Downloaded 74 times






















![©2014 Cloudera, Inc. All rights reserved.
Spark Example
1. val conf = new SparkConf().setMaster("local[2]”)
2. val sc = new SparkContext(conf)
3. val lines = sc.textFile(path, 2)
4. val words = lines.flatMap(_.split(" "))
5. val pairs = words.map(word => (word, 1))
6. val wordCounts = pairs.reduceByKey(_ + _)
7. wordCounts.print()](https://image.slidesharecdn.com/frauddetection-forisraelwebinar-160225183246/75/Fraud-Detection-for-Israel-BigThings-Meetup-29-2048.jpg)
![©2014 Cloudera, Inc. All rights reserved.
Spark Streaming Example
1. val conf = new SparkConf().setMaster("local[2]”)
2. val ssc = new StreamingContext(conf, Seconds(1))
3. val lines = ssc.socketTextStream("localhost", 9999)
4. val words = lines.flatMap(_.split(" "))
5. val pairs = words.map(word => (word, 1))
6. val wordCounts = pairs.reduceByKey(_ + _)
7. wordCounts.print()
8. SSC.start()](https://image.slidesharecdn.com/frauddetection-forisraelwebinar-160225183246/75/Fraud-Detection-for-Israel-BigThings-Meetup-30-2048.jpg)

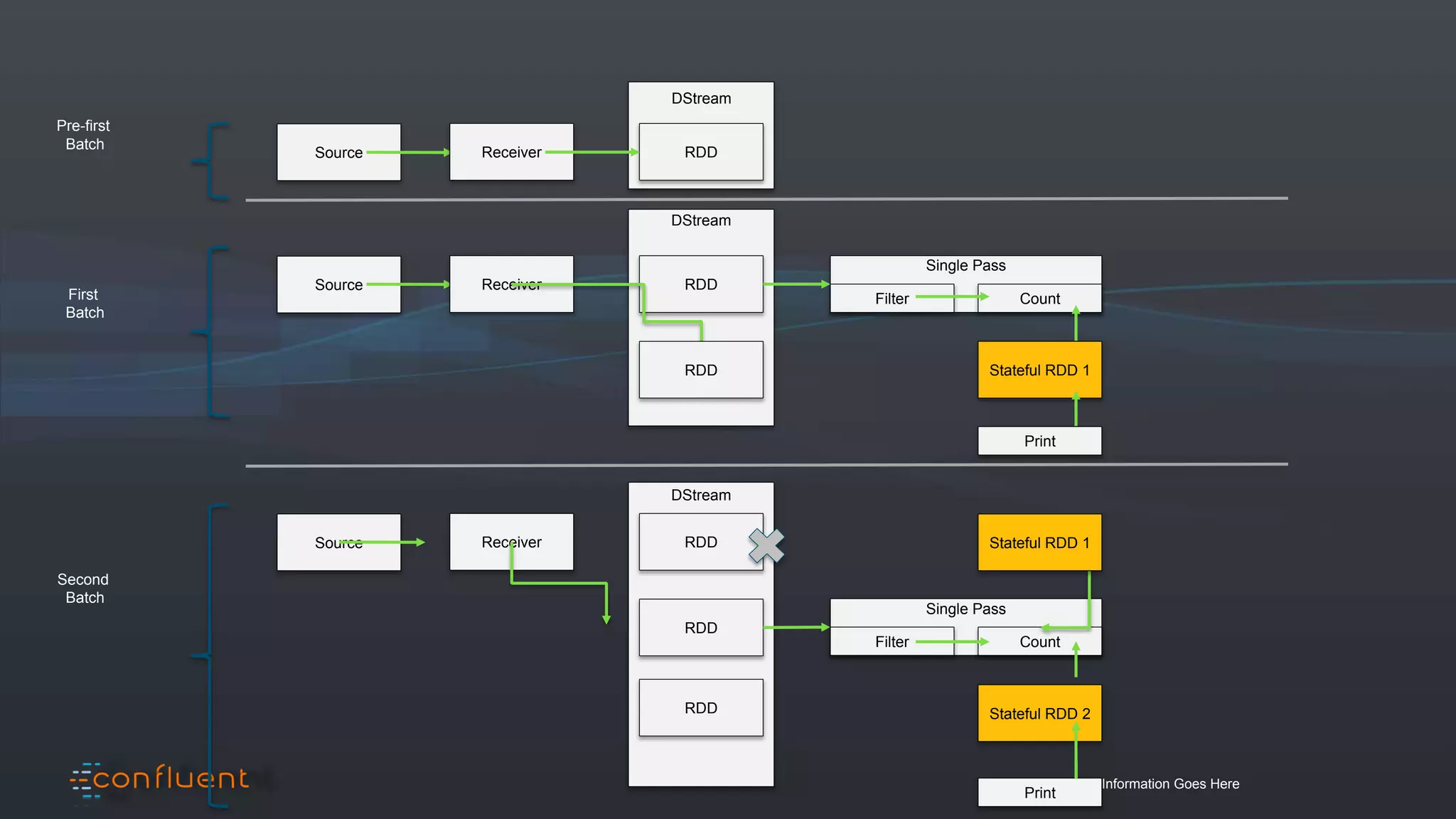

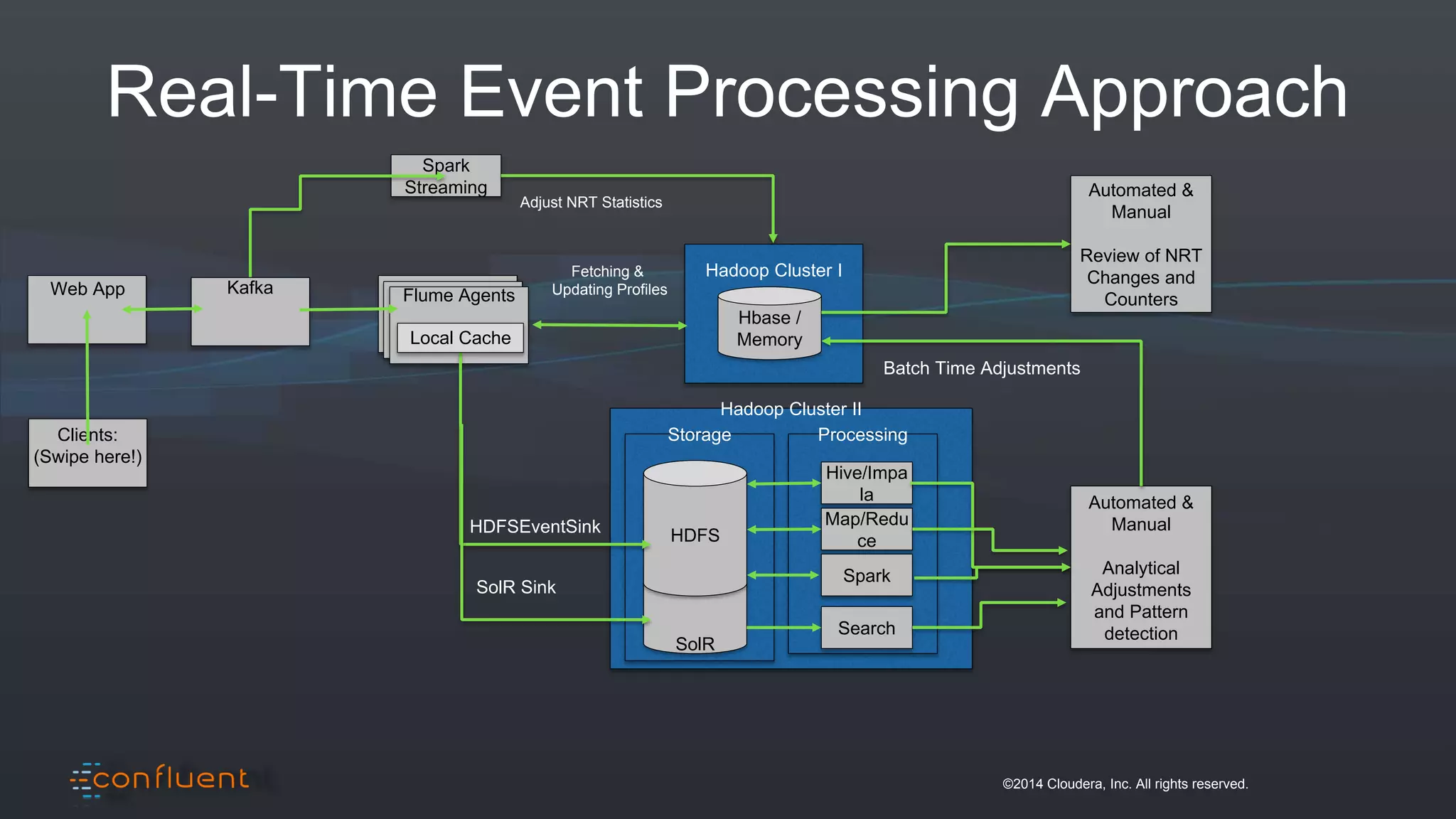
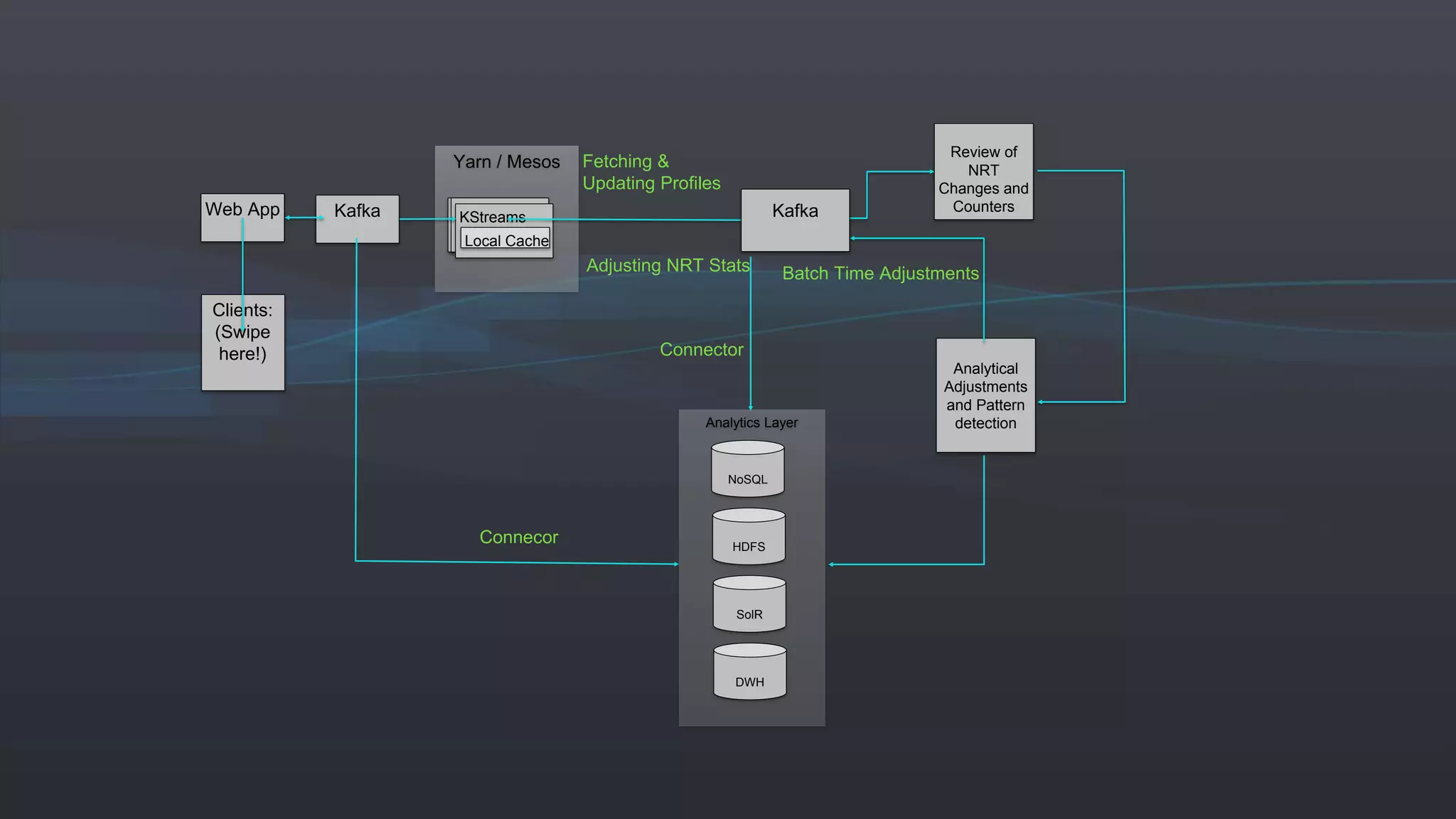
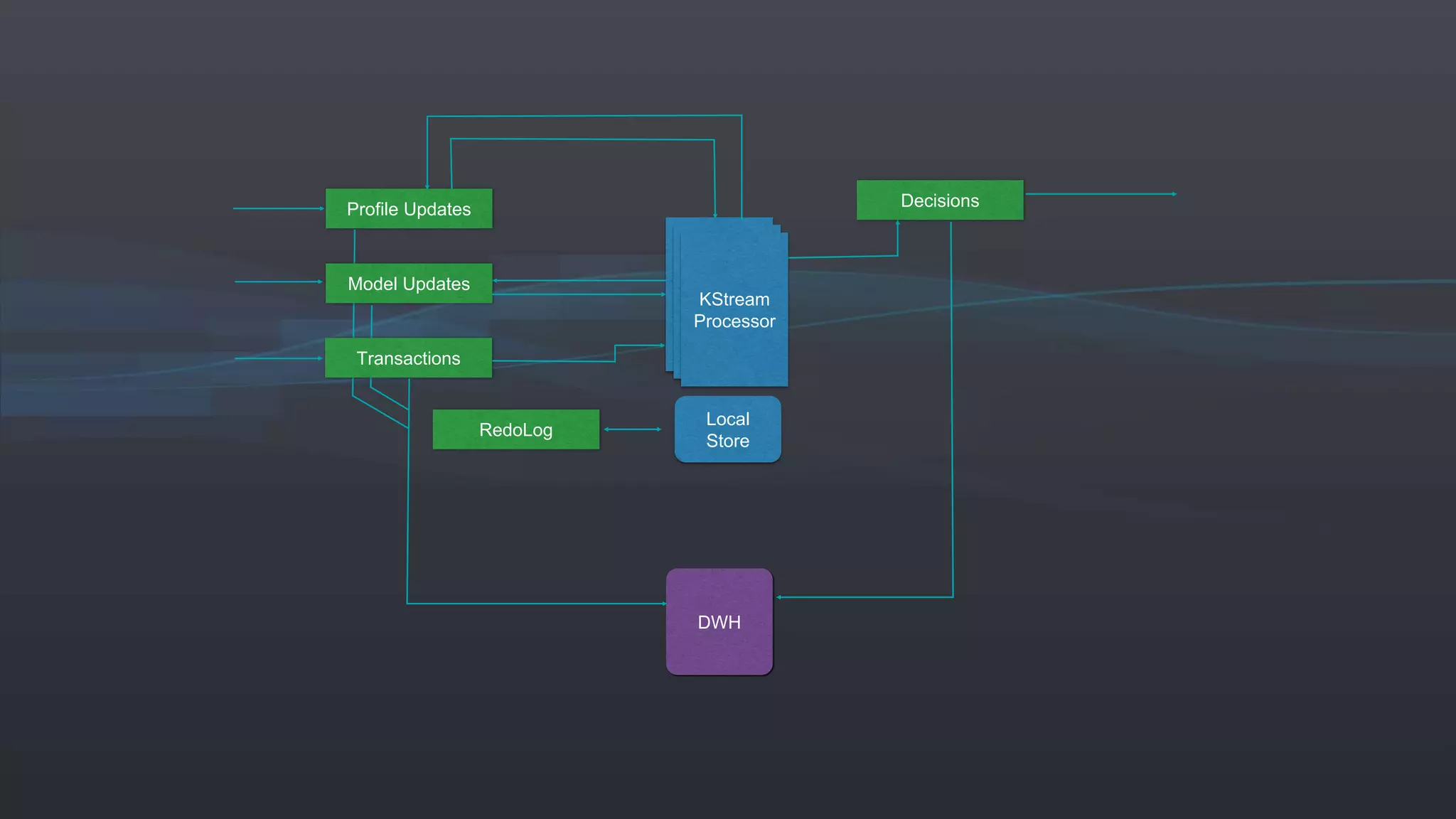

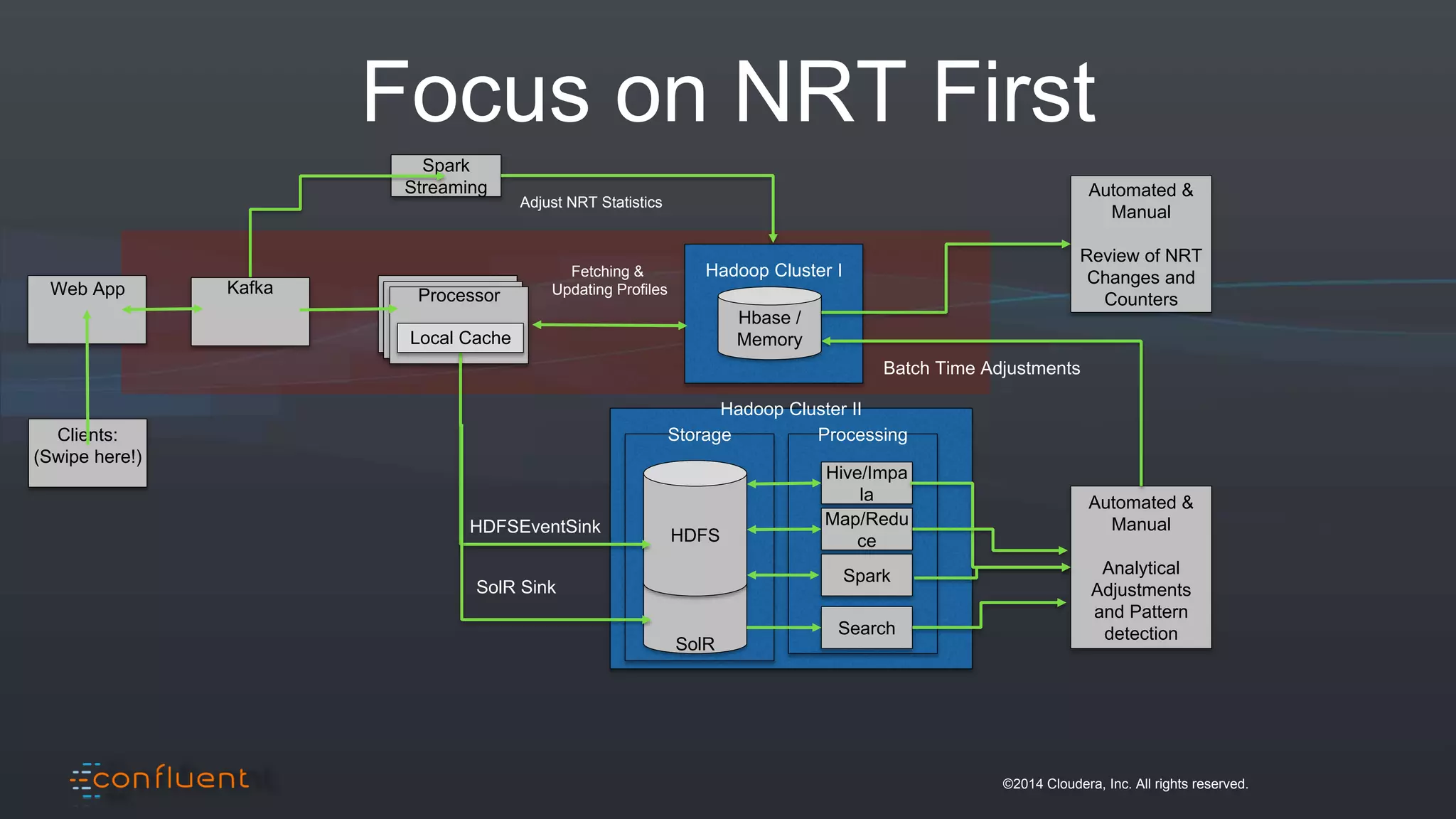
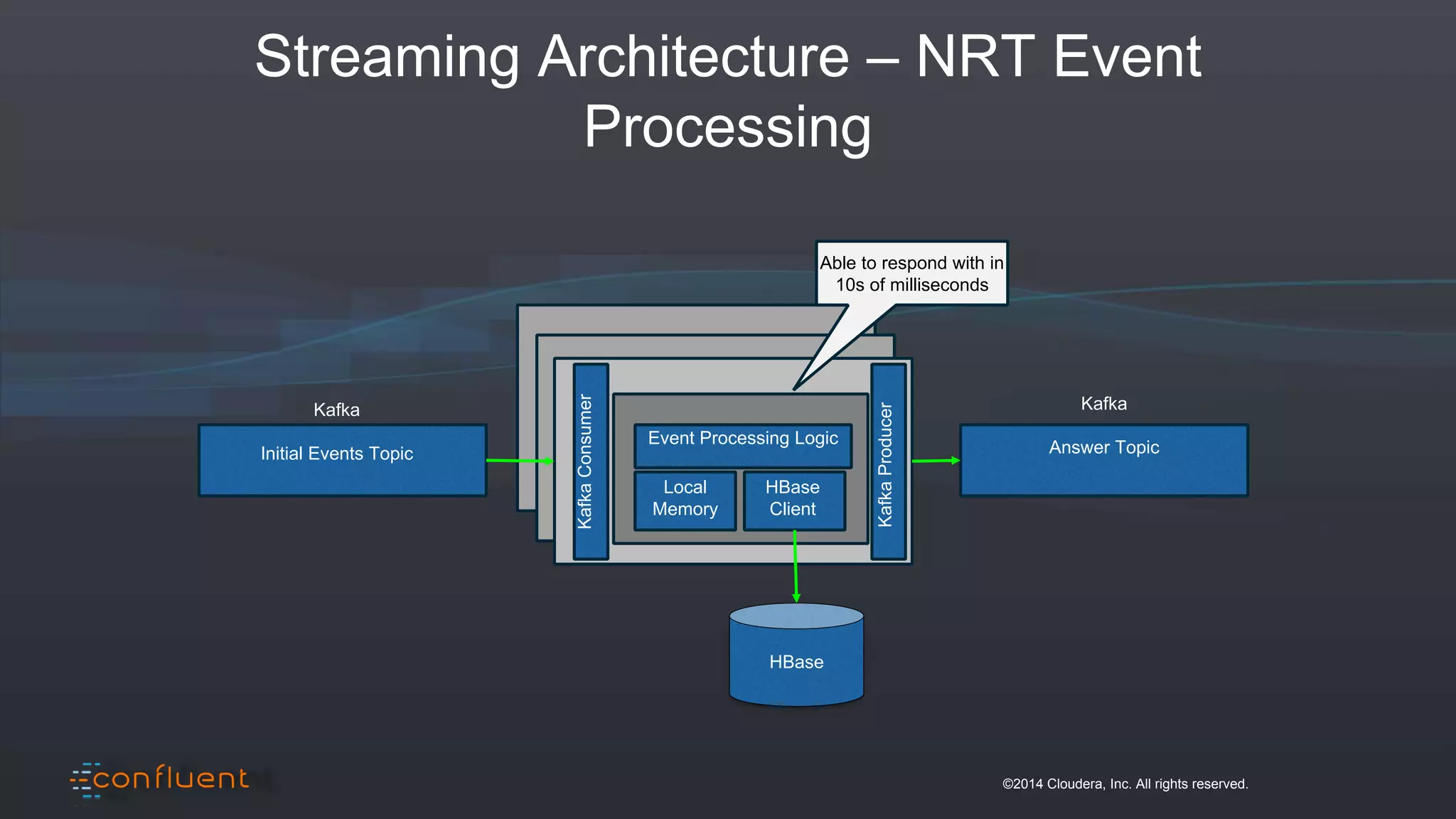
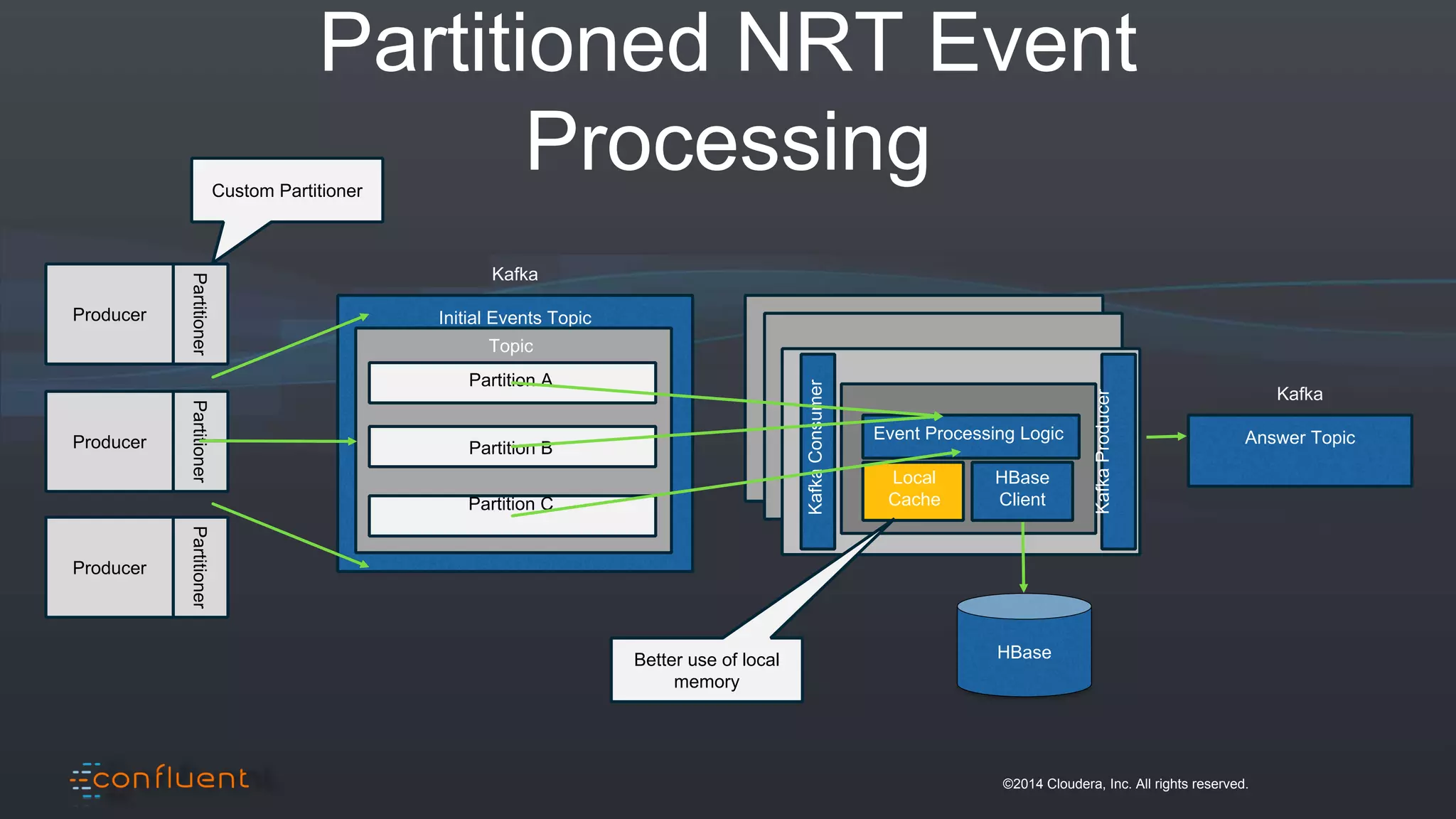


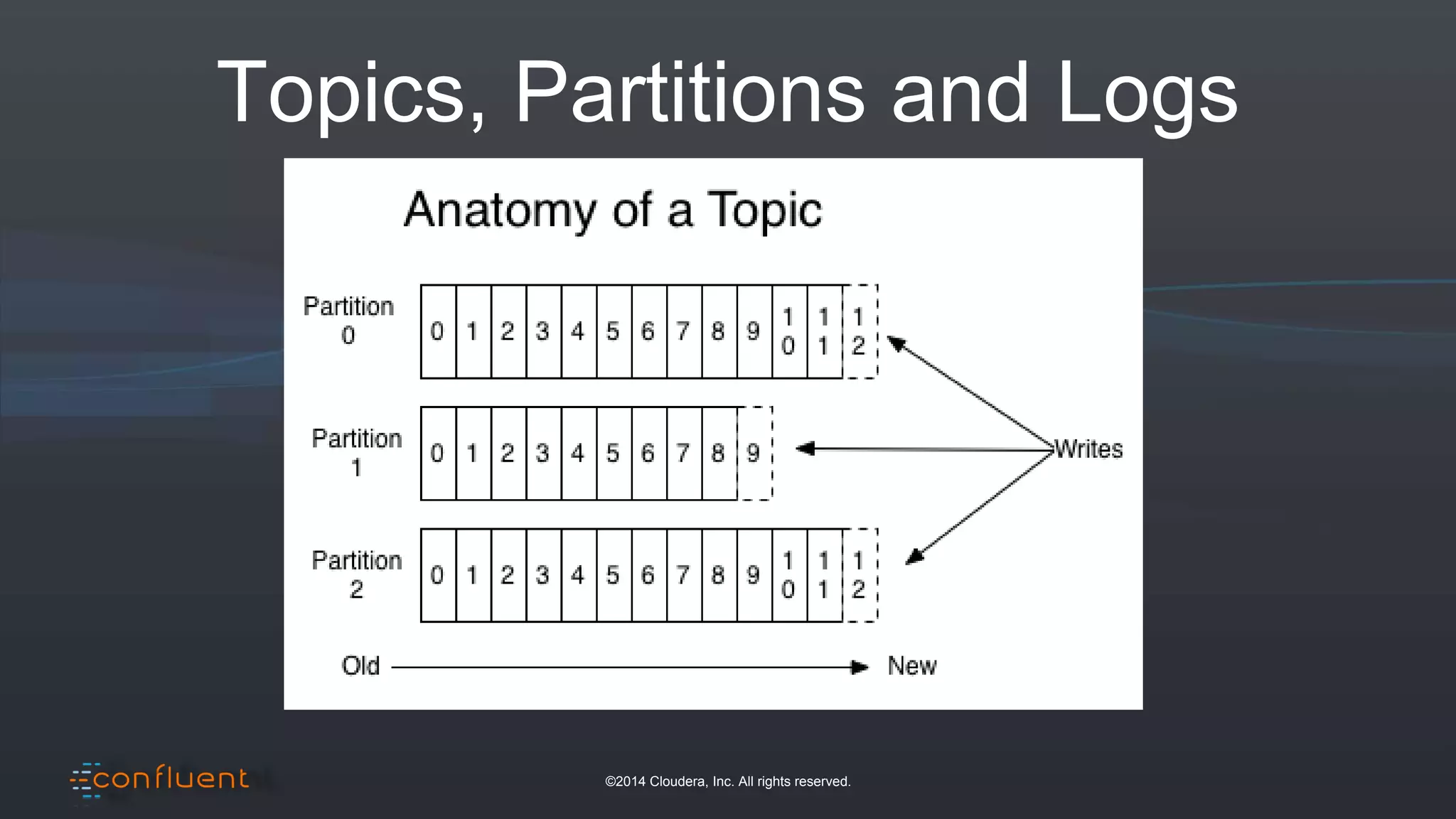
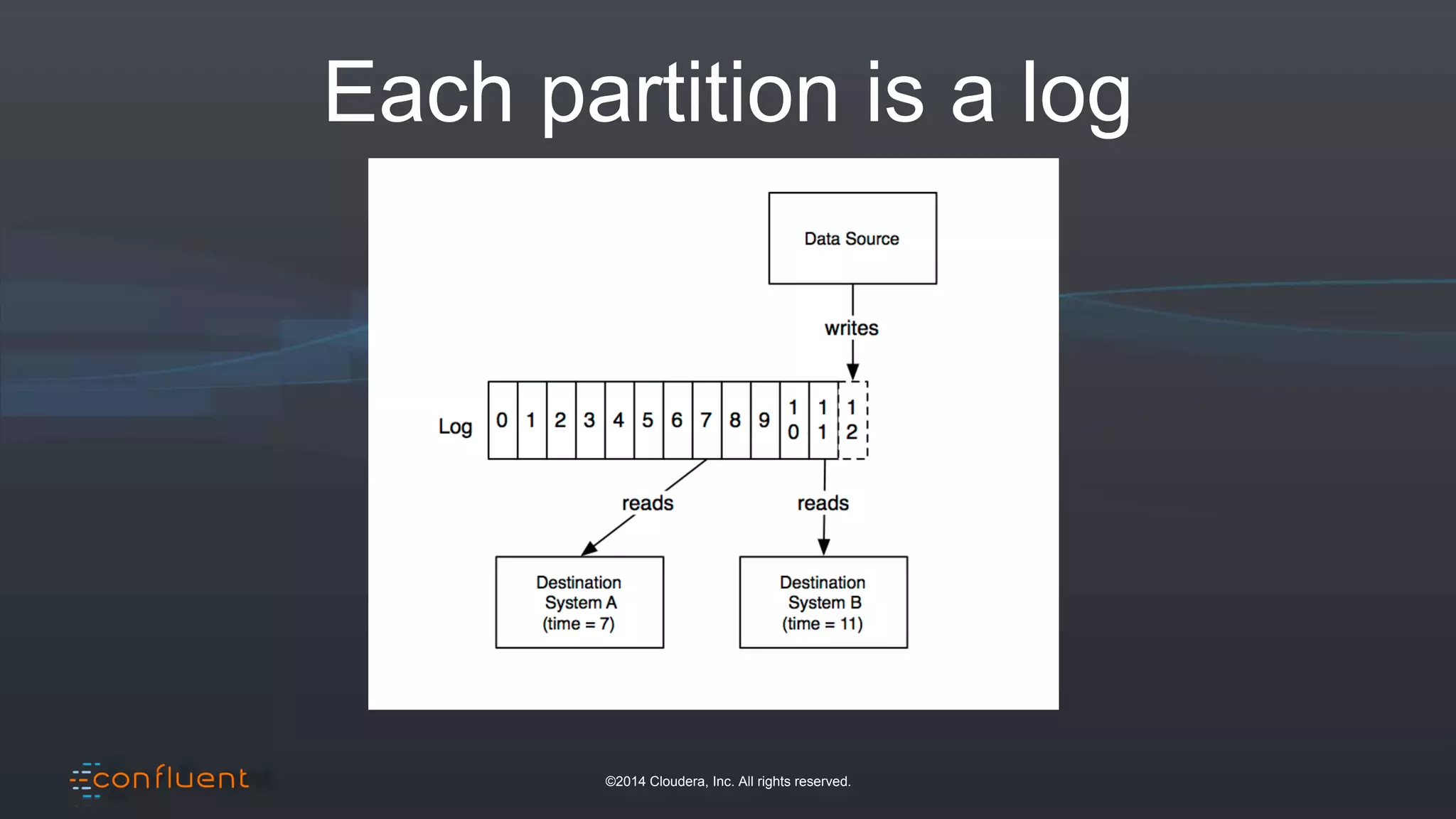
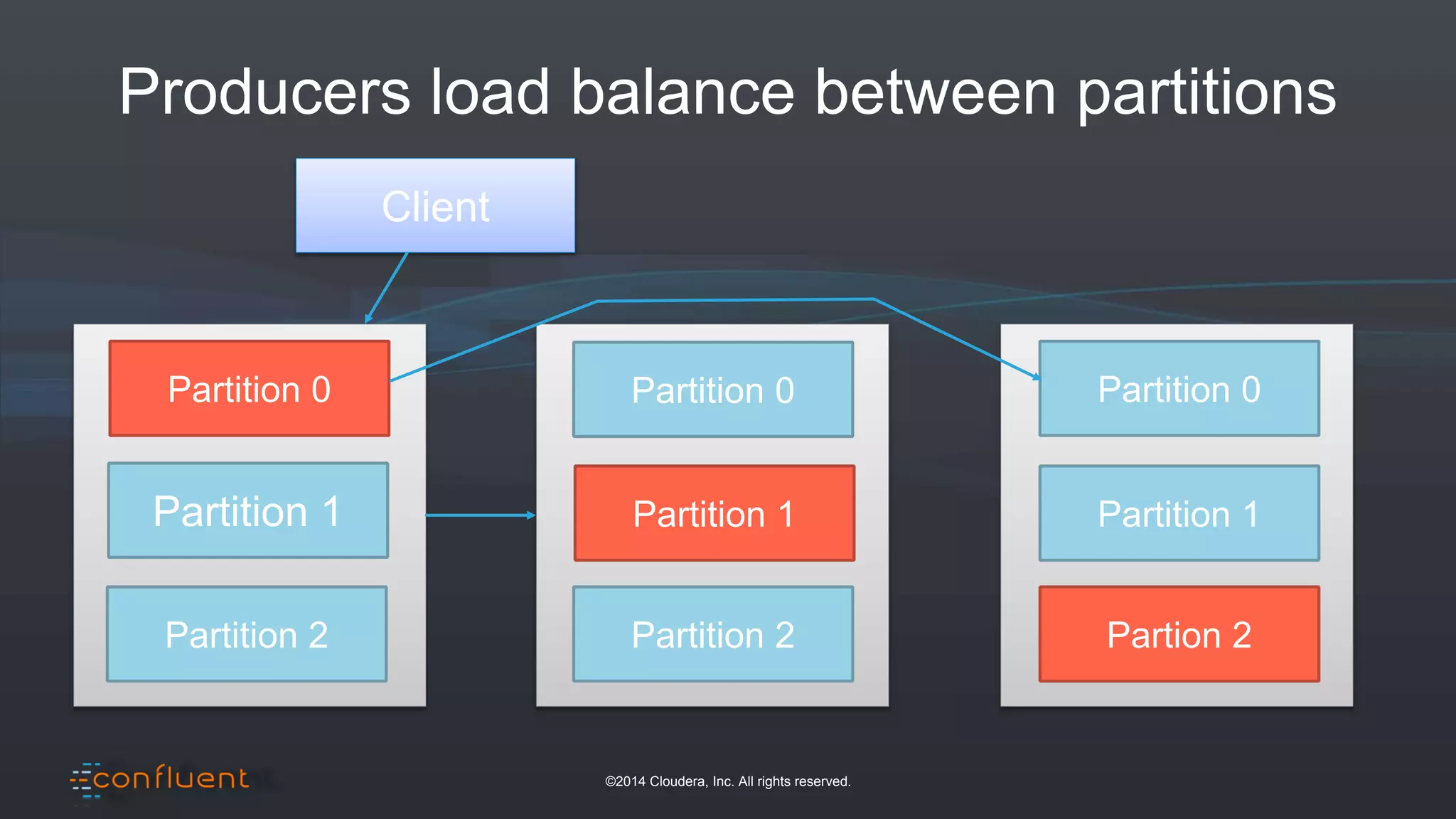
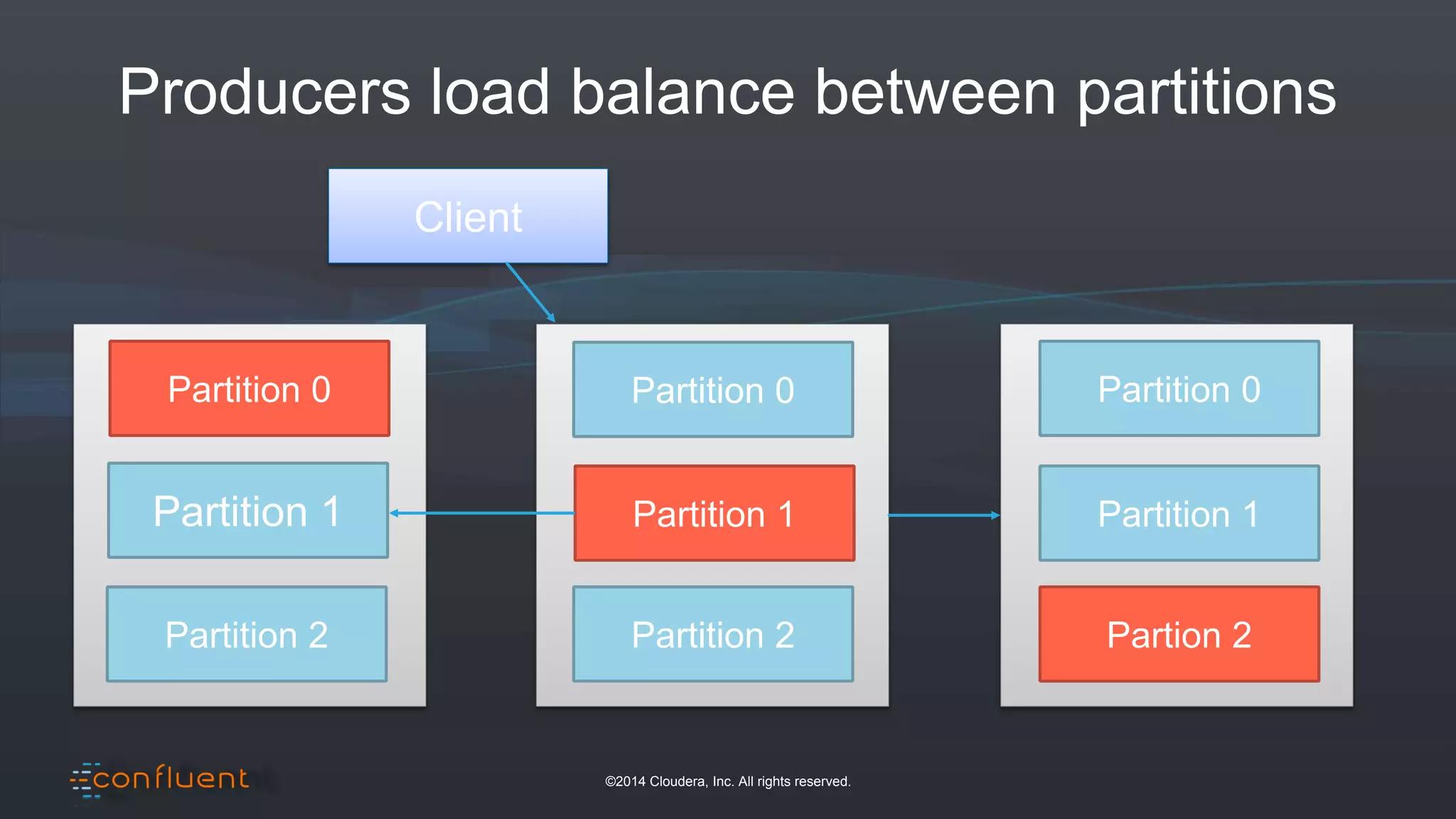
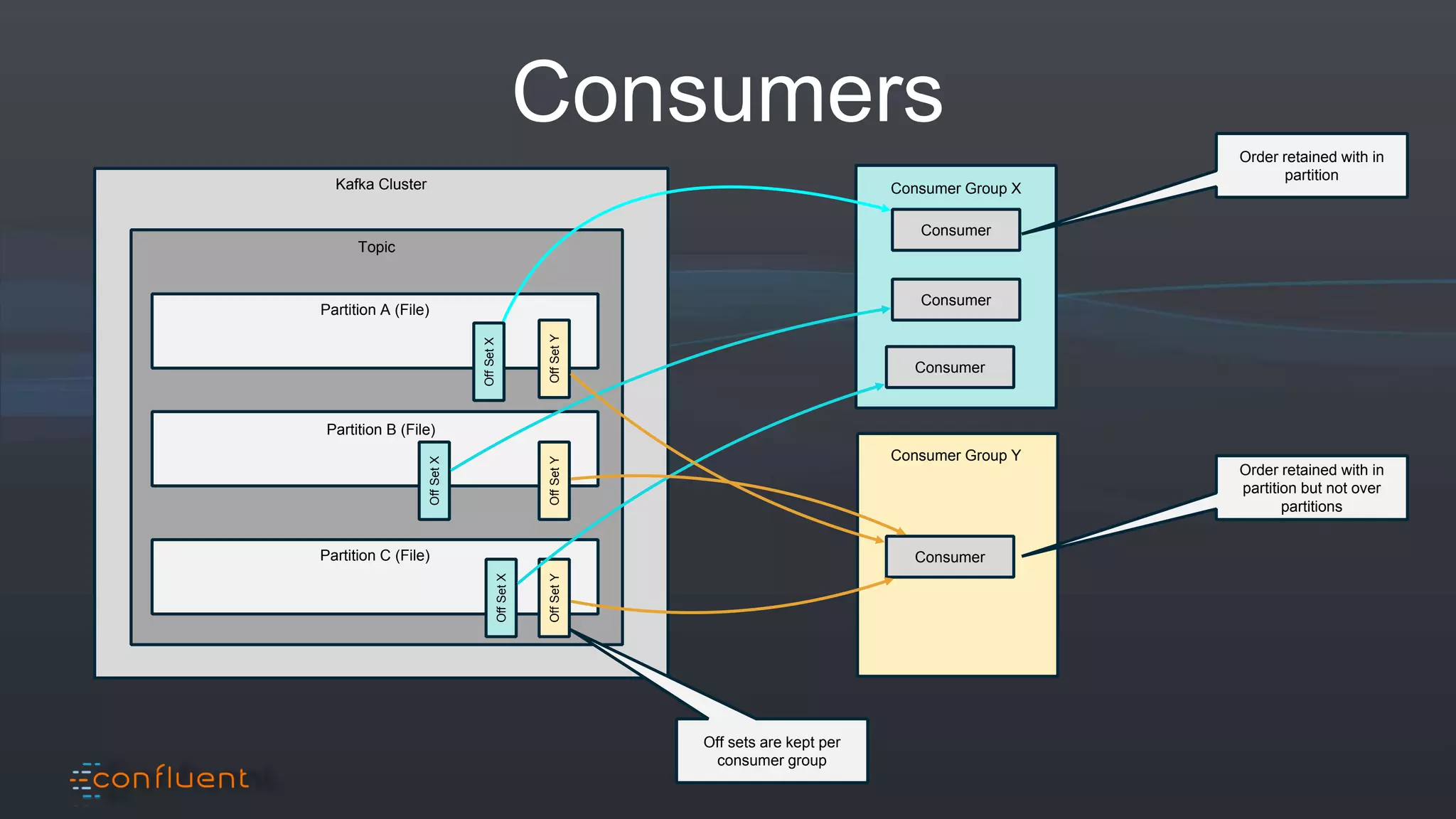
The document presents an overview of real-time anomaly detection using technologies like Kafka and Spark, focusing on high-level architecture and processing methodologies. It discusses various key technologies essential for handling stream data, including producers, consumers, and their operational structure. Additionally, it outlines the challenges posed by different types of fraud and emphasizes the importance of effective data management and analytics in addressing these issues.





















































































![[BDD 2025 - Full-Stack Development] Agentic AI Architecture: Redefining Syste...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-agenticaiarchitectureredefiningsystemcommunication-251124030838-e6c70cc2-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DevFest Strasbourg 2025] - NodeJs Can do that !!](https://cdn.slidesharecdn.com/ss_thumbnails/devfeststrasbourg2025-nodejscandothat-251127142731-da65b6fd-thumbnail.jpg?width=640&height=640&fit=bounds)


![[BDD 2025 - Full-Stack Development] PHP in AI Age: The Laravel Way. (Rizqy Hi...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-phpinaiagethelaravelway-251125012602-ef9d330e-thumbnail.jpg?width=640&height=640&fit=bounds)




![[BDD 2025 - Artificial Intelligence] AI for the Underdogs: Innovation for Sma...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-aifortheunderdogsinnovationforsmallbusinesses-251124030839-72a599a4-thumbnail.jpg?width=640&height=640&fit=bounds)
