Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
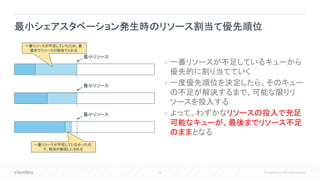
Change Language
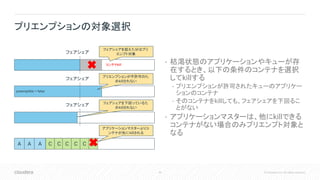
Language
English
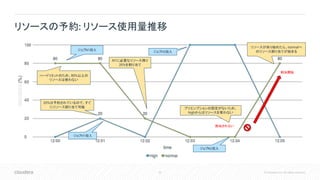
Español
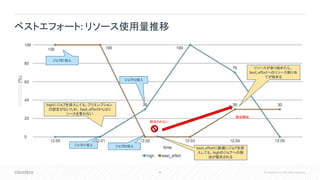
Português
Français
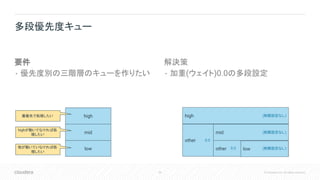
Deutsche
Cancel
Save
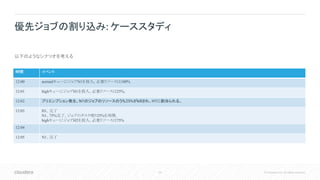
EN
Uploaded by
Cloudera Japan
12,483 views
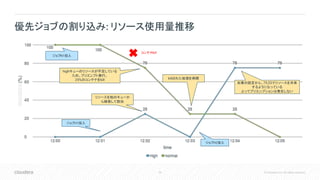
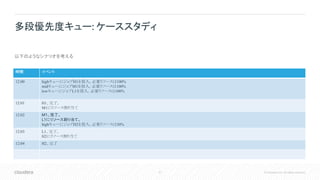
Apache Hadoop YARNとマルチテナントにおけるリソース管理
Apache Hadoop YARNのスケジューラを使用した、マルチテナントにおけるリソース管理の方法について紹介します。
Software
◦
Read more
11
Save
Share
Embed
Embed presentation
Download
Downloaded 51 times
1
/ 65
2
/ 65
3
/ 65
4
/ 65
5
/ 65
6
/ 65
7
/ 65
Most read
8
/ 65
Most read
9
/ 65
10
/ 65
11
/ 65
12
/ 65
13
/ 65
14
/ 65
15
/ 65
16
/ 65
17
/ 65
18
/ 65
19
/ 65
20
/ 65
21
/ 65
22
/ 65
23
/ 65
24
/ 65
Most read
25
/ 65
26
/ 65
27
/ 65
28
/ 65
29
/ 65
30
/ 65
31
/ 65
32
/ 65
33
/ 65
34
/ 65
35
/ 65
36
/ 65
37
/ 65
38
/ 65
39
/ 65
40
/ 65
41
/ 65
42
/ 65
43
/ 65
44
/ 65
45
/ 65
46
/ 65
47
/ 65
48
/ 65
49
/ 65
50
/ 65
51
/ 65
52
/ 65
53
/ 65
54
/ 65
55
/ 65
56
/ 65
57
/ 65
58
/ 65
59
/ 65
60
/ 65
61
/ 65
62
/ 65
63
/ 65
64
/ 65
65
/ 65
More Related Content
PDF
Apache Kafkaって本当に大丈夫?~故障検証のオーバービューと興味深い挙動の紹介~
by
NTT DATA OSS Professional Services
PDF
Hadoopのシステム設計・運用のポイント
by
Cloudera Japan
PDF
Apache Spark超入門 (Hadoop / Spark Conference Japan 2016 講演資料)
by
NTT DATA OSS Professional Services
PPTX
Apache Bigtopによるオープンなビッグデータ処理基盤の構築(オープンデベロッパーズカンファレンス 2021 Online 発表資料)
by
NTT DATA Technology & Innovation
PDF
Apache Sparkに手を出してヤケドしないための基本 ~「Apache Spark入門より」~ (デブサミ 2016 講演資料)
by
NTT DATA OSS Professional Services
PDF
Apache Bigtop3.2 (仮)(Open Source Conference 2022 Online/Hiroshima 発表資料)
by
NTT DATA Technology & Innovation
PPTX
BigtopでHadoopをビルドする(Open Source Conference 2021 Online/Spring 発表資料)
by
NTT DATA Technology & Innovation
PPTX
分析指向データレイク実現の次の一手 ~Delta Lake、なにそれおいしいの?~(NTTデータ テクノロジーカンファレンス 2020 発表資料)
by
NTT DATA Technology & Innovation
Apache Kafkaって本当に大丈夫?~故障検証のオーバービューと興味深い挙動の紹介~
by
NTT DATA OSS Professional Services
Hadoopのシステム設計・運用のポイント
by
Cloudera Japan
Apache Spark超入門 (Hadoop / Spark Conference Japan 2016 講演資料)
by
NTT DATA OSS Professional Services
Apache Bigtopによるオープンなビッグデータ処理基盤の構築(オープンデベロッパーズカンファレンス 2021 Online 発表資料)
by
NTT DATA Technology & Innovation
Apache Sparkに手を出してヤケドしないための基本 ~「Apache Spark入門より」~ (デブサミ 2016 講演資料)
by
NTT DATA OSS Professional Services
Apache Bigtop3.2 (仮)(Open Source Conference 2022 Online/Hiroshima 発表資料)
by
NTT DATA Technology & Innovation
BigtopでHadoopをビルドする(Open Source Conference 2021 Online/Spring 発表資料)
by
NTT DATA Technology & Innovation
分析指向データレイク実現の次の一手 ~Delta Lake、なにそれおいしいの?~(NTTデータ テクノロジーカンファレンス 2020 発表資料)
by
NTT DATA Technology & Innovation
What's hot
PPTX
え、まって。その並列分散処理、Kafkaのしくみでもできるの? Apache Kafkaの機能を利用した大規模ストリームデータの並列分散処理
by
NTT DATA Technology & Innovation
PDF
ストリーム処理を支えるキューイングシステムの選び方
by
Yoshiyasu SAEKI
PDF
NetflixにおけるPresto/Spark活用事例
by
Amazon Web Services Japan
PDF
Apache Hadoop & Hive 入門 (マーケティングデータ分析基盤技術勉強会)
by
Takeshi Mikami
PDF
Apache Kafka 0.11 の Exactly Once Semantics
by
Yoshiyasu SAEKI
PDF
Apache Impalaパフォーマンスチューニング #dbts2018
by
Cloudera Japan
PPTX
Hadoop -NameNode HAの仕組み-
by
Yuki Gonda
PDF
KafkaとAWS Kinesisの比較
by
Yoshiyasu SAEKI
PDF
ちょっと理解に自信がないな という皆さまに贈るHadoop/Sparkのキホン (IBM Datapalooza Tokyo 2016講演資料)
by
hamaken
PPTX
ポスト・ラムダアーキテクチャの切り札? Apache Hudi(NTTデータ テクノロジーカンファレンス 2020 発表資料)
by
NTT DATA Technology & Innovation
PPTX
Apache Spark on Kubernetes入門(Open Source Conference 2021 Online Hiroshima 発表資料)
by
NTT DATA Technology & Innovation
PDF
Apache Sparkにおけるメモリ - アプリケーションを落とさないメモリ設計手法 -
by
Yoshiyasu SAEKI
PDF
20210127 今日から始めるイベントドリブンアーキテクチャ AWS Expert Online #13
by
Amazon Web Services Japan
PPTX
大量のデータ処理や分析に使えるOSS Apache Sparkのご紹介(Open Source Conference 2020 Online/Kyoto ...
by
NTT DATA Technology & Innovation
PDF
40分でわかるHadoop徹底入門 (Cloudera World Tokyo 2014 講演資料)
by
hamaken
PPTX
Apache Sparkの基本と最新バージョン3.2のアップデート(Open Source Conference 2021 Online/Fukuoka ...
by
NTT DATA Technology & Innovation
PDF
20190521 AWS Black Belt Online Seminar Amazon Simple Email Service (Amazon SES)
by
Amazon Web Services Japan
PPTX
大規模データ活用向けストレージレイヤソフトのこれまでとこれから(NTTデータ テクノロジーカンファレンス 2019 講演資料、2019/09/05)
by
NTT DATA Technology & Innovation
PDF
Amazon Redshift パフォーマンスチューニングテクニックと最新アップデート
by
Amazon Web Services Japan
PDF
Cassandraとh baseの比較して入門するno sql
by
Yutuki r
え、まって。その並列分散処理、Kafkaのしくみでもできるの? Apache Kafkaの機能を利用した大規模ストリームデータの並列分散処理
by
NTT DATA Technology & Innovation
ストリーム処理を支えるキューイングシステムの選び方
by
Yoshiyasu SAEKI
NetflixにおけるPresto/Spark活用事例
by
Amazon Web Services Japan
Apache Hadoop & Hive 入門 (マーケティングデータ分析基盤技術勉強会)
by
Takeshi Mikami
Apache Kafka 0.11 の Exactly Once Semantics
by
Yoshiyasu SAEKI
Apache Impalaパフォーマンスチューニング #dbts2018
by
Cloudera Japan
Hadoop -NameNode HAの仕組み-
by
Yuki Gonda
KafkaとAWS Kinesisの比較
by
Yoshiyasu SAEKI
ちょっと理解に自信がないな という皆さまに贈るHadoop/Sparkのキホン (IBM Datapalooza Tokyo 2016講演資料)
by
hamaken
ポスト・ラムダアーキテクチャの切り札? Apache Hudi(NTTデータ テクノロジーカンファレンス 2020 発表資料)
by
NTT DATA Technology & Innovation
Apache Spark on Kubernetes入門(Open Source Conference 2021 Online Hiroshima 発表資料)
by
NTT DATA Technology & Innovation
Apache Sparkにおけるメモリ - アプリケーションを落とさないメモリ設計手法 -
by
Yoshiyasu SAEKI
20210127 今日から始めるイベントドリブンアーキテクチャ AWS Expert Online #13
by
Amazon Web Services Japan
大量のデータ処理や分析に使えるOSS Apache Sparkのご紹介(Open Source Conference 2020 Online/Kyoto ...
by
NTT DATA Technology & Innovation
40分でわかるHadoop徹底入門 (Cloudera World Tokyo 2014 講演資料)
by
hamaken
Apache Sparkの基本と最新バージョン3.2のアップデート(Open Source Conference 2021 Online/Fukuoka ...
by
NTT DATA Technology & Innovation
20190521 AWS Black Belt Online Seminar Amazon Simple Email Service (Amazon SES)
by
Amazon Web Services Japan
大規模データ活用向けストレージレイヤソフトのこれまでとこれから(NTTデータ テクノロジーカンファレンス 2019 講演資料、2019/09/05)
by
NTT DATA Technology & Innovation
Amazon Redshift パフォーマンスチューニングテクニックと最新アップデート
by
Amazon Web Services Japan
Cassandraとh baseの比較して入門するno sql
by
Yutuki r
Similar to Apache Hadoop YARNとマルチテナントにおけるリソース管理
PDF
Running Apache Spark on AWS
by
Noritaka Sekiyama
PDF
Presto on YARNの導入・運用
by
cyberagent
PPTX
Yarn resource-manager
by
Seiya Mizuno
PDF
Apache Big Data Miami 2017 - Hadoop Source Code Reading #23 #hadoopreading
by
Yahoo!デベロッパーネットワーク
PDF
マルチテナント Hadoop クラスタのためのモニタリング Best Practice
by
Hadoop / Spark Conference Japan
PPTX
Service Fabric での高密度配置
by
Takekazu Omi
PDF
Cloudera Manager4.0とNameNode-HAセミナー資料
by
Cloudera Japan
PPTX
Yarn application-master
by
Seiya Mizuno
PDF
CDHの歴史とCDH5新機能概要 #at_tokuben
by
Cloudera Japan
PPTX
The future of Apache Hadoop YARN
by
Seiya Mizuno
PDF
Start of a New era: Apache YARN 3.1 and Apache HBase 2.0
by
DataWorks Summit
PDF
Cloud Native Hadoop #cwt2016
by
Cloudera Japan
PDF
Apache Hadoop and YARN, current development status
by
NTT DATA OSS Professional Services
PPT
2010 04クラウド技術講座
by
sisawa
PDF
AgentCoreで実現するマルチテナントAIエージェント
by
IgaHironobu
PDF
Cloudera Manager 5 (hadoop運用) #cwt2013
by
Cloudera Japan
PDF
Cloudera サポートの現場から、YARN の最新事情 #hcj2014
by
Cloudera Japan
PDF
[JAWSBigData#11]Cloudera on AWSと Amazon EMRを両方本番運用し 3つの観点から比較してみる
by
Takahiro Moteki
PDF
Hadoop operation chaper 4
by
Yukinori Suda
PDF
20200811 AWS Black Belt Online Seminar CloudEndure
by
Amazon Web Services Japan
Running Apache Spark on AWS
by
Noritaka Sekiyama
Presto on YARNの導入・運用
by
cyberagent
Yarn resource-manager
by
Seiya Mizuno
Apache Big Data Miami 2017 - Hadoop Source Code Reading #23 #hadoopreading
by
Yahoo!デベロッパーネットワーク
マルチテナント Hadoop クラスタのためのモニタリング Best Practice
by
Hadoop / Spark Conference Japan
Service Fabric での高密度配置
by
Takekazu Omi
Cloudera Manager4.0とNameNode-HAセミナー資料
by
Cloudera Japan
Yarn application-master
by
Seiya Mizuno
CDHの歴史とCDH5新機能概要 #at_tokuben
by
Cloudera Japan
The future of Apache Hadoop YARN
by
Seiya Mizuno
Start of a New era: Apache YARN 3.1 and Apache HBase 2.0
by
DataWorks Summit
Cloud Native Hadoop #cwt2016
by
Cloudera Japan
Apache Hadoop and YARN, current development status
by
NTT DATA OSS Professional Services
2010 04クラウド技術講座
by
sisawa
AgentCoreで実現するマルチテナントAIエージェント
by
IgaHironobu
Cloudera Manager 5 (hadoop運用) #cwt2013
by
Cloudera Japan
Cloudera サポートの現場から、YARN の最新事情 #hcj2014
by
Cloudera Japan
[JAWSBigData#11]Cloudera on AWSと Amazon EMRを両方本番運用し 3つの観点から比較してみる
by
Takahiro Moteki
Hadoop operation chaper 4
by
Yukinori Suda
20200811 AWS Black Belt Online Seminar CloudEndure
by
Amazon Web Services Japan
More from Cloudera Japan
PPTX
Impala + Kudu を用いたデータウェアハウス構築の勘所 (仮)
by
Cloudera Japan
PPTX
機械学習の定番プラットフォームSparkの紹介
by
Cloudera Japan
PPTX
HDFS Supportaiblity Improvements
by
Cloudera Japan
PDF
分散DB Apache Kuduのアーキテクチャ DBの性能と一貫性を両立させる仕組み 「HybridTime」とは
by
Cloudera Japan
PDF
HBase Across the World #LINE_DM
by
Cloudera Japan
PDF
Cloudera のサポートエンジニアリング #supennight
by
Cloudera Japan
PDF
Train, predict, serve: How to go into production your machine learning model
by
Cloudera Japan
PDF
Apache Kuduを使った分析システムの裏側
by
Cloudera Japan
PDF
Cloudera in the Cloud #CWT2017
by
Cloudera Japan
PDF
先行事例から学ぶ IoT / ビッグデータの始め方
by
Cloudera Japan
PPTX
Clouderaが提供するエンタープライズ向け運用、データ管理ツールの使い方 #CW2017
by
Cloudera Japan
PDF
How to go into production your machine learning models? #CWT2017
by
Cloudera Japan
PDF
Apache Kudu - Updatable Analytical Storage #rakutentech
by
Cloudera Japan
PPTX
Hue 4.0 / Hue Meetup Tokyo #huejp
by
Cloudera Japan
PDF
Apache Kuduは何がそんなに「速い」DBなのか? #dbts2017
by
Cloudera Japan
PDF
Cloudera Data Science WorkbenchとPySparkで 好きなPythonライブラリを 分散で使う #cadeda
by
Cloudera Japan
PDF
Cloudera + MicrosoftでHadoopするのがイイらしい。 #CWT2016
by
Cloudera Japan
PDF
大規模データに対するデータサイエンスの進め方 #CWT2016
by
Cloudera Japan
PDF
#cwt2016 Apache Kudu 構成とテーブル設計
by
Cloudera Japan
PDF
#cwt2016 Cloudera Managerを用いた Hadoop のトラブルシューティング
by
Cloudera Japan
Impala + Kudu を用いたデータウェアハウス構築の勘所 (仮)
by
Cloudera Japan
機械学習の定番プラットフォームSparkの紹介
by
Cloudera Japan
HDFS Supportaiblity Improvements
by
Cloudera Japan
分散DB Apache Kuduのアーキテクチャ DBの性能と一貫性を両立させる仕組み 「HybridTime」とは
by
Cloudera Japan
HBase Across the World #LINE_DM
by
Cloudera Japan
Cloudera のサポートエンジニアリング #supennight
by
Cloudera Japan
Train, predict, serve: How to go into production your machine learning model
by
Cloudera Japan
Apache Kuduを使った分析システムの裏側
by
Cloudera Japan
Cloudera in the Cloud #CWT2017
by
Cloudera Japan
先行事例から学ぶ IoT / ビッグデータの始め方
by
Cloudera Japan
Clouderaが提供するエンタープライズ向け運用、データ管理ツールの使い方 #CW2017
by
Cloudera Japan
How to go into production your machine learning models? #CWT2017
by
Cloudera Japan
Apache Kudu - Updatable Analytical Storage #rakutentech
by
Cloudera Japan
Hue 4.0 / Hue Meetup Tokyo #huejp
by
Cloudera Japan
Apache Kuduは何がそんなに「速い」DBなのか? #dbts2017
by
Cloudera Japan
Cloudera Data Science WorkbenchとPySparkで 好きなPythonライブラリを 分散で使う #cadeda
by
Cloudera Japan
Cloudera + MicrosoftでHadoopするのがイイらしい。 #CWT2016
by
Cloudera Japan
大規模データに対するデータサイエンスの進め方 #CWT2016
by
Cloudera Japan
#cwt2016 Apache Kudu 構成とテーブル設計
by
Cloudera Japan
#cwt2016 Cloudera Managerを用いた Hadoop のトラブルシューティング
by
Cloudera Japan
Apache Hadoop YARNとマルチテナントにおけるリソース管理
1.
Apache Hadoop YARNと マルチテナントにおけるリソース管理
2.
2 © Cloudera,
Inc. All rights reserved. • YARN概要 • YARNアプリケーションの動作の仕組み • YARNにおけるリソース管理の基礎知識 • フェアスケジューラ • フェアスケジューラの設定の基本 • キュー配置ポリシー • プリエンプション • ケーススタディ • tips 目次
3.
© Cloudera, Inc.
All rights reserved. YARN概要
4.
4 © Cloudera,
Inc. All rights reserved. • YARN: Yet Another Resource Negotiator • Apache Hadoopエコシステムのためのリソース管理レイヤー • 数台から数千台のサーバやインスタンスのリソースオーケストレーションを行う分散 サービス YARNとは
5.
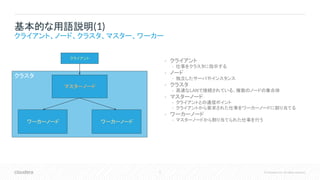
5 © Cloudera,
Inc. All rights reserved. • クライアント • 仕事をクラスタに指示する • ノード • 独立したサーバやインスタンス • クラスタ • 高速なLANで接続されている、複数のノードの集合体 • マスターノード • クライアントとの通信ポイント • クライアントから要求された仕事をワーカーノードに割り当てる • ワーカーノード • マスターノードから割り当てられた仕事を行う 基本的な用語説明(1) クライアント、ノード、クラスタ、マスター、ワーカー クラスタ マスターノード クライアント ワーカーノード ワーカーノード
6.
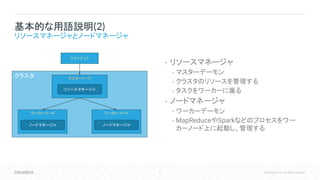
6 © Cloudera,
Inc. All rights reserved. クラスタ • リソースマネージャ • マスターデーモン • クラスタのリソースを管理する • タスクをワーカーに振る • ノードマネージャ • ワーカーデーモン • MapReduceやSparkなどのプロセスをワー カーノード上に起動し、管理する 基本的な用語説明(2) リソースマネージャとノードマネージャ マスターノード ワーカーノード クライアント リソースマネージャ ノードマネージャ ワーカーノード ノードマネージャ
7.
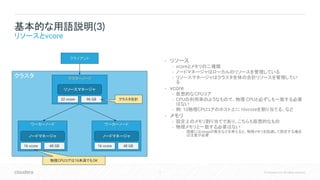
7 © Cloudera,
Inc. All rights reserved. クラスタ • リソース • vcoreとメモリの二種類 • ノードマネージャはローカルのリソースを管理している • リソースマネージャはクラスタ全体の合計リソースを管理してい る • vcore • 仮想的なCPUコア • CPUの利用率のようなもので、物理 CPUと必ずしも一致する必要 はない • 例: 10物理CPUコアのホスト上に16vcoreを割り当てる、など • メモリ • 設定上のメモリ割り当てであり、こちらも仮想的なもの • 物理メモリと一致する必要はない • 現実にはswapの発生などを考えると、物理メモリを超過して設定する場合 は注意が必要 基本的な用語説明(3) リソースとvcore マスターノード ワーカーノード クライアント リソースマネージャ ノードマネージャ ワーカーノード ノードマネージャ 16 vcore 48 GB 16 vcore 48 GB 32 vcore 96 GB クラスタ合計 物理CPUコアは16未満でもOK
8.
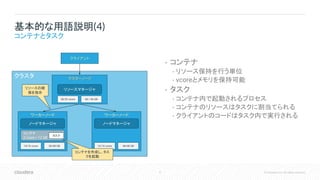
8 © Cloudera,
Inc. All rights reserved. クラスタ • コンテナ • リソース保持を行う単位 • vcoreとメモリを保持可能 • タスク • コンテナ内で起動されるプロセス • コンテナのリソースはタスクに割当てられる • クライアントのコードはタスク内で実行される 基本的な用語説明(4) コンテナとタスク マスターノード ワーカーノード クライアント リソースマネージャ ノードマネージャ ワーカーノード ノードマネージャ 14/16 vcore 36/48 GB 16/16 vcore 48/48 GB 30/32 vcore 84 / 96 GB コンテナ 2 vcore / 12 GB リソースの確 保を指示 タスク コンテナを作成し、タス クを起動
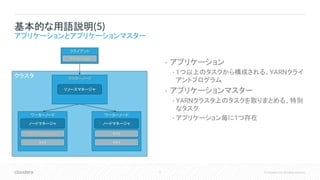
9.
9 © Cloudera,
Inc. All rights reserved. クラスタ • アプリケーション • 1つ以上のタスクから構成される、YARNクライ アントプログラム • アプリケーションマスター • YARNクラスタ上のタスクを取りまとめる、特別 なタスク • アプリケーション毎に1つ存在 基本的な用語説明(5) アプリケーションとアプリケーションマスター マスターノード ワーカーノード クライアント リソースマネージャ ノードマネージャ ワーカーノード ノードマネージャ アプリケーションマスター タスク タスク タスク アプリケーション
10.
© Cloudera, Inc.
All rights reserved. YARNアプリケーションの動作の仕組み
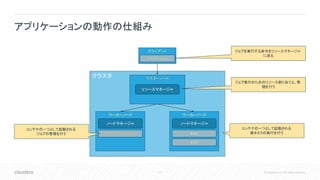
11.
11 © Cloudera,
Inc. All rights reserved. アプリケーションの動作の仕組み クラスタ マスターノード ワーカーノード クライアント リソースマネージャ ノードマネージャ ワーカーノード ノードマネージャ アプリケーションマスター タスク タスク アプリケーション ジョブを実行する命令をリソースマネージャ に送る ジョブ実行のためのリソース割り当てと、管 理を行う コンテナの一つとして起動される ジョブの管理を行う コンテナの一つとして起動される 実タスクの実行を行う
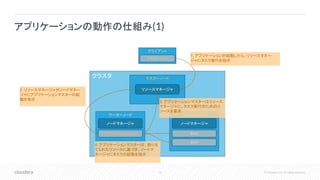
12.
12 © Cloudera,
Inc. All rights reserved. アプリケーションの動作の仕組み(1) クラスタ マスターノード ワーカーノード クライアント リソースマネージャ ノードマネージャ ワーカーノード ノードマネージャ アプリケーション 1. アプリケーションが起動したら、リソースマネー ジャにタスク実行を指示 アプリケーションマスター 2. リソースマネージャがノードマネー ジャにアプリケーションマスターの起 動を指示 タスク タスク 3. アプリケーションマスターはリソース マネージャに、タスク実行のためのリ ソースを要求 4. アプリケーションマスターは、割り当 てられたリソースに基づき、ノードマ ネージャにタスクの起動を指示
13.
13 © Cloudera,
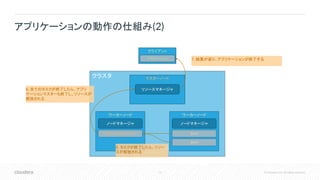
Inc. All rights reserved. アプリケーションの動作の仕組み(2) クラスタ マスターノード ワーカーノード クライアント リソースマネージャ ノードマネージャ ワーカーノード ノードマネージャ アプリケーション アプリケーションマスター タスク タスク 5. タスクが終了したら、リソー スが解放される 6. 全てのタスクが終了したら、アプリ ケーションマスターも終了し、リソースが 解放される 7. 結果が返り、アプリケーションが終了する
14.
© Cloudera, Inc.
All rights reserved. YARNにおけるリソース管理の基礎知識
15.
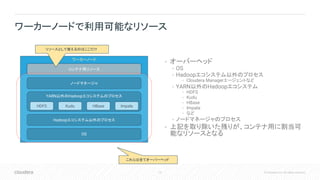
15 © Cloudera,
Inc. All rights reserved. • オーバーヘッド • OS • Hadoopエコシステム以外のプロセス • Cloudera Managerエージェントなど • YARN以外のHadoopエコシステム • HDFS • Kudu • HBase • Impala • など • ノードマネージャのプロセス • 上記を取り除いた残りが、コンテナ用に割当可 能なリソースとなる ワーカーノードで利用可能なリソース ワーカーノード ノードマネージャ OS Hadoopエコシステム以外のプロセス YARN以外のHadoopエコシステムのプロセス HDFS HBaseKudu Impala コンテナ用リソース これらは全てオーバーヘッド リソースとして使えるのはここだけ
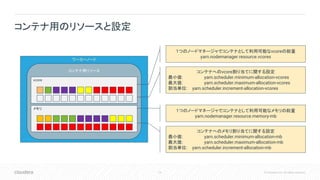
16.
16 © Cloudera,
Inc. All rights reserved. コンテナ用のリソースと設定 ワーカーノード コンテナ用リソース vcore メモリ 1つのノードマネージャでコンテナとして利用可能なvcoreの総量 yarn.nodemanager.resource.vcores コンテナへのvcore割り当てに関する設定 最小値: yarn.scheduler.minimum-allocation-vcores 最大値: yarn.scheduler.maximum-allocation-vcores 割当単位: yarn.scheduler.increment-allocation-vcores 1つのノードマネージャでコンテナとして利用可能なメモリの総量 yarn.nodemanager.resource.memory-mb コンテナへのメモリ割り当てに関する設定 最小値: yarn.scheduler.minimum-allocation-mb 最大値: yarn.scheduler.maximum-allocation-mb 割当単位: yarn.scheduler.increment-allocation-mb
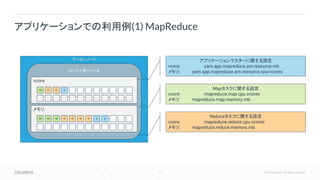
17.
17 © Cloudera,
Inc. All rights reserved. アプリケーションでの利用例(1) MapReduce ワーカーノード コンテナ用リソース vcore M R R A メモリ M M M R R R R A A アプリケーションマスターに関する設定 vcore: yarn.app.mapreduce.am.resource.mb メモリ: yarn.app.mapreduce.am.resource.cpu-vcores Mapタスクに関する設定 vcore: mapreduce.map.cpu.vcores メモリ: mapreduce.map.memory.mb Reduceタスクに関する設定 vcore: mapreduce.reduce.cpu.vcores メモリ: mapreduce.reduce.memory.mb
18.
18 © Cloudera,
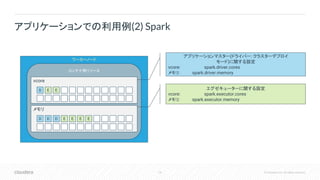
Inc. All rights reserved. アプリケーションでの利用例(2) Spark ワーカーノード コンテナ用リソース vcore D E メモリ D D D E E E E アプリケーションマスター(ドライバー: クラスターデプロイ モード)に関する設定 vcore: spark.driver.cores メモリ: spark.driver.memory エグゼキューターに関する設定 vcore: spark.executor.cores メモリ: spark.executor.memory E
19.
© Cloudera, Inc.
All rights reserved. フェアスケジューラ
20.
20 © Cloudera,
Inc. All rights reserved. • いつ、どこで、どのジョブを、どの程度のリソースを使って実行するかを決める機構 • YARNでは以下の3つのスケジューラが存在する • フェアスケジューラ • FIFOスケジューラ • キャパシティスケジューラ • Clouderaではフェアスケジューラを推奨しているため、本スライドでは特に断りがない 限り、スケジューラはフェアスケジューラを指すものとする スケジューラ
21.
21 © Cloudera,
Inc. All rights reserved. • Fair Scheduler: 公平なスケジューラ • 重み付けされたリソースキュー(リソースプール)ごとに、公平にリソースを配分してい くスケジューラ • Clouderaで採用しているスケジューラの正式名称はDRF(Dominant Resource Fairness)スケジューラ • 以後、特に断りがない限りフェアスケジューラとはDRFのことを指すものとする フェアスケジューラとは
22.
22 © Cloudera,
Inc. All rights reserved. • YARNのスケジューラの基本構造 • 階層構造を持つことが可能 • アプリケーションはキューに割当てられ る • 最上位の親キューは root という • root 以外の全てのキューは親キューを 持つ キュー root sales marketing datascience eastjapan westjapan batch adhoc besteffort smalljob
23.
23 © Cloudera,
Inc. All rights reserved. ウェイトによるリソース配分 root sales marketing datascience eastjapan westjapan batch adhoc besteffort smalljob 100 30 30 40 15 15 2 1 100 (設定なし) 同一階層におけるウェイトの設定で、リソース配分の比率が決まる salesは全体の30%のリソースを利用できる あくまで同一階層のウェイトのみを参照する batchとadhocの場合、2:1の比率でmarketingのリソースを配分する これは全体の20%と10%に相当する ベストエフォートのキューを作る場合、ウェイトを設定しなければいい besteffortキューは、smalljobで何もジョブが動いていないときのみ利用可能とな る
24.
24 © Cloudera,
Inc. All rights reserved. • 設定ファイルはxml形式 • fair-scheduler.xml に記述 • Cloudera Managerを使ってクラスタ管 理している場合は不要 設定方法 (XMLファイルの場合) <?xml version="1.0" encoding="UTF-8" standalone="yes"?> <allocations> <queue name="root"> <schedulingPolicy>drf</schedulingPolicy> <queue name="default"> <schedulingPolicy>drf</schedulingPolicy> </queue> <queue name="users" type="parent"> <schedulingPolicy>drf</schedulingPolicy> </queue> </queue> <queuePlacementPolicy> <rule name="specified" create="true"/> <rule name="nestedUserQueue"> <rule name="default" queue="users"/> </rule> <rule name="default" create="true"/> </queuePlacementPolicy> </allocations>
25.
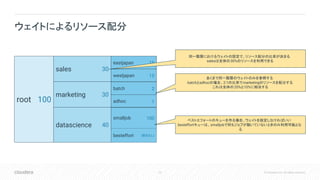
25 © Cloudera,
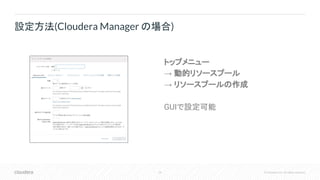
Inc. All rights reserved. トップメニュー → 動的リソースプール → リソースプールの作成 GUIで設定可能 設定方法(Cloudera Manager の場合)
26.
© Cloudera, Inc.
All rights reserved. フェアスケジューラの設定の基本
27.
27 © Cloudera,
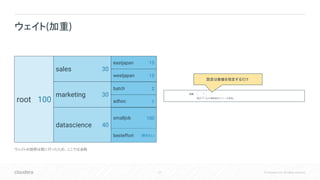
Inc. All rights reserved. ウェイト(加重) root sales marketing datascience eastjapan westjapan batch adhoc besteffort smalljob 100 30 30 40 15 15 2 1 100 (設定なし) ウェイトの説明は既に行ったため、ここでは省略 設定は数値を指定するだけ
28.
28 © Cloudera,
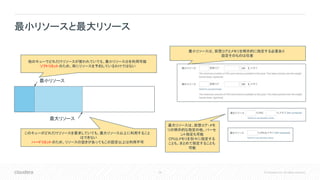
Inc. All rights reserved. 最小リソースと最大リソース 他のキューでどれだけリソースが使われていても、最小リソース分を利用可能 ソフトリミットのため、常にリソースを予約しているわけではない 最小リソース 最大リソース このキューがどれだけリソースを要求していても、最大リソース以上に利用すること はできない ハードリミットのため、リソースの空きがあってもこの設定以上は利用不可 最小リソースは、仮想コアとメモリを明示的に指定する必要あり 設定そのものは任意 最大リソースは、仮想コア・メモ リの明示的な指定の他、パーセ ント指定も可能 CPUとメモリを別々に指定する ことも、まとめて指定することも 可能
29.
29 © Cloudera,
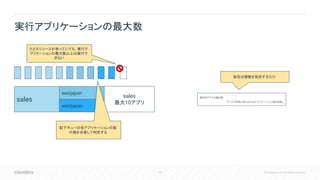
Inc. All rights reserved. 実行アプリケーションの最大数 sales たとえリソースが余っていても、実行ア プリケーションの最大数以上は実行で きない 設定は個数を指定するだけ eastjapan westjapan sales 最大10アプリ 配下キューの全アプリケーションの実 行数を合算して判定する
30.
30 © Cloudera,
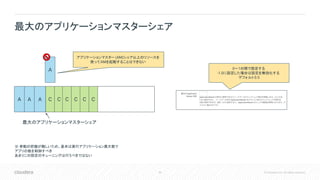
Inc. All rights reserved. 最大のアプリケーションマスターシェア 0〜1の間で設定する -1.0に設定した場合は設定を無効化する デフォルト0.5 A A A C C C C C C A アプリケーションマスター (AM)シェア以上のリソースを 使ってAMを起動することはできない 最大のアプリケーションマスターシェア ※ 挙動の把握が難しいため、基本は実行アプリケーション最大数で アプリの数を制御すべき あまりこの設定のチューニングは行うべきではない
31.
31 © Cloudera,
Inc. All rights reserved. アクセス制御リスト サブミット権限 管理者権限 ユーザー tanaka,sato suzuki グループ sales,ops admin キューに対するジョブの投入権限 現状はジョブのkillのみ可能 ユーザー単位とグループ単位で設定可能 ユーザー、グループはカンマ区切りで 複数入力
32.
© Cloudera, Inc.
All rights reserved. キュー配置ポリシー
33.
33 © Cloudera,
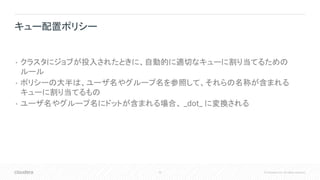
Inc. All rights reserved. • クラスタにジョブが投入されたときに、自動的に適切なキューに割り当てるための ルール • ポリシーの大半は、ユーザ名やグループ名を参照して、それらの名称が含まれる キューに割り当てるもの • ユーザ名やグループ名にドットが含まれる場合、 _dot_ に変換される キュー配置ポリシー
34.
34 © Cloudera,
Inc. All rights reserved. キュー配置ポリシーの一覧 (Cloudera Manager) ポリシー名 説明 デフォルト設定における優先順位 root.[キュー名] root.[キュー名]を割り当てる。 -- root.[キュー名].[ユーザ名] root.[キュー名].[ユーザ名] を割り当てる。root.[キュー名]が存在しない場合は無条件 で無視される。 2番目。root.users.[ユーザ名]という キュー名で指定。 root.[プライマリグループ名] root.[プライマリグループ名]を割り当てる。 -- root.[プライマリグループ名].[ユーザ名] root.[プライマリグループ名].[ユーザ名] を割り当てる。root.[プライマリグループ名]が 存在しない場合は無条件で無視される。 -- root.[セカンダリグループ名] root.[セカンダリグループ名]を割り当てる。セカンダリグループが複数ある場合、先頭 から順に判定する。 -- root.[セカンダリグループ名].[ユーザ名] root.[セカンダリグループ名] .[ユーザ名]を割り当てる。セカンダリグループが複数ある 場合、先頭から順に判定する。 -- root.[ユーザ名] root.[ユーザ名]を割り当てる。ユーザ名にドットが含まれる場合は _dot_ に変換され る。 -- 実行時に指定 実行時にキューを割り当てる。実行時に指定していない場合は無視される。 1番目 default root.defaultキューを割り当てる。このポリシーは、設定した場合無条件で適用される。 3番目 reject ジョブの投入を拒否する。このポリシーは明示的に指定できない。他のポリシーの条 件を全て満たさなかった場合、無条件で適用される。 --
35.
35 © Cloudera,
Inc. All rights reserved. • 「プールが存在しない場合に作成しま す。」というポリシーを指定可能 • 文字通り、存在しないキュー(プール)を 自動作成する • 新規参加ユーザ・グループの多い組織 で有効 キューの自動作成
36.
© Cloudera, Inc.
All rights reserved. プリエンプション
37.
37 © Cloudera,
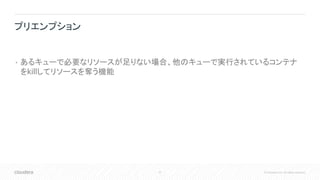
Inc. All rights reserved. • あるキューで必要なリソースが足りない場合、他のキューで実行されているコンテナ をkillしてリソースを奪う機能 プリエンプション
38.
38 © Cloudera,
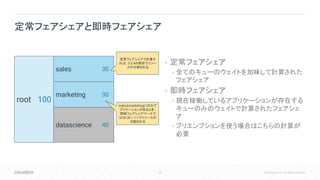
Inc. All rights reserved. • 定常フェアシェア • 全てのキューのウェイトを加味して計算された フェアシェア • 即時フェアシェア • 現在稼働しているアプリケーションが存在する キューのみのウェイトで計算されたフェアシェ ア • プリエンプションを使う場合はこちらの計算が 必要 定常フェアシェアと即時フェアシェア root sales marketing datascience 100 30 30 40 定常フェアシェアで計算す れば、3:3:4の割合でリソー スが分割される salesとmarketingにのみア プリケーションがあるとき、 即時フェアシェアベースで は30:30 = 1:1でリソースが 分配される
39.
39 © Cloudera,
Inc. All rights reserved. • スタベーション • リソースが枯渇している状態。スタベーション しているキューあるいはアプリがあるとプリエ ンプションが実行される • 二種類のスタベーション • フェアシェアスタベーション • 最小シェアスタベーション プリエンプションの流れとスタベーション(枯渇) 条件を満たしたリソースキューあるいはアプリケーションが starved (枯渇) 状態となる プリエンプション対象のコンテナを検索する プリエンプションを実行して対象コンテナをkillし、starved ア プリケーションにリソースを割り当てる
40.
40 © Cloudera,
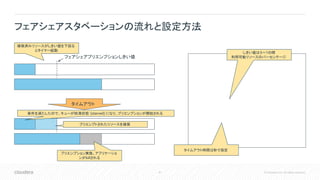
Inc. All rights reserved. • 以下の条件を満たすと、アプリケーションが 枯渇状態(starved)とみなされる • アプリケーションがリソース要求を満たしていない • アプリケーションのリソース使用量が、即時フェア シェアを下回っている • アプリケーションのリソース使用量がプリエンプ ションしきい値を下回っている状態が、プリエンプ ションタイムアウトよりも長い時間継続する • プリエンプションしきい値のデフォルトは0.5 • 即時フェアシェアで割り当てられるべきリソースの 50% • プリエンプションタイムアウトはデフォルトで 未設定 • アプリケーション単位で明示的にタイムアウトを設 定しない限り、デフォルトではプリエンプションは 発生しない • アプリケーション単位でフェアシェアスタ ベーションが発生することがある フェアシェアスタベーション
41.
41 © Cloudera,
Inc. All rights reserved. フェアシェアスタベーションの流れと設定方法 フェアシェアプリエンプションしきい値 タイムアウト プリエンプション実施。アプリケーショ ンがkillされる 確保済みリソースがしきい値を下回る とタイマー起動 条件を満たしたので、キューが枯渇状態 (starved) になり、プリエンプションが開始される タイムアウト時間は秒で指定 しきい値は0〜1の間 利用可能リソースのパーセンテージ プリエンプトされたリソースを確保
42.
42 © Cloudera,
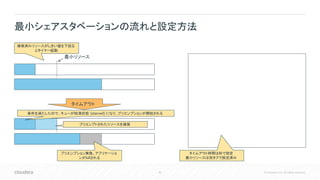
Inc. All rights reserved. • 以下の条件を満たすと、アプリケーションが 枯渇状態(starved)とみなされる • アプリケーションがリソース要求を満たしていない • アプリケーションのリソース使用量が、最小リソー スを下回っている • アプリケーションのリソース使用量が最小リソース を下回っている状態が、最小共有プリエンプショ ンタイムアウトよりも長い時間継続する • 最小リソースのデフォルトは未設定 • プリエンプションタイムアウトはデフォルトで未 設定 • 最小リソースとタイムアウトを設定しない限り、 デフォルトではプリエンプションは発生しない • フェアシェアスタベーションと異なり、キュー単 位でのみスタベーションが発生 • 最小シェアスタベーションは挙動が複雑なた め、Clouderaは非推奨。フェアシェアの利用を 推奨 最小シェアスタベーション
43.
43 © Cloudera,
Inc. All rights reserved. 最小シェアスタベーションの流れと設定方法 最小リソース タイムアウト プリエンプション実施。アプリケーショ ンがkillされる 確保済みリソースがしきい値を下回る とタイマー起動 タイムアウト時間は秒で指定 最小リソースは別タブで設定済み 条件を満たしたので、キューが枯渇状態 (starved) になり、プリエンプションが開始される プリエンプトされたリソースを確保
44.
44 © Cloudera,
Inc. All rights reserved. • 一番リソースが不足しているキューから 優先的に割り当てていく • 一度優先順位を決定したら、そのキュー の不足が解決するまで、可能な限りリ ソースを投入する • よって、わずかなリソースの投入で充足 可能なキューが、最後までリソース不足 のままとなる 最小シェアスタベーション発生時のリソース割当て優先順位 最小リソース 最小リソース 最小リソース 一番リソースが不足していたため、最 優先でリソースが割当てられる 一番リソースが不足していなかったの で、割当が後回しにされる
45.
45 © Cloudera,
Inc. All rights reserved. • 枯渇状態のアプリケーションやキューが存 在するとき、以下の条件のコンテナを選択 してkillする • プリエンプションが許可されたキューのアプリケー ションのコンテナ • そのコンテナをkillしても、フェアシェアを下回るこ とがない • アプリケーションマスターは、他にkillできる コンテナがない場合のみプリエンプト対象と なる プリエンプションの対象選択 フェアシェア フェアシェア フェアシェア コンテナkill preemptible = false フェアシェアを超えた分はプリ エンプト対象 プリエンプションが不許可のた めkillされない フェアシェアを下回っているた めkillされない A A A C C C C C C アプリケーションマスターよりコ ンテナが先にkillされる
46.
© Cloudera, Inc.
All rights reserved. ケーススタディ
47.
47 © Cloudera,
Inc. All rights reserved. 要件 • 優先度の高いキューと、ベストエフォー トで実行するキューの2つを持ちたい 解決策 • 加重(ウェイト)を0.0に設定する ベストエフォート high best_effort (設定なし) 0 high best_effort 可能な限りリソースを 確保したい 空いているときだけ使 いたい
48.
48 © Cloudera,
Inc. All rights reserved. ベストエフォート: ケーススタディ 時間 イベント 12:00 best_effortキューにジョブB1を投入。必要リソースは100% 12:01 highキューにジョブH1を投入。必要リソースは30% 12:02 B1、完了 highキューにジョブH2を投入。必要リソースは70% best_effortキューにジョブB2を投入。必要リソースは30% 12:03 12:04 H1、完了 12:05 H2、完了 以下のようなシナリオを考える
49.
49 © Cloudera,
Inc. All rights reserved. ベストエフォート: リソース使用量推移 割当されない 割当開始 highにジョブを投入しても、プリエンプション の設定がないため、 best_effortからはリ ソースを奪わない best_effortに新規にジョブを投 入しても、highのジョブへの割 当が優先される リソースが余り始めたら、 best_effortへのリソース割り当 てが始まる ジョブB1投入 ジョブH1投入 ジョブB2投入 ジョブH2投入
50.
50 © Cloudera,
Inc. All rights reserved. 要件 • 優先度の高いキュー用に、20%のリソー スを予約しておきたい 解決策 • 通常キュー側のリソース上限を80%に 制限する • リソース上限はハードリミットなので、結 果的に優先キュー側の20%を予約可能 リソースの予約 high normal (設定なし) リソース上限80% high normal いつでも20%使えるよ うにしておきたい 残り80%は自由に使 いたい
51.
51 © Cloudera,
Inc. All rights reserved. リソースの予約: ケーススタディ 時間 イベント 12:00 normalキューにジョブN1を投入。必要リソースは100% 12:01 highキューにジョブH1を投入。必要リソースは20% 12:02 H1、完了 normalキューN1の残りタスクに必要な20%を投入 12:03 N1、完了 highキューにジョブH2を投入。必要リソースは100% 12:04 normalキューにジョブN2を投入。必要リソースは80% 12:05 H2、完了 以下のようなシナリオを考える
52.
52 © Cloudera,
Inc. All rights reserved. リソースの予約: リソース使用量推移 割当されない 割当開始 ハードリミットのため、80%以上の リソースは使わない リソースが余り始めたら、normalへ のリソース割り当てが始まるジョブN1投入 ジョブH1投入 ジョブN2投入 ジョブH2投入 20%は予約されているので、すぐ にリソース割り当て可能 N1に必要なリソース残り 20%を割り当て プリエンプションの設定がないため、 highからはリソースを奪わない
53.
53 © Cloudera,
Inc. All rights reserved. 要件 • 優先度の低いジョブに割り込んで、優先 度の高いジョブを実行したい 解決策 • フェアシェアプリエンプションを使う • しきい値100%、タイムアウト1秒に設定すれば、 不足したらすぐにプリエンプションが発生 優先ジョブの割り込み high normal ウェイト75% プリエンプションしきい値 100% プリエンプションタイムアウト 1秒 ウェイト25% high normal 必要があれば他のジョブ に割り込みたい 余っていたら自由に使い たい
54.
54 © Cloudera,
Inc. All rights reserved. 優先ジョブの割り込み: ケーススタディ 時間 イベント 12:00 normalキューにジョブN1を投入。必要リソースは100% 12:01 highキューにジョブH1を投入。必要リソースは25%。 12:02 プリエンプション発生。N1のジョブのリソースのうち25%がkillされ、H1に割当られる。 12:03 H1、完了 N1、75%完了。ジョブのタスク残り25%を再開。 highキューにジョブH2を投入。必要リソースは75% 12:04 12:05 N1、完了 以下のようなシナリオを考える
55.
55 © Cloudera,
Inc. All rights reserved. 優先ジョブの割り込み: リソース使用量推移 コンテナkill highキューのリソースが不足している ため、プリエンプト実行。 25%のコンテナをkill 加重の設定から、75:25でリソースを共有 するようになっている よってプリエンプションは発生しない ジョブN1投入 ジョブH1投入 ジョブH2投入 リソースを他のキューか ら確保して割当 killされた処理を再開
56.
56 © Cloudera,
Inc. All rights reserved. 解決策 • 加重(ウェイト)0.0の多段設定 other mid other 0.0 low (制限設定なし) high (制限設定なし) (制限設定なし) 0.0 要件 • 優先度別の三階層のキューを作りたい 多段優先度キュー mid low highが動いてなければ処 理したい 他が動いていなければ処 理したい high最優先で処理したい
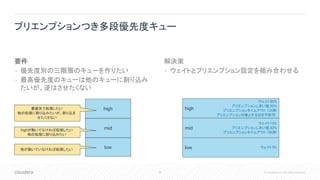
57.
57 © Cloudera,
Inc. All rights reserved. 多段優先度キュー: ケーススタディ 時間 イベント 12:00 highキューにジョブH1を投入。必要リソースは100% midキューにジョブM1を投入。必要リソースは100% lowキューにジョブL1を投入。必要リソースは100% 12:01 H1、完了。 M1にリソース割り当て 12:02 M1、完了。 L1にリソース割り当て。 highキューにジョブH2を投入。必要リソースは30% 12:03 L1、完了。 H2にリソース割り当て 12:04 H2、完了 以下のようなシナリオを考える
58.
58 © Cloudera,
Inc. All rights reserved. 多段優先度キュー: リソース使用量推移 ジョブH1、M1、 L1投入 ジョブH2投入 H1にのみリソース が割当られる highキューが空に なったらmidキューに 割当られる highにジョブを投入しても、プリエンプション の設定がないため、 lowからはリソースを 奪わない highとmidキューが空になったらlow キューに割当られる
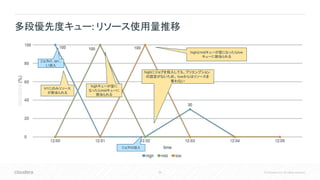
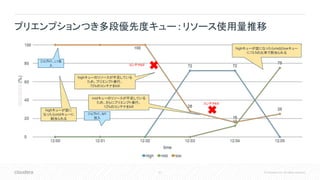
59.
59 © Cloudera,
Inc. All rights reserved. 解決策 • ウェイトとプリエンプション設定を組み合わせる 要件 • 優先度別の三階層のキューを作りたい • 最高優先度のキューは他のキューに割り込み たいが、逆はさせたくない プリエンプションつき多段優先度キュー mid low highが動いてなければ処理したい 他の処理に割り込みたい 他が動いていなければ処理したい high最優先で処理したい 他の処理に割り込みたいが、割り込ま せたくはない high ウェイト80% プリエンプションしきい値 90% プリエンプションタイムアウト 120秒 プリエンプション対象とするのを不許可 mid ウェイト15% プリエンプションしきい値 80% プリエンプションタイムアウト 180秒 low ウェイト5%
60.
60 © Cloudera,
Inc. All rights reserved. プリエンプションつき多段優先度キュー: ケーススタディ 時間 イベント 12:00 lowキューにジョブL1を投入。必要リソースは100% 12:01 highキューにジョブH1を投入。必要リソースは72% midキューにジョブM1を投入。必要リソースは100% 12:02 12:03 highキューのタイムアウト時間(120秒)が経過し、プリエンプション発生。L1のジョブのリソースのうち72%(80% * 90%)がkillされ、H1に割当られる。 12:04 midキューのタイムアウト時間(180秒)が経過し、プリエンプション発生。L1のジョブのリソースのうち12%(15% * 80%)がkillされ、M1に割当られる。 12:05 H1、完了。 highキューに割り当てられていたリソースが、mid、lowのキューに公平に配分される。 以下のようなシナリオを考える
61.
61 © Cloudera,
Inc. All rights reserved. プリエンプションつき多段優先度キュー : リソース使用量推移 ジョブH1、L1投 入 highキューが空に なったらmidキューに 割当られる highキューが空になったらmidとlowキュー に15:5の比率で割当られる ジョブH1、M1 投入 コンテナkill コンテナkill highキューのリソースが不足している ため、プリエンプト実行。 72%のコンテナをkill midキューのリソースが不足している ため、さらにプリエンプト実行。 12%のコンテナをkill
62.
© Cloudera, Inc.
All rights reserved. tips
63.
63 © Cloudera,
Inc. All rights reserved. • キューの削除を明示的に指定する方法はない • 設定の更新→リフレッシュのタイミングで削除される • プリエンプションはグローバル設定 • 全てのキューがプリエンプト対象となる • 拒否する場合は preemptable のチェックを外す • 小さいクラスタで大規模ジョブを流す場合 • 検証環境や開発環境でのシナリオ • 動作させるアプリケーション数を制限しておくこと • アプリケーションマスターがリソース確保しすぎてジョブが終わらなくなり、デッドロックになってしまう 注意点についてのtips
64.
64 © Cloudera,
Inc. All rights reserved. • Untangling Apache Hadoop YARN • Clouderaの技術ブログシリーズ。本資料はこちらの内容をベースに執筆している • http://blog.cloudera.com/blog/2015/09/untangling-apache-hadoop-yarn-part-1/ • http://blog.cloudera.com/blog/2015/10/untangling-apache-hadoop-yarn-part-2/ • http://blog.cloudera.com/blog/2016/01/untangling-apache-hadoop-yarn-part-3/ • http://blog.cloudera.com/blog/2016/06/untangling-apache-hadoop-yarn-part-4-fair-scheduler -queue-basics/ • http://blog.cloudera.com/blog/2017/02/untangling-apache-hadoop-yarn-part-5-using-fairsche duler-queue-properties/ • http://blog.cloudera.com/blog/2018/06/yarn-fairscheduler-preemption-deep-dive/ 参考リンク
Download












![34 © Cloudera, Inc. All rights reserved.
キュー配置ポリシーの一覧 (Cloudera Manager)
ポリシー名 説明 デフォルト設定における優先順位
root.[キュー名] root.[キュー名]を割り当てる。 --
root.[キュー名].[ユーザ名] root.[キュー名].[ユーザ名] を割り当てる。root.[キュー名]が存在しない場合は無条件
で無視される。
2番目。root.users.[ユーザ名]という
キュー名で指定。
root.[プライマリグループ名] root.[プライマリグループ名]を割り当てる。 --
root.[プライマリグループ名].[ユーザ名] root.[プライマリグループ名].[ユーザ名] を割り当てる。root.[プライマリグループ名]が
存在しない場合は無条件で無視される。
--
root.[セカンダリグループ名] root.[セカンダリグループ名]を割り当てる。セカンダリグループが複数ある場合、先頭
から順に判定する。
--
root.[セカンダリグループ名].[ユーザ名] root.[セカンダリグループ名] .[ユーザ名]を割り当てる。セカンダリグループが複数ある
場合、先頭から順に判定する。
--
root.[ユーザ名] root.[ユーザ名]を割り当てる。ユーザ名にドットが含まれる場合は _dot_ に変換され
る。
--
実行時に指定 実行時にキューを割り当てる。実行時に指定していない場合は無視される。 1番目
default root.defaultキューを割り当てる。このポリシーは、設定した場合無条件で適用される。 3番目
reject ジョブの投入を拒否する。このポリシーは明示的に指定できない。他のポリシーの条
件を全て満たさなかった場合、無条件で適用される。
--](https://image.slidesharecdn.com/apachehadoopyarnandresourcemanagement-180726065107/85/Apache-Hadoop-YARN-34-320.jpg)

























































![[JAWSBigData#11]Cloudera on AWSと Amazon EMRを両方本番運用し 3つの観点から比較してみる](https://cdn.slidesharecdn.com/ss_thumbnails/dljawsbigdata11clouderaonawsamazonemr3-180207013607-thumbnail.jpg?width=640&height=640&fit=bounds)





















