからの強化学習
by
圭輔 大曽根
PDF
あなただけにそっと教える弊社の分析事情 #data analyst meetup tokyo vol.1 LT
by
Hiroaki Kudo
PDF
「新製品 Kudu 及び RecordServiceの概要」 #cwt2015
by
Cloudera Japan
PDF
Apache Kudu - Updatable Analytical Storage #rakutentech
by
Cloudera Japan
PDF
Gunosy における AWS 上での自然言語処理・機械学習の活用事例
by
圭輔 大曽根
PPTX
MongoDBの可能性の話
by
Akihiro Kuwano
PDF
記事分類における教師データおよびモデルの管理
by
圭輔 大曽根
PDF
機械学習で大事なことをミニGunosyをつくって学んだ╭( ・ㅂ・)و ̑̑
by
Seiji Takahashi
ストリーム処理を支えるキューイングシステムの選び方
by
Yoshiyasu SAEKI
爆速クエリエンジン”Presto”を使いたくなる話
by
Kentaro Yoshida
Apache Kafka 0.11 の Exactly Once Semantics
by
Yoshiyasu SAEKI
基礎から学ぶ超並列SQLエンジンImpala #cwt2015
by
Cloudera Japan
フリーでやろうぜ!セキュリティチェック!
by
zaki4649
#cwt2016 Apache Kudu 構成とテーブル設計
by
Cloudera Japan
“確率的最適化”を読む前に知っておくといいかもしれない関数解析のこと
by
Hiroaki Kudo
Sparkで始めるお手軽グラフデータ分析
by
Nagato Kasaki
A/B Testing at Pinterest: Building a Culture of Experimentation
by
WrangleConf
論文紹介@ Gunosyデータマイニング研究会 #97
by
圭輔 大曽根
マイクロサービスとABテスト
by
圭輔 大曽根
WebDB Forum 2016 gunosy
by
Hiroaki Kudo
Gunosyデータマイニング研究会 #118 これからの強化学習
by
圭輔 大曽根
あなただけにそっと教える弊社の分析事情 #data analyst meetup tokyo vol.1 LT
by
Hiroaki Kudo
「新製品 Kudu 及び RecordServiceの概要」 #cwt2015
by
Cloudera Japan
Apache Kudu - Updatable Analytical Storage #rakutentech
by
Cloudera Japan
Gunosy における AWS 上での自然言語処理・機械学習の活用事例
by
圭輔 大曽根
MongoDBの可能性の話
by
Akihiro Kuwano
記事分類における教師データおよびモデルの管理
by
圭輔 大曽根
機械学習で大事なことをミニGunosyをつくって学んだ╭( ・ㅂ・)و ̑̑
by
Seiji Takahashi
Similar to Apache Kuduは何がそんなに「速い」DBなのか? #dbts2017
PPTX
Impala + Kudu を用いたデータウェアハウス構築の勘所 (仮)
by
Cloudera Japan
PDF
40分でわかるHadoop徹底入門 (Cloudera World Tokyo 2014 講演資料)
by
hamaken
PDF
分散処理基盤Apache Hadoop入門とHadoopエコシステムの最新技術動向 (オープンソースカンファレンス 2015 Tokyo/Spring 講...
by
NTT DATA OSS Professional Services
PDF
HBaseを用いたグラフDB「Hornet」の設計と運用
by
Toshihiro Suzuki
PDF
分散処理基盤ApacheHadoop入門とHadoopエコシステムの最新技術動向(OSC2015 Kansai発表資料)
by
NTT DATA OSS Professional Services
PDF
スケーラブルなシステムのためのHBaseスキーマ設計 #hcj13w
by
Cloudera Japan
PDF
Hadoopビッグデータ基盤の歴史を振り返る #cwt2015
by
Cloudera Japan
PDF
【17-E-3】Hadoop:黄色い象使いへの道 ~「Hadoop徹底入門」より~
by
Developers Summit
PDF
Hadoop ecosystem NTTDATA osc15tk
by
NTT DATA OSS Professional Services
PDF
なぜApache HBaseを選ぶのか? #cwt2013
by
Cloudera Japan
PDF
Hadoopエコシステムのデータストア振り返り
by
NTT DATA OSS Professional Services
PPTX
Cloudera大阪セミナー 20130219
by
Cloudera Japan
PPTX
Hadoopトレーニング番外編 〜間違えられやすいHadoopの7つの仕様〜
by
Cloudera Japan
PDF
Osc2012 spring HBase Report
by
Seiichiro Ishida
PDF
Beginner must-see! A future that can be opened by learning Hadoop
by
DataWorks Summit
PPTX
ATN No.1 MapReduceだけでない!? Hadoopとその仲間たち
by
AdvancedTechNight
PDF
分散処理基盤Apache Hadoopの現状と、NTTデータのHadoopに対する取り組み
by
NTT DATA OSS Professional Services
PDF
HBase活用事例 #hbase_ca
by
Cloudera Japan
PDF
Hadoopことはじめ
by
均 津田
PDF
Hadoop上の多種多様な処理でPigの活きる道 (Hadoop Conferecne Japan 2013 Winter)
by
NTT DATA OSS Professional Services
Impala + Kudu を用いたデータウェアハウス構築の勘所 (仮)
by
Cloudera Japan
40分でわかるHadoop徹底入門 (Cloudera World Tokyo 2014 講演資料)
by
hamaken
分散処理基盤Apache Hadoop入門とHadoopエコシステムの最新技術動向 (オープンソースカンファレンス 2015 Tokyo/Spring 講...
by
NTT DATA OSS Professional Services
HBaseを用いたグラフDB「Hornet」の設計と運用
by
Toshihiro Suzuki
分散処理基盤ApacheHadoop入門とHadoopエコシステムの最新技術動向(OSC2015 Kansai発表資料)
by
NTT DATA OSS Professional Services
スケーラブルなシステムのためのHBaseスキーマ設計 #hcj13w
by
Cloudera Japan
Hadoopビッグデータ基盤の歴史を振り返る #cwt2015
by
Cloudera Japan
【17-E-3】Hadoop:黄色い象使いへの道 ~「Hadoop徹底入門」より~
by
Developers Summit
Hadoop ecosystem NTTDATA osc15tk
by
NTT DATA OSS Professional Services
なぜApache HBaseを選ぶのか? #cwt2013
by
Cloudera Japan
Hadoopエコシステムのデータストア振り返り
by
NTT DATA OSS Professional Services
Cloudera大阪セミナー 20130219
by
Cloudera Japan
Hadoopトレーニング番外編 〜間違えられやすいHadoopの7つの仕様〜
by
Cloudera Japan
Osc2012 spring HBase Report
by
Seiichiro Ishida
Beginner must-see! A future that can be opened by learning Hadoop
by
DataWorks Summit
ATN No.1 MapReduceだけでない!? Hadoopとその仲間たち
by
AdvancedTechNight
分散処理基盤Apache Hadoopの現状と、NTTデータのHadoopに対する取り組み
by
NTT DATA OSS Professional Services
HBase活用事例 #hbase_ca
by
Cloudera Japan
Hadoopことはじめ
by
均 津田
Hadoop上の多種多様な処理でPigの活きる道 (Hadoop Conferecne Japan 2013 Winter)
by
NTT DATA OSS Professional Services
More from Cloudera Japan
PDF
Apache Hadoop YARNとマルチテナントにおけるリソース管理
by
Cloudera Japan
PDF
Apache Impalaパフォーマンスチューニング #dbts2018
by
Cloudera Japan
PDF
#cwt2016 Cloudera Managerを用いた Hadoop のトラブルシューティング
by
Cloudera Japan
PDF
Cloudera Data Science WorkbenchとPySparkで 好きなPythonライブラリを 分散で使う #cadeda
by
Cloudera Japan
PDF
Ibis: すごい pandas ⼤規模データ分析もらっくらく #summerDS
by
Cloudera Japan
PDF
Cloudera in the Cloud #CWT2017
by
Cloudera Japan
PPTX
HDFS Supportaiblity Improvements
by
Cloudera Japan
PPTX
Clouderaが提供するエンタープライズ向け運用、データ管理ツールの使い方 #CW2017
by
Cloudera Japan
PDF
大規模データに対するデータサイエンスの進め方 #CWT2016
by
Cloudera Japan
PDF
先行事例から学ぶ IoT / ビッグデータの始め方
by
Cloudera Japan
PDF
Train, predict, serve: How to go into production your machine learning model
by
Cloudera Japan
PDF
Cloud Native Hadoop #cwt2016
by
Cloudera Japan
PDF
HBase Across the World #LINE_DM
by
Cloudera Japan
PDF
Cloudera + MicrosoftでHadoopするのがイイらしい。 #CWT2016
by
Cloudera Japan
PDF
Cloudera のサポートエンジニアリング #supennight
by
Cloudera Japan
PDF
How to go into production your machine learning models? #CWT2017
by
Cloudera Japan
PDF
クラウド上でHadoopを構築できる Cloudera Director 2.0 の紹介 #dogenzakalt
by
Cloudera Japan
PPTX
機械学習の定番プラットフォームSparkの紹介
by
Cloudera Japan
PDF
分散DB Apache Kuduのアーキテクチャ DBの性能と一貫性を両立させる仕組み 「HybridTime」とは
by
Cloudera Japan
PPTX
Hue 4.0 / Hue Meetup Tokyo #huejp
by
Cloudera Japan
Apache Hadoop YARNとマルチテナントにおけるリソース管理
by
Cloudera Japan
Apache Impalaパフォーマンスチューニング #dbts2018
by
Cloudera Japan
#cwt2016 Cloudera Managerを用いた Hadoop のトラブルシューティング
by
Cloudera Japan
Cloudera Data Science WorkbenchとPySparkで 好きなPythonライブラリを 分散で使う #cadeda
by
Cloudera Japan
Ibis: すごい pandas ⼤規模データ分析もらっくらく #summerDS
by
Cloudera Japan
Cloudera in the Cloud #CWT2017
by
Cloudera Japan
HDFS Supportaiblity Improvements
by
Cloudera Japan
Clouderaが提供するエンタープライズ向け運用、データ管理ツールの使い方 #CW2017
by
Cloudera Japan
大規模データに対するデータサイエンスの進め方 #CWT2016
by
Cloudera Japan
先行事例から学ぶ IoT / ビッグデータの始め方
by
Cloudera Japan
Train, predict, serve: How to go into production your machine learning model
by
Cloudera Japan
Cloud Native Hadoop #cwt2016
by
Cloudera Japan
HBase Across the World #LINE_DM
by
Cloudera Japan
Cloudera + MicrosoftでHadoopするのがイイらしい。 #CWT2016
by
Cloudera Japan
Cloudera のサポートエンジニアリング #supennight
by
Cloudera Japan
How to go into production your machine learning models? #CWT2017
by
Cloudera Japan
クラウド上でHadoopを構築できる Cloudera Director 2.0 の紹介 #dogenzakalt
by
Cloudera Japan
機械学習の定番プラットフォームSparkの紹介
by
Cloudera Japan
分散DB Apache Kuduのアーキテクチャ DBの性能と一貫性を両立させる仕組み 「HybridTime」とは
by
Cloudera Japan
Hue 4.0 / Hue Meetup Tokyo #huejp
by
Cloudera Japan
Apache Kuduは何がそんなに「速い」DBなのか? #dbts2017
1.
1© Cloudera, Inc.
All rights reserved. Apache Kuduは何がそんなに 「速い」DBなのか? Takahiko Sato - Sales Engineer at Cloudera Sep 5, 2017
2.
2© Cloudera, Inc.
All rights reserved. はじめに
3.
3© Cloudera, Inc.
All rights reserved. ⾃⼰紹介 • 佐藤貴彦 (さとうたかひこ) / takahiko at cloudera.com • セールスエンジニア • お客様がCloudera製品及び関連技術をを活⽤できるように、⼀緒 に議論するのがメインの仕事 • これまでの経験 • Internet & Network(⼤学) • RDBMS(1社⽬) • NoSQL(2社⽬) • Hadoop(3社⽬) ←Now!
4.
4© Cloudera, Inc.
All rights reserved. 会社概要 - Cloudera(クラウデラ) 設⽴ 2008年、以下4社出⾝の社員により設⽴ 本社 アメリカ パロアルト マーケット 機械学習とアドバンスドアナリティクスのプラットフォーム ビジネスモデル オープンソースとプロプラ製品のハイブリッド 従業員数 世界全体で 1,400⼈以上 事業展開 世界28カ国 世界レベルのサポート 24x7 対応グローバルスタッフ(⽇本語は8x5) EDHを使ったプロアクティブ・予測サポートプログラム ミッションクリティカル 世界中の様々な業界の本番環境 - ⾦融、⼩売、通信、メディア、ヘ ルスケア、エネルギー、政府 最⼤のエコシステム 2,600 社以上のパートナー Cloudera University 45,000⼈ 以上がトレーニングを受講 https://www.cloudera.com/more/about.html
5.
5© Cloudera, Inc.
All rights reserved. Kuduに⾄るまでの背景
6.
6© Cloudera, Inc.
All rights reserved. そもそもHadoopとは何か? • Hadoopとはなにか? • NoSQLとはなにか? • RDBMSとはなにか? • 共通点:データを蓄えて処理をするシステム
7.
7© Cloudera, Inc.
All rights reserved. RDB時代とビッグデータの始まり • リレーショナルデータベース(以下RDB) • シングルデータベースが主流だった時代 • 1台の物理サーバーで完結し、⾮常にシンプルで扱いやすい • 2000年前後からデータは増加が著しくなる • 今で⾔うビッグデータやIoTのさきがけ
8.
8© Cloudera, Inc.
All rights reserved. シングルデータベースの拡張 • シングルDB内で並列処理をする • リソースを増加させる • CPU、RAM、HDDを増加させる • 1台では性能⾯・容量⾯において拡張限界がある • 物理的なコネクタの数の限界 • OSの認識できる最⼤数の限界 • 指数関数的に増加する費⽤⾯の限界
9.
9© Cloudera, Inc.
All rights reserved. 拡張性:スケールアップとスケールアウト 1台を増強して拡張する スケールアップ 複数台を並べて拡張する スケールアウト 2台あれば2倍のデータを扱える...?
10.
10© Cloudera, Inc.
All rights reserved. ビッグデータ時代とRDBと分散処理 • スケールアウトを⽬指す世界へ • 複数のマシンを使った「分散処理」をしたい! • ネットワークを通じて互いに通信をする必要がある • ネットワークをまたいだトランザクションをどうするか? • 分散処理難しい! • シャーディングを併⽤して頑張る、シングルデータベースをたくさん並べ ている・・・
11.
11© Cloudera, Inc.
All rights reserved. RDB時代からHadoop/NoSQL時代 • ビッグデータ時代において、全てをRDBでまかなうのか? • いくつかの部分はRDBじゃなくてもよいのでは? • 例1) RDBでなくても構わない部分 • トランザクションが不要 • 例2) RDBに向いてない部分 • 超⼤量のデータ処理 • 他にも⾊々... • RDBが不得意な部分を、得意とするものを作ろう • HadoopやNoSQLの登場
12.
12© Cloudera, Inc.
All rights reserved. NoSQLとは? • NoSQLとは、RDBでないデータベースの総称 • RDBができてたことを諦めるかわりに、RDBにできなかったことを実現 • SQLインターフェースを捨てた • トランザクションを捨てた • リレーショナルモデルを捨てた • スキーマを捨てた • etc... • 代わりに実現したことの例 • スケールアウト • 低いレイテンシ • 柔軟なスキーマ RDB NoSQL データベース
13.
13© Cloudera, Inc.
All rights reserved. NoSQLというくくり⽅の注意点 • NoSQLという単語が指す範囲は広く、今ではせいぜい「RDBではない データベース」 • 今ではSQLインターフェースを持つNoSQLも多い • 今ではプロダクトが成熟して、今まで諦めてた要素を追加し始めた • RDB以外に様々な特徴を持つデータベースが多数登場しており、同じ軸 で⽐較することが難しくなった • NoSQLというくくり⽅にもはや重要性はない • NoSQLの採⽤を考える際に⼤事なこととして、NoSQLはプロダクトご とに特徴が違うので、何を重要視するかをしっかり考える必要がある
14.
14© Cloudera, Inc.
All rights reserved. Hadoopとは? - Apache Hadoop • Googleが2003年、2004年に発表した2つの公開論⽂を元にして作られ たオープンソースのソフトウェア • 「分散ストレージ」+「分散処理のフレームワーク」を合わせたもの • 既存のテクノロジーでは対応の難しかった「ビッグデータ」への新たな 解決策として登場した Doug Cutting Chief Architect @Cloudera
15.
15© Cloudera, Inc.
All rights reserved. Hadoopとはもともとバッチ処理の基盤 • Hadoopは、RDBでは扱えない規模のデータを処理するための基盤 • どのような処理かというと、「バッチ処理」 • Hadoop:HDFS + MapReduce とは⼤規模バッチ処理のためのもの • HDFSは「分散ストレージ」 • MapReduceは「分散処理のフレームワーク」
16.
16© Cloudera, Inc.
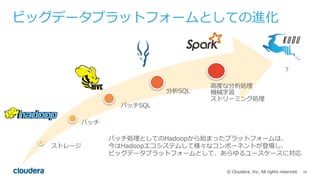
All rights reserved. ビッグデータプラットフォームとしての進化 ストレージ バッチ 分析SQL ? バッチ処理としてのHadoopから始まったプラットフォームは、 今はHadoopエコシステムして様々なコンポーネントが登場し、 ビッグデータプラットフォームとして、あらゆるユースケースに対応 バッチSQL ⾼度な分析処理 機械学習 ストリーミング処理
17.
17© Cloudera, Inc.
All rights reserved. HadoopエコシステムHadoopコア • 現在のHadoop = HDFS + YARN + MapReduce = Hadoopコア = バッチ処理⽤途 • Hadoopとその周辺技術(エコシステム) • 今では周辺の技術の⽅の重要性がますます ⾼まる • バッチ処理だけではなく、リアルタイム処 理、SQLインターフェースの追加など、 拡⼤する「Hadoop」の意味 HDFS YARN MapReduce ImpalaSpark Hive HBase Kudu etc... +
18.
18© Cloudera, Inc.
All rights reserved. 「Hadoopって結局何?よくわからない」という声 • 登場⼈物の多さ、組み合わせの多さのために混乱する • 狭義のHadoop • 「HDFS」+「YARN」+「MapReduce」 • 例)バッチSQL処理、Hiveの利⽤ • 「HDFS」+「YARN」+「MapReduce」 +「Hive」 • 「HDFS」+「YARN」+「Spark」+「Hive」 • 例)分析SQL処理、Impalaの利⽤ • 「HDFS」+「Impala」 • 例)HBaseの利⽤ • 「HDFS」+「HBase」 Hadoopの最近の⽅向性 • HDFSは依然として使われ続けている • MapReduceは使われなくなってきた • 代わりにSparkが⼈気に
19.
19© Cloudera, Inc.
All rights reserved. Hadoopエコシステムにおけるストレージ • Apache Hadoop - HDFS • Apache HBase • Apache Kudu
20.
20© Cloudera, Inc.
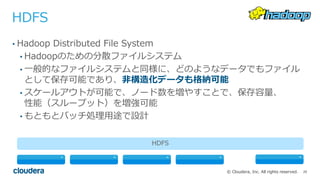
All rights reserved. HDFS • Hadoop Distributed File System • Hadoopのための分散ファイルシステム • ⼀般的なファイルシステムと同様に、どのようなデータでもファイル として保存可能であり、⾮構造化データも格納可能 • スケールアウトが可能で、ノード数を増やすことで、保存容量、 性能(スループット)を増強可能 • もともとバッチ処理⽤途で設計 HDFS
21.
21© Cloudera, Inc.
All rights reserved. HDFSの特徴 • HDFSはバッチ処理のための分散ファイルシステム • ⼤規模データのバッチ処理 • ⼀度にたくさん読み込んで、加⼯して、結果を書き出す → ETL処理 • HDFSの特徴 • ⼤量データをフルスキャンをすることに特化している • IO効率が良くなるよう、⼤きなファイルサイズを想定(数百MB〜GB) • ⾼スループットを重要視している • ⼩さいファイルは結合して⼤きなファイルにしておかないと遅い • ファイルシステムなのでどんな形式でも格納できる • ⾮構造化データ:⽣ログ(txt)、画像などのバイナリ、etc... • 構造化データ:csv, avro, parquet, etc...
22.
22© Cloudera, Inc.
All rights reserved. HDFSの前提 • その名の通り”Hadoop”のための分散ファイルシステム • MapReduceによるバッチ処理を想定して開発されている • サイズの⼤きいファイルに対して⼤量の読み取りを⾏う • アーキテクチャ • スケールアウト • ノードを追加することで、性能・容量を増強 • 巨⼤なファイルを扱う • デフォルトのブロックサイズは⼤きめ(128MB) • ライトワンス • 追記は可能だが既存の内容は変更できない • 故障を前提とした設計 • ⾃動的にデータの複製を持つ • 障害発⽣時の⾃動復旧機能 1 2 3 4 1つのファイルは 128MB単位でブロックに分割 1 2 3 4 1 2 3 4 3つの複製が 保存される
23.
23© Cloudera, Inc.
All rights reserved. HDFSのブロック • HDFSに格納されるファイルは、複数のブロックに分割、複製され保存 • マスターノードには、ファイルを構成するブロックがどのワーカーノード に保存されているかといった情報が保存される • デフォルト128MB(調整可能)のブロックに分割される • 各ブロックはデフォルトで3個(調整可能)の複製 1 2 3 4 2 34 1 2 3 1 2 4 1 34 メタデータ マスターノード ワーカーノード1 ワーカーノード2 ワーカーノード3 ワーカーノード4 128MB単位でブロックに分割 ブロック毎に3レプリカ保存
24.
24© Cloudera, Inc.
All rights reserved. HDFSの様々な機能 • HA構成 • NFSマウントが可能(NFS Gateway) • REST API によるアクセスが可能(HttpFS) • 読み込み時のキャッシュ(Read Caching) • 暗号化(HDFS Encryption) • POSIXスタイルのパーミッションとACL • etc..
25.
25© Cloudera, Inc.
All rights reserved. HDFSとファイル形式 • HDFSはどのようなデータであっても、ファイルと⾔う形で保存可能 • つまり、保存するファイルの構造が重要になる • HDFSでよく使われる代表的なファイル形式 • Text • Avro • Parquet(パーケイ) • Parquetは分析に向いたファイル形式 • 例えば、⼀度HDFS書き込まれた⽣のデータを、⼀定のタイミングで Parquetに変換し、分析処理にまわすといった運⽤が⾏われる Text 形式 Avro 形式 Parquet 形式
26.
26© Cloudera, Inc.
All rights reserved. HBaseとは • Google の BigTable を元に作られた、データベース • ファイルシステムであるHDFSとは異なり、データベースである • 低レイテンシーな、ランダムアクセス(read/write)が可能 • HBaseはHDFSの上に作られており、最終的なデータはHDFS上に格納 されており、HDFSの耐障害性やスケーラビリティの恩恵を受けられる • HDFSでは⼀度書き込んだデータの更新や、ランダムアクセスに不向き だったので、それを克服した • HBaseにより、業務システムのバックエンドDBといった利⽤、いわゆ るNoSQL的な運⽤が可能
27.
27© Cloudera, Inc.
All rights reserved. HDFS HBaseとHDFSの関係 • HBaseは、HDFSを信頼性のある分散ストレージとして利⽤ • レプリカ作成などはHDFSに任せる マスター ワーカー(DN) ワーカー (DN) ワーカー (DN) ワーカー (DN) HBase マスター ワーカー (RS) ワーカー (RS) ワーカー (RS) ワーカー (RS)
28.
28© Cloudera, Inc.
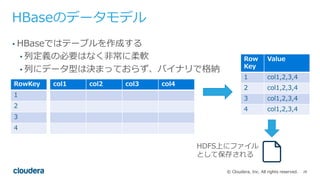
All rights reserved. • HBaseではテーブルを作成する • 列定義の必要はなく⾮常に柔軟 • 列にデータ型は決まっておらず、バイナリで格納 HBaseのデータモデル col1 col2 col3 col4RowKey 1 2 3 4 Row Key Value 1 col1,2,3,4 2 col1,2,3,4 3 col1,2,3,4 4 col1,2,3,4 HDFS上にファイル として保存される
29.
29© Cloudera, Inc.
All rights reserved. カラムファミリー2 • HBaseではカラムファミリーを増やせる カラムファミリー1 HBaseはカラムファミリー col1 col2 col3 col4 col1 col2RowKey 1 2 3 4 カラムファミリーごとにファイルが分かれるため、 IOパーティショニングができる ただし、カラムファミリーは1テーブル2〜3個まで
30.
30© Cloudera, Inc.
All rights reserved. 分析に向いた構造とは? • RDBのようなテーブル構造を考える • 特定の列の全合計値を出すなど、列単位で集計をすることが多い • RDBは⾏単位でデータを格納しているため、特定の列だけが欲しい場合 も、全ての列を読んでしまい、無駄なIOが発⽣する • 「特定の列」だけを読める(無駄なIOが発⽣しない)データ構造 • カラムナー(列指向)
31.
31© Cloudera, Inc.
All rights reserved. HDFSでの分析 • HDFS(フルスキャンが得意)+Parquet(カラムナー構造のファイル) によって、超⼤規模のデータに対して、効率よく分析を⾏うことが可能 • バッチ処理的な分析が可能 • 例えば、⽇々の⽣データを⼀旦ためこんで、⽇時バッチなどで、⼤きな Parquetファイルに変換する • 過去からの⼤量のデータを効率よく分析にまわすことができる • 新しいデータはある程度たまって、データ変換を待つ必要がある • 直近のデータは分析しづらい • リアルタイム性の⽋如
32.
32© Cloudera, Inc.
All rights reserved. HBaseでの分析? • HBaseが最も得意なアクセスは、⾏単位のput/get • そもそもHBaseではしっかりとしたテーブル構造があるわけではない • 各セルについてる、列名は⼀種のラベルにすぎない • 特定の列だけを物理的に読むのには向かない • 流れてくるデータにし対して、HBaseにputし⼀旦HBase上に保存し、 それをHDFS上のParquetファイルなどとして保存 • その後HDFS上でデータ分析をする⼿法などがよくとられる • 結局HDFS上のデータに変換するためのタイムラグを許容する必要あり
33.
33© Cloudera, Inc.
All rights reserved. リアルタイム性と分析のしやすさを両⽴ • HDFS(+HBase)では直近のデータを含めて分析したい場合につらい • RDBでは⼤規模なデータ量への対応がつらい • リアルタイムに更新されるゆく⼤規模なデータに対して、⾼速に分析を できるデータベースが欲しい
34.
34© Cloudera, Inc.
All rights reserved. Kudu概要
35.
35© Cloudera, Inc.
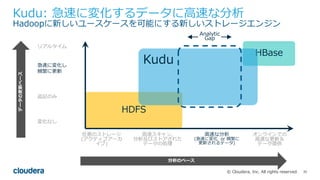
All rights reserved. HDFS ⾼速スキャン, 分析及びストアされた データの処理 オンラインでの ⾼速な更新& データ提供 任意のストレージ (アクティブアーカ イブ) ⾼速な分析 (急速に変化 or 頻繁に 更新されるデータ) Kudu: 急速に変化するデータに⾼速な分析 Hadoopに新しいユースケースを可能にする新しいストレージエンジン 変化なし 急速に変化し 頻繁に更新 HBase 追記のみ リアルタイム Kudu Analytic Gap 分析のペース データの更新ペース
36.
36© Cloudera, Inc.
All rights reserved. 「速い」とは? • 様々なニュアンスで使われる「速い」という単語 • 速いとは「レイテンシーが低い」こと? • 10ms • 1s • 速いとは「スループットが⾼い」こと? • 100万qps • 1000万tps • 速いとは「リアルタイム性が⾼い」こと? • 1時間より前のデータじゃないと分析できない • 1秒前のデータが分析対象にできる
37.
37© Cloudera, Inc.
All rights reserved. スケーラブルで⾼速な表形式のストレージ スケーラビリティ • 275ノード(〜3PBクラスター)までテスト済み • 1000ノード超で数⼗PBまでスケールできるような設計 ⾼速性能 • クラスターで秒間 数百万 のリード/ライト • 1ノードあたり数GB/秒のリードスループット テーブル形式 • リレーショナル・データベースのような構造化されたテーブルでデー タを表現 • 1000億⾏以上からなるテーブルの個々の⾏レベルのアクセスが可能 • “NoSQL” APIs: Java/C++/Python or SQL (Impala/Spark/etc)
38.
38© Cloudera, Inc.
All rights reserved. Kuduのデータモデル • リレーショナルデータベースに似ている • テーブル構造 • 各列は強いデータ型を持つ • 主キーを持つ
39.
39© Cloudera, Inc.
All rights reserved. カラムナー(列指向)ストレージ {25059873, 22309487, 23059861, 23010982} Tweet_id {newsycbot, RideImpala, fastly, llvmorg} User_name {1442865158, 1442828307, 1442865156, 1442865155} Created_at {Visual exp…, Introducing .., Missing July…, LLVM 3.7….} text
40.
40© Cloudera, Inc.
All rights reserved. カラムナーストレージ {25059873, 22309487, 23059861, 23010982} Tweet_id {newsycbot, RideImpala, fastly, llvmorg} User_name {1442865158, 1442828307, 1442865156, 1442865155} Created_at {Visual exp…, Introducing .., Missing July…, LLVM 3.7….} text SELECT COUNT(*) FROM tweets WHERE user_name = ʻnewsycbotʼ; この1列だけを読む 1GB 2GB 1GB 200GB 圧縮とエンコーディングによってIOの増加に対応できるようになった
41.
41© Cloudera, Inc.
All rights reserved. 列のデザイン • 主キー列は必須だが、他の列はNULLも可能 • データ型 • Boolean • 8/16/32/64 bit signed integer • timestamp (64-bit microseconds since the Unix epoch) • float/double (IEEE-754) • UTF-8 encoded string(64KBまで) • Binary (64KBまで) • データ型の重要性 • エンコーディングと圧縮による、IOと保存容量の効率化
42.
42© Cloudera, Inc.
All rights reserved. 列のエンコーディング • エンコーディング(符号化)とは、データのbit表現をどうするか • 列のデータ型がわからないと... • 容量効率やIO効率が悪い • 多くのNoSQLでは、Valueを単なるバイナリとしてしか扱っていない • Kudu ではデータ特性に合わせ効率よくデータを扱える • Plain Encoding • Bitshuffle Encoding • Run Length Encoding(RLE) • Dictionary Encoding • Prefix Encoding
43.
43© Cloudera, Inc.
All rights reserved. Kuduが対応しているエンコーディング⽅式 • Plain Encoding • データ型ごとの標準的な形式で保存(つまり何もしない) • Bitshuffle Encoding • ビット列を並び替え、その後LZ4圧縮を⾏う • 多くの反復値を持つ列、主キーでソートすると少量ずつ変化する値に有効 • Run Length Encoding(RLE) • いわゆるランレングス圧縮を⾏う • 主キーでソートされた際、連続した反復値が多数⾒られる列に効果的 • Dictionary Encoding • 列の値からディクショナリを作成時、実際の列側にはそのインデックスが格納 • カーディナリティの低い列に有効 • ユニークな値が多くなって圧縮が効かなくなってきたら、Plainにフォールバック • Prefix Encoding • 共通プレフィックスを持つ値、主キーの最初の列に有効
44.
44© Cloudera, Inc.
All rights reserved. データ型のエンコーディング • Kudu 1.4 現在は以下のエンコーディング及びデフォルト設定 列のデータ型 可能なエンコーディング デフォルト設定 int8, int16, int32 plan, bitshuffle, run length bitshuffle int64, unixtime_micros plan, bitshuffle, run length bitshuffle float, double plan, bit shuffle bitshuffle bool plan, run length run length string, binary plain, prefix, dictionary dictionary
45.
45© Cloudera, Inc.
All rights reserved. エンコーディング例 • bool - RLEの例 • string - dictionaryの例 true true true false false true true true true bool true x3 false x2 true x4 string sato suzki suzki tanaka tanaka sato sato sato sato 1:sato 2:suzuki 3:tanaka string 1 3 3 2 2 1 1 1 1 dictionary
46.
46© Cloudera, Inc.
All rights reserved. Kuduの列圧縮 • Kuduは列単位でデータの圧縮が可能 • LZ4、Snappy、zlib • 圧縮は圧縮速度と圧縮サイズのバランスを考える • 圧縮処理はCPUと時間を使うが、圧縮によってサイズが減ればIO量を減らすこと ができる • ⼀般的に圧縮/展開速度と圧縮サイズの⾯でLZ4が最もバランスが良く • 圧縮率だけみるならzlibが最も⾼い • 通常の列はデフォルトでは無圧縮 • Bitshuffleエンコーディングは例外で、内部で⾃動的にLZ4で圧縮が⾏われるので、 その上に追加で圧縮を掛ける必要はない
47.
47© Cloudera, Inc.
All rights reserved. 主キーのデザイン • Kuduの表は、現在は主キーが必須 • 主キーは⼀意制約を持つ • null, boolean, float/double は許可されない • 現時点ではシーケンス機能(⾃動でインクリメントするinteger)を持 たないため、アプリケーションは挿⼊時に常に主キーを提供する必要が ある • 主キー列の値は更新不可 • 通常のRDBMSでも同様
48.
48© Cloudera, Inc.
All rights reserved. Kuduは次世代のハードウェアに対応 SSDは毎年安くなり速くなる。 永続性のあるメモリー (3D XPoint™) の登場。 KuduはIntelのNVMeライブラリを 使っており、SSDやNVMeを効果的に 扱える。 RAMは毎年安くなり毎年⼤きくなる。 Kuduは⼤規模なメモリー上でスムーズ に動作する。 GC問題を避けるために、C++で書か れている。 現在のCPUは、コア数の増加と SIMD命令幅の増加であり、GHzの 増加ではなくなっている。 KuduはSIMD命令と同時並⾏性の⾼ いデータ構造を効果的に扱うことが できる。 SSD より安くより⼤きなメモリ 現在のCPUにおける効率性
49.
49© Cloudera, Inc.
All rights reserved. KuduのSQLインターフェース • Kudu はリレーショナルデータベースに似た構造を持つストレージだが、 クエリエンジン(SQL)は他に任せている Query Engine Storage Engine Catalog Query Engine (Impala) Catalog (HMS) モノリシックな 分析データベース モダンな分析データベース Storage (Kudu) Storage (S3) Storage (HDFS)
50.
50© Cloudera, Inc.
All rights reserved. Apache Impala: Hadoop向けのセルフBI SQL on Hadoop • BIスタイルのSQLをHadoop(HDFSなど)に対して実⾏ • HiveのようにSparkやMapReduceの処理に変換せず直接実⾏ ⾼速性能 • アドホッククエリ⽤途 • レイテンシーを意識した設計(数秒〜数⼗秒で応答を返す) 同時並⾏性 • 複数ユーザーが同時にSQLを実⾏しても、⼗分な性能を発揮できる 互換性 • JDBC/ODBCドライバーにより、様々なBIツールと接続可能
51.
51© Cloudera, Inc.
All rights reserved. 様々なSQL on Hadoop バッチ処理⽤途 BI及びSQL分析 Sparkによる 開発⽤途 SQLOR Impala
52.
52© Cloudera, Inc.
All rights reserved. KuduへのSQLアクセス(w/ Impala)
53.
53© Cloudera, Inc.
All rights reserved. KuduへのAPIによるアクセス • 各種プログラミング⾔語のバインディング • C++ • Java • Python • 各種ミドルウェアとの統合 • MapReduce • YARN • Spark • Flume
54.
54© Cloudera, Inc.
All rights reserved. KuduとSparkとの連携 • DataFrameからテーブルの操作 • SparkSQLの使⽤ • Kuduに保存されているデータを Spark上で容易に処理すること が可能
55.
55© Cloudera, Inc.
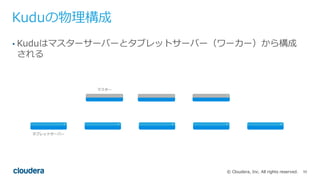
All rights reserved. Kuduの物理構成 • Kuduはマスターサーバーとタブレットサーバー(ワーカー)から構成 される タブレットサーバー マスター
56.
56© Cloudera, Inc.
All rights reserved. タブレット • Kuduでテーブルを作成した際、1つのテーブルに格納されるデータは、 タブレットに分割されて、各タブレットサーバー上に保存される タブレット タブレットサーバー Kudu上のテーブル
57.
57© Cloudera, Inc.
All rights reserved. タブレットの複製 • ある1つのタブレットは、さらに複数のタブレット(デフォルト3)に複 製され、これもまた異なるタブレットサーバーに保持される • タブレットでは、Raftコンセンサスアルゴリズムを使ってリーダーが選 出される • タブレットへのデータの書き込み処理はリーダーでのみ受け付けられる • タブレットからのデータの読み込みは、どのレプリカからでも可能 タブレットサーバー タブレット リーダー タブレット フォロワー タブレット フォロワー
58.
58© Cloudera, Inc.
All rights reserved. 分散処理とレプリカの難しさ • 分散処理では様々な理由から1つのデータをレプリカする • 理由)故障率の上昇に伴うデータロストを防ぐ • 理由)データのローカリティ • レプリカの整合性は難しい! • データのコピーは⼀瞬では終わらない、 • ネットワークが不通になったら?ディスク書き込みが失敗したら?マ シンが故障したら?レプリカ整合性がくずれる理由はいくらでもある A A A
59.
59© Cloudera, Inc.
All rights reserved. 復習:昔からよく出てくるCAP定理 • このうち2つしか満たせない・・・と⾔われている • Consistency(レプリカ間の整合性) • Availability(システム全体の可⽤性) • Partition Tolerance(ネットワーク分断が許容できるかどうか) • よくある例 • CP型 - 整合性優先 - 強い整合性 • AP型 - 可⽤性優先 - 弱い整合性 • 最近では技術や各種プロダクトの実装が進み、もともとAP型だったデータ ベースでも、強い整合性を持ち始めてきた(設定で変更可能だったりする)
60.
60© Cloudera, Inc.
All rights reserved. 復習:⽂脈で異なるConsistency • 2つの⽂脈 • RDB等のトランザクション間におけるConsistency • つまり ”ACID” の ”C” • 分散DB等におけるレプリカ間のConsistency • つまり “CAP” の “C” • この2つの ”C” は意味、レイヤーが違うので注意
61.
61© Cloudera, Inc.
All rights reserved. Kuduにおけるタブレットとパーティション • Kuduはパーティションを持ち、データを分割することができる • レンジパーティション • ハッシュパーティション • マルチレベルパーティション • レンジとハッシュの組合せ • 複数のハッシュの組合せ • Kuduのパーティションは、タブレットと対応する タブレット
62.
62© Cloudera, Inc.
All rights reserved. レンジパーティション • レンジパーティションでは、完全に順序付けされたレンジパーティショ ンキーを使って、⾏を分散させる • このパーティションキーは、主キーのサブセットである必要がある • ハッシュパーティションを併⽤しない場合、各レンジパーティションは、 完全に1つのタブレットと対応する • つまりレンジの個数だけ、タブレットが存在する
63.
63© Cloudera, Inc.
All rights reserved. ハッシュパーティション • ハッシュ値によって、値を複数のバケットの1つに対応させる • ハッシュパーティション単⼀であれば、各バケットはそれぞれ1つのタブ レットに⼀致する • バケットの数は、テーブル作成時に設定 • 通常は主キーをハッシュ⽤の列として使うが、主キー列のサブセットを使う こともできる • テーブルに順序アクセスをする必要がない場合は効果的 • 特に書き込みにおいて、ホットスポットや、タブレットサイズの不均衡を緩 和することに役⽴つ
64.
64© Cloudera, Inc.
All rights reserved. マルチレベルパーティション • マルチレベルパーティションでは、0個以上のハッシュパーティション と、レンジパーティションを組み合わせることが可能 • 制約として、複数レベルのハッシュパーティションが、同じ列をハッ シュしてはならない • マルチレベルパーティションでは、合計タブレット数は、各レベルの パーティション数の積になる
65.
65© Cloudera, Inc.
All rights reserved. パーティションのプルーニング • Kuduは、スキャンの述語(いわゆる WHRER句)によって該当パー ティションを読む必要が無いと判断した時、⾃動的にそのパーティショ ンの読み取りをプルーニング(スキップ)する • ハッシュパーティションのプルーニング • 全てのハッシュ列に等価(=)の述語を含める必要がある • レンジパーティションのプルーニング • レンジパーティション列に、等価(=)または範囲(<,>,≦,≧,etc) を含む必要がある
66.
66© Cloudera, Inc.
All rights reserved. パーティション戦略 • ハッシュパーティションは書き込みスループットの最⼤化によい • レンジパーティションはタブレットの肥⼤化を防ぐことができる • 両者を組合せたマルチレベルパーティションでは、正しく設計できれば、 両者のメリットを享受することができる 戦略 書き込み 読み込み タブレットの肥⼤化 range(time) ❌全ての書き込みは最新の パーティションに⾏く ✅時間を指定して読み 込む場合、時間の境界 を超えた不要な読み取 りは発⽣しない ✅将来のレンジ⽤に、 新たなタブレットが追 加される hash(host, metric) ✅書き込みはタブレット全 体に均等に⾏く ✅特定のhostやmetric をスキャンする際、不 要な読み込みは発⽣し ない ❌各タブレットは肥⼤ 化する
67.
67© Cloudera, Inc.
All rights reserved. パーティション vs インデックス • パーティション • データポイントどのように複数パーティションに分散させるか • Kudu: tablet • HBase:region • Cassandra:vnode • インデックス • 1パーティション内のデータをどのようにソートするか • 時系列データでは、⼀般に (series, time) でインデックス化する → なぜ? (us-east.appserver01.loadavg, 2016-05-09T15:14:00Z) (us-east.appserver01.loadavg, 2016-05-09T15:15:00Z) (us-west.dbserver03.rss, 2016-05-09T15:14:30Z) (us-west.dbserver03.rss, 2016-05-09T15:14:30Z) (2016-05-09T15:14:00Z, us-east.appserver01.loadavg) (2016-05-09T15:14:30Z, us-west.dbserver03.rss) (2016-05-09T15:15:00Z, us-east.appserver01.loadavg) (2016-05-09T15:14:30Z, us-west.dbserver03.rss) (series, time) (time, series)
68.
68© Cloudera, Inc.
All rights reserved. 主キーのインデックスによるプルーニング • Kuduの主キーは、クラスターインデックスになっている • 1つのタブレット内にある全ての⾏は、主キーのソート順に保持される • スキャンの述語に、等価(=)、範囲(<,>,≦,≧,etc)などがある場 合、合致しないものはIOをスキップする • 主キーによるプルーニングは、主キーのプレフィックスにのみ有効 • 複合主キーPK(A,B,C)があり、where C=ʻ...ʼ という条件をかけた場合、 プレフィックスではないのでプルーニングは起こらないので注意
69.
69© Cloudera, Inc.
All rights reserved. 主キーによるselectとプルーニング • 例)時系列(time-series)データの場合 • “time” - timestamp • ”series” - {region, server, metric} • where句としてseriesに相当するものを付ける場合 • PK(series, time)はプルーニングされるが • PK(time, series)はプルーニングがされない (us-east.appserver01.loadavg, 2016-05-09T15:14:00Z) (us-east.appserver01.loadavg, 2016-05-09T15:15:00Z) (us-west.dbserver03.rss, 2016-05-09T15:14:30Z) (us-west.dbserver03.rss, 2016-05-09T15:14:30Z) (2016-05-09T15:14:00Z, us-east.appserver01.loadavg) (2016-05-09T15:14:30Z, us-west.dbserver03.rss) (2016-05-09T15:15:00Z, us-east.appserver01.loadavg) (2016-05-09T15:14:30Z, us-west.dbserver03.rss) (series, time) (time, series) SELECT * WHERE series = ‘us-east.appserver01.loadavg’;
70.
70© Cloudera, Inc.
All rights reserved. レンジパーティションのメンテナンス • 実⾏時に、レンジパーティションを動的に追加及び削除可能 • この操作は他のパーティションの可⽤性に影響を与えない • パーティションの削除は、内部データも削除される • ⼀旦削除されたパーティションへの挿⼊は失敗となる • 追加に関しては、既存パーティションとレンジが重複してはいけない • alter table で操作可能
71.
71© Cloudera, Inc.
All rights reserved. Kuduと書き込みの⼀貫性 • 今度はACIDの⽅のConsistency(⼀貫性)のお話 • Kuduのトランザクション設計は、2012年に出された、Spannerや Calvinの論⽂を参考にして開発された • 将来的には複数⾏や複数タブレットにまたがったACIDトランザクショ ン対応に向けて進めている、現時点では⾏単位のACIDのみ対応 • まだコーナーケースに対応しきれてない • 実験的に幾つかの機能は提供している
72.
72© Cloudera, Inc.
All rights reserved. Kuduと読み取りの⼀貫性 • Kuduは内部でMVCC(Multi-version Concurrency Control)を使って おり、読み込み時には、すでにコミットが完了したデータだけをみるこ とができる • これは、リードつまり分析⽬的等でスキャンをする際、スキャン開始時 点のデータのスナップショット(断⾯)に対して読み取りを⾏う • WALとは別に、内部的にREDOとUNDOを⽤いている • よって、それ以降に裏側でデータの挿⼊や更新が⼊っても、読み取り時 は⼀貫性を保ったまま分析処理を⾏うことができる
73.
73© Cloudera, Inc.
All rights reserved. 読み取り時のモード • ⼤きく2種類 • READ_LATEST(デフォルト) • タブレット内の最新のバージョンを読む • 単純に各タブレット上での最新の情報を⾒るだけなので、特定の静⽌ 断⾯を⾒ているわけではない • READ_AT_SNAPSHOT • 特定のタイムスタンプのバージョンを含んだ、MVCCのスナップ ショットを取得し、それをスキャンする • 全ての書き込みにはタイムスタンプがタグ付けされているため、ある 時間断⾯のデータにアクセスができる(Repeatable Read)
74.
74© Cloudera, Inc.
All rights reserved. 書き込みと読み込みの流れ
75.
75© Cloudera, Inc.
All rights reserved. Blog:Kuduにおけるリードとライトの流れ • Cloudera Engineering Blog - Apache Kudu Read & Write Paths • https://blog.cloudera.com/blog/2017/04/apache-kudu-read-write-paths/ • ⽇本語訳 • https://blog.cloudera.co.jp/11c3a749a81b
76.
76© Cloudera, Inc.
All rights reserved. 76 耐障害性(⼀時停⽌) • フォロワーの⼀時的な停⽌: • リーダーは依然過半数の取得が可能なのでサービスを継続 • 5分以内に起動すれば透過的に再度フォロワーとして加⼊ • リーダーの⼀時的な停⽌: • フォロワーは1.5秒毎のリーダーからのハートビートを待機 • 3 回ハートビートがなかった場合: リーダーの再選出 • 新しいリーダーは数秒の内に選出される • 停⽌したリーダーが5分以内に起動した場合はフォロワーとして加⼊ • N個のレプリカは (N-1)/2 までのタブレットサーバ停⽌に対応可
77.
77© Cloudera, Inc.
All rights reserved. 77 耐障害性(永続停⽌) • 永続的な停⽌ • リーダーが5分を閾値に検知 • 該当のフォロワーを排除 • マスターが新しいタブレットサーバーを選択 • リーダーが新しいタブレットサーバーにデータをコピー • そのサーバーがフォロワーとして参加
78.
78© Cloudera, Inc.
All rights reserved. Kuduのステータス画⾯ • マスターは http://<マスターのIP>:8051 • タブレットサーバーは http://<タブレットサーバーのIP>:8050
79.
79© Cloudera, Inc.
All rights reserved. Kuduのステータス画⾯ • タブレットごとの各種情報など
80.
80© Cloudera, Inc.
All rights reserved. Kuduのトレーシング機能 • サーバー内部のトレーシング機能 • トレースの記録を開始してから停⽌するまでの詳細なトレースを取得
81.
81© Cloudera, Inc.
All rights reserved. Kuduの⽤途
82.
82© Cloudera, Inc.
All rights reserved. Kuduの⽤途 • OLAP的なスキャンが得意 • その裏で更新処理(Insert/Update)も可能 • 裏で更新処理を受け続けながら、分析スキャンをかけることができる • 任意の時間のスナップショットに対してスキャンを⾏うことができる
83.
83© Cloudera, Inc.
All rights reserved. IoTに代表される時系列データの処理 時系列データ Workloadワークロード インサート、アップデート、スキャン、ルックアップ 例 ストリームマーケットデータ、IoT、不正検知と防⽌、 リスクモニタリング、コネクティッドカー Kuduはこれらを同時に満たすことができる • 到着した時系列データを insert/update する • 新鮮な時系列データから傾向分析をするためのス キャンをする • イベントが発⽣したポイントを速やかに⾒つけ出す
84.
84© Cloudera, Inc.
All rights reserved. BI等のオンラインレポートを多⽬的で オンラインレポートの限界を無くす • 常に利⽤可能で、際限なくデータを保存可能で、 アーカイブ化の必要がない • 1つのデータストアから⾼速な検索と⾼速な分析 スキャン 例 業務システムのデータベース Workloadワークロード インサート、アップデート、スキャン、ルックアップ オンライン レポート
85.
85© Cloudera, Inc.
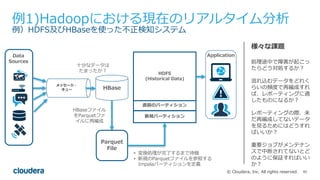
All rights reserved. 例1)Hadoopにおける現在のリアルタイム分析 例)HDFS及びHBaseを使った不正検知システム 様々な課題 処理途中で障害が起こっ たらどう対処するか? 流れ込むデータをどれく らいの頻度で再編成すれ ば、レポーティングに適 したものになるか? レポーティングの際、未 だ再編成してないデータ を⾒るためにはどうすれ ばいいか? 重要ジョブがメンテナン スで中断されてないとど のように保証すればいい か? ⼗分なデータは たまったか? HBaseファイル をParquetファ イルに再編成 • 変換処理が完了するまで待機 • 新規のParquetファイルを参照する Impalaパーティションを定義 メッセージ・ キュー Parquet File HBase ApplicationData Sources HDFS (Historical Data) 直前のパーティション 新規パーティション
86.
86© Cloudera, Inc.
All rights reserved. 例1)Hadoopにおける現在のリアルタイム分析 例)Kuduを使った不正検知システムの単純化 Kudu Application メッセージ・ キュー Data Sources • これまでRDBでやってきたようなシステムを、⼤規模データストリームデー タでもであっても処理可能に • ラムダアーキテクチャといった複雑なシステムを考えなくて良い • HDFSを利⽤する場合に必要だったデータ変換処理等の待ち時間が不要
87.
87© Cloudera, Inc.
All rights reserved. リアルタイムなデータと機械学習 マシンデータ 分析 Workloadワークロード インサート、スキャン、ルックアップ トレンド分析が可能なリアルタイムデータによっ て、潜在的問題を特定 Kuduは様々なものを通じてトラブルを特定: • 無制限のストレージによって、過去から今に⾄るま でのより良いトレンド分析をもたらす • データの⾼速なインサートによって、最新のネット ワークビューを可能とする • ⾼速スキャンを⾏い、良くない状態を特定/フラグ⽴ てする 例 ネットワーク脅威の検出、ネットワークヘルスモニタリ ング、アプリケーションパフォーマンスモニタリング
88.
88© Cloudera, Inc.
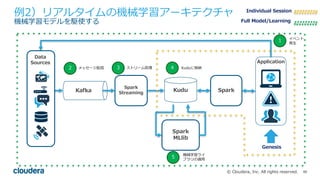
All rights reserved. 例2)リアルタイムの機械学習アーキテクチャ 機械学習モデルを駆使する Kafka Spark Streaming Kudu Spark MLlib Application Data Sources Individual Session Full Model/Learning Genesis Spark 1 イベント 発⽣ 2 メッセージ配信 3 ストリーム処理 4 Kuduに格納 5 機械学習ライ ブラリの適⽤
89.
89© Cloudera, Inc.
All rights reserved. 例2)リアルタイムの機械学習アーキテクチャ MLlib & K-Means: 機械学習で分割単位を特定 Height Weight Height Weight 1 2 Height Weight 3 Height Weight 4 L M S XL L M S XS Near Custom ? 機械学習ライ ブラリの適⽤
90.
90© Cloudera, Inc.
All rights reserved. サイバーセキュリティに適⽤する例 ネットワークへのAPT攻撃を発⾒ Kafka Spark Streaming Kudu Spark MLlib Application Data Sources Individual Session 悪意のあるユーザー Spark Full Model/Learning ストリーム処理に送られるデータリクエスト データはクレンジング/並び替え/処理 等が⾏われ、モデル化のためにKuduに 送られる アクセスは検証され、初期データが配 信され、後続の要求が集約され、標準 的なユーザー/ロールの動作と⽐較さ れる
91.
91© Cloudera, Inc.
All rights reserved. CDHとKudu
92.
92© Cloudera, Inc.
All rights reserved. CDH: ClouderaのHadoopディストリビューション • Cloudera's Distribution including Apache Hadoop • Hadoopディストリビューション • Hadoopエコシステムを⼀般利⽤者が利⽤できる形にまとめあげたもの • Cloudera が提供する CDH • 他で例えると・・・ • Linuxディストリビューション • Red Hat が提供する Red Hat Enterprise Linux
93.
93© Cloudera, Inc.
All rights reserved. CDH 5.10 より Kudu をサポート! • 2016-09-19 Apache Kudu 1.0.0 リリース • 2016-10-11 Apache Kudu 1.0.1 リリース • 2016-11-21 Apache Kudu 1.1.0 リリース • 2017-01-18 Apache Kudu 1.2.0 リリース • 2017-01-31 CDH 5.10 で Apache Kudu 1.2 が GA に • 2017-03-20 Apache Kudu 1.3.0 リリース • 2017-04-19 Apache Kudu 1.3.1 リリース • 2017-06-13 Apache Kudu 1.4.0 リリース
94.
94© Cloudera, Inc.
All rights reserved. エンタープライズとKudu • Apache Kudu 1.3.0 が節⽬ • Kerberos認証に対応 • 通信路の暗号化に対応
95.
95© Cloudera, Inc.
All rights reserved. Kudu は別 Parcel での提供 • Cloudera の製品は Parcel と呼ばれるパッケージ形式で提供 • CDH 5 の Parcel(これにほどが⼊っているが...) • Kafka の Parcel • Spark 2.0 の Parcel • Kudu の Parcel
96.
96© Cloudera, Inc.
All rights reserved. Cloudera ManagerからKuduのインストール • Cloudera Manager 5.11以降では、KuduのParcelを追加するだけで簡単 に導⼊可能(5.10以前でもKudu⽤のCSDを配置することで対応可能)
97.
97© Cloudera, Inc.
All rights reserved. Kuduサービスの追加
98.
98© Cloudera, Inc.
All rights reserved. Kuduサービスのホーム画⾯
99.
99© Cloudera, Inc.
All rights reserved. Impala連携の設定
100.
100© Cloudera, Inc.
All rights reserved. Hue(Impala経由)からのデータの投⼊
101.
101© Cloudera, Inc.
All rights reserved. Kuduの技術情報 • Apache Kudu Documentation(Clouderaのドキュメント) • https://www.cloudera.com/documentation/kudu/latest.html • Apache Kudu(コミュニティサイト) • https://kudu.apache.org/ • Cloudera Engineering Blog - Apache Kudu Read & Write Paths • https://blog.cloudera.com/blog/2017/04/apache-kudu-read- write-paths/
102.
102© Cloudera, Inc.
All rights reserved. 構築⽅法(おまけ編)
103.
103© Cloudera, Inc.
All rights reserved. Kudu環境の構築 • Cloudera Managerなんて使ってない⼈はどうやって⼊れるの? • Kudu単体で使う • Quickstart VMを使う⽅法 • 機能検証でよければこれが楽 • 普通にインストールする⽅法 • 各種設定や連携は⾃分でする必要あり • いやいやKuduのクラスターを組まなければ意味がない! • Kuduのクラスターを簡単に構築したい! • Cloudera Director による簡単構築
104.
104© Cloudera, Inc.
All rights reserved. • Hadoopクラスターをクラウド上でデプロイ&管理するためのツール • ベストプラクティスを再利⽤可能な構成ファイルで提供 • クラスターのライフサイクル(grow & shrink)を管理 • Cloudera Manager との管理の同期 Cloudera Directorによる環境の⾃動構築 クラウド (AWS/Azure/GCP)Cloudera Director Client インスタンス インスタンス インスタンス Cloudera Director Server インスタンス インスタンス インスタンス 起動
105.
105© Cloudera, Inc.
All rights reserved. Blog: Cloudera Directorを⼊れてクラウドにCDHク ラスタを作ろう • 主にデモ環境や開発環境を作る視点で、Cloudera Directorをシンプル に使って、クラスターを構築する例 • https://blog.cloudera.co.jp/getting-started-cloudera-director- 35405d421084
106.
106© Cloudera, Inc.
All rights reserved. Demo
107.
107© Cloudera, Inc.
All rights reserved. 今回のCloudera Director構成ファイル • 今回のデモ環境を作ったCloudera Directorの構成ファイル • https://github.com/takabow/impala-demo-env
108.
108© Cloudera, Inc.
All rights reserved. まとめ
109.
109© Cloudera, Inc.
All rights reserved. Kuduまとめ • RDBに近い使い勝⼿ • 裏で更新(insert/update)を受け続けながら、同時に⼤量の分析クエリ(BIツールから のselectなど)を処理可能 • 列指向の構造化データを扱っており、あらかじめテーブルを作成する • データ型に合わせてエンコーディングや圧縮を⾏っており、データ保存容量とIO量を⼤ きく削減する • 分析時は必要な列しか読まないため、サーバーの負荷やIO量を⼤きく削減 • スケールアウトが容易に可能で、PB級のデータを扱えるような設計がされており、1テー ブル1000億⾏以上のデータでも容易にスキャン可能 • 最新のハードウェア(CPUやメモリ)に併せた実装を⾏っており、⾮常にリソース効率が よい • Impalaと組み合わせることで、分析SQLによるOLAP処理を可能にする • Kuduを使うことで、分析システムを⼤幅にシンプルにできコストダウンが可能
110.
110© Cloudera, Inc.
All rights reserved. Thank you! takahiko at cloudera.com
Download