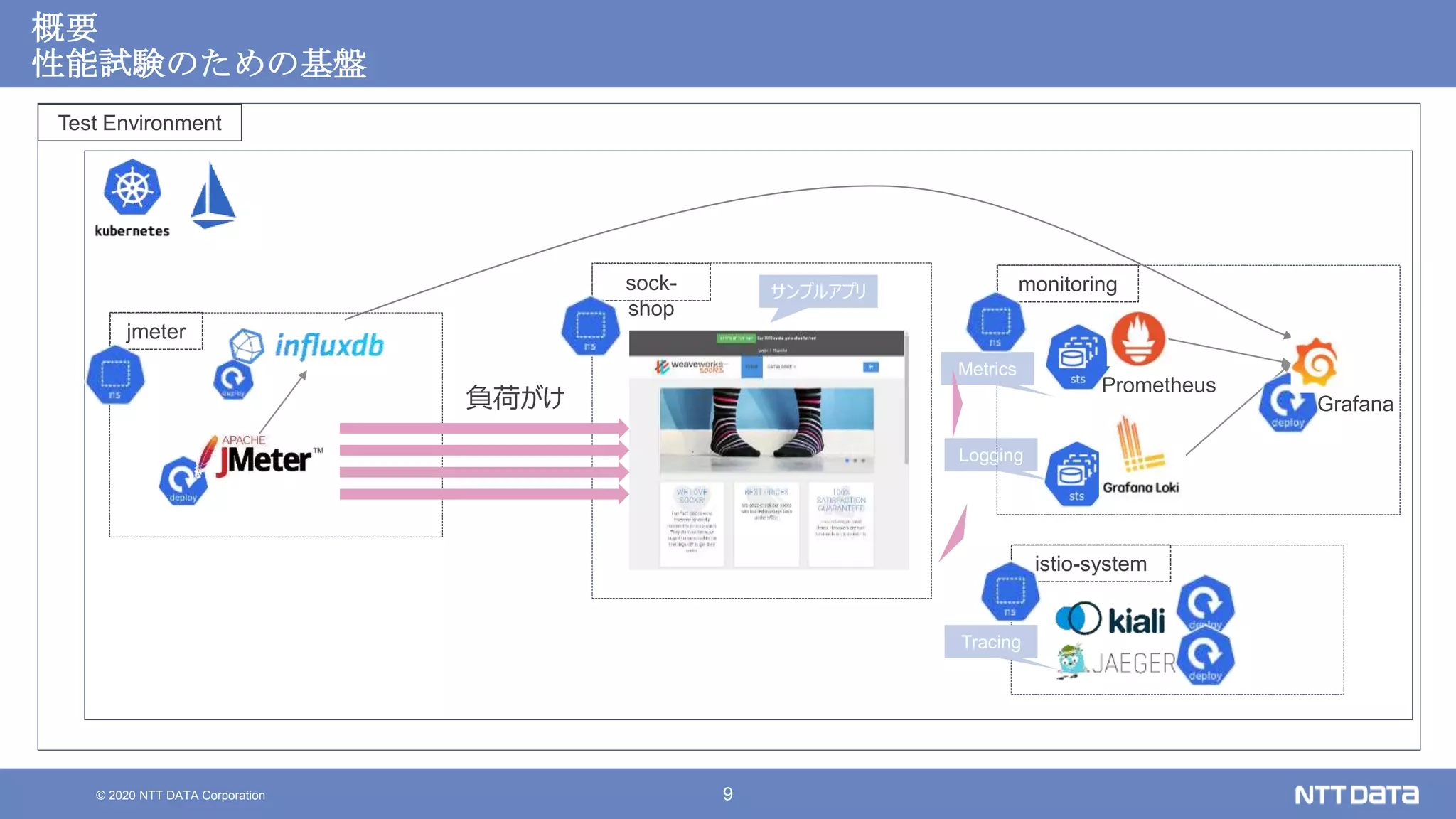
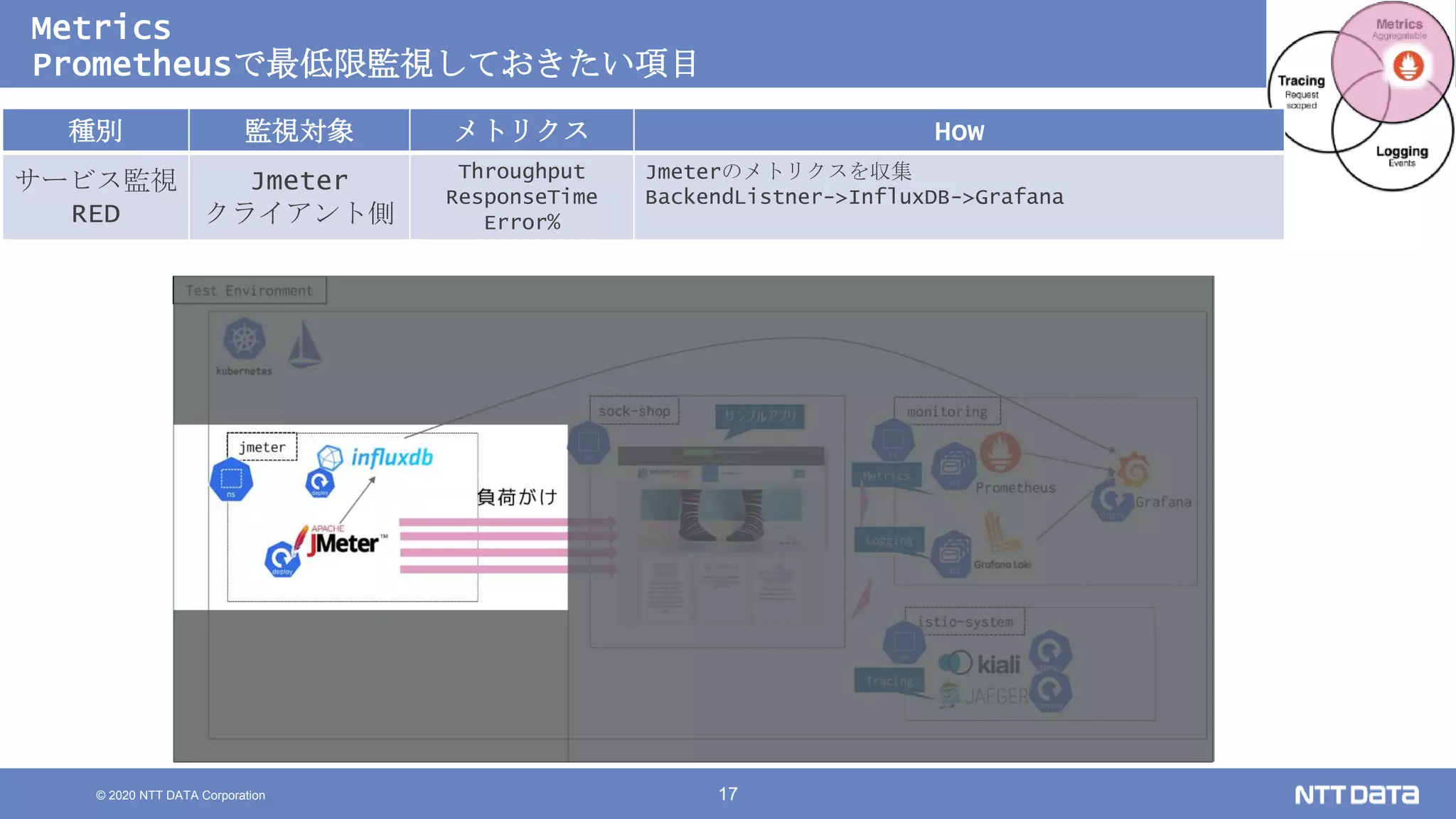
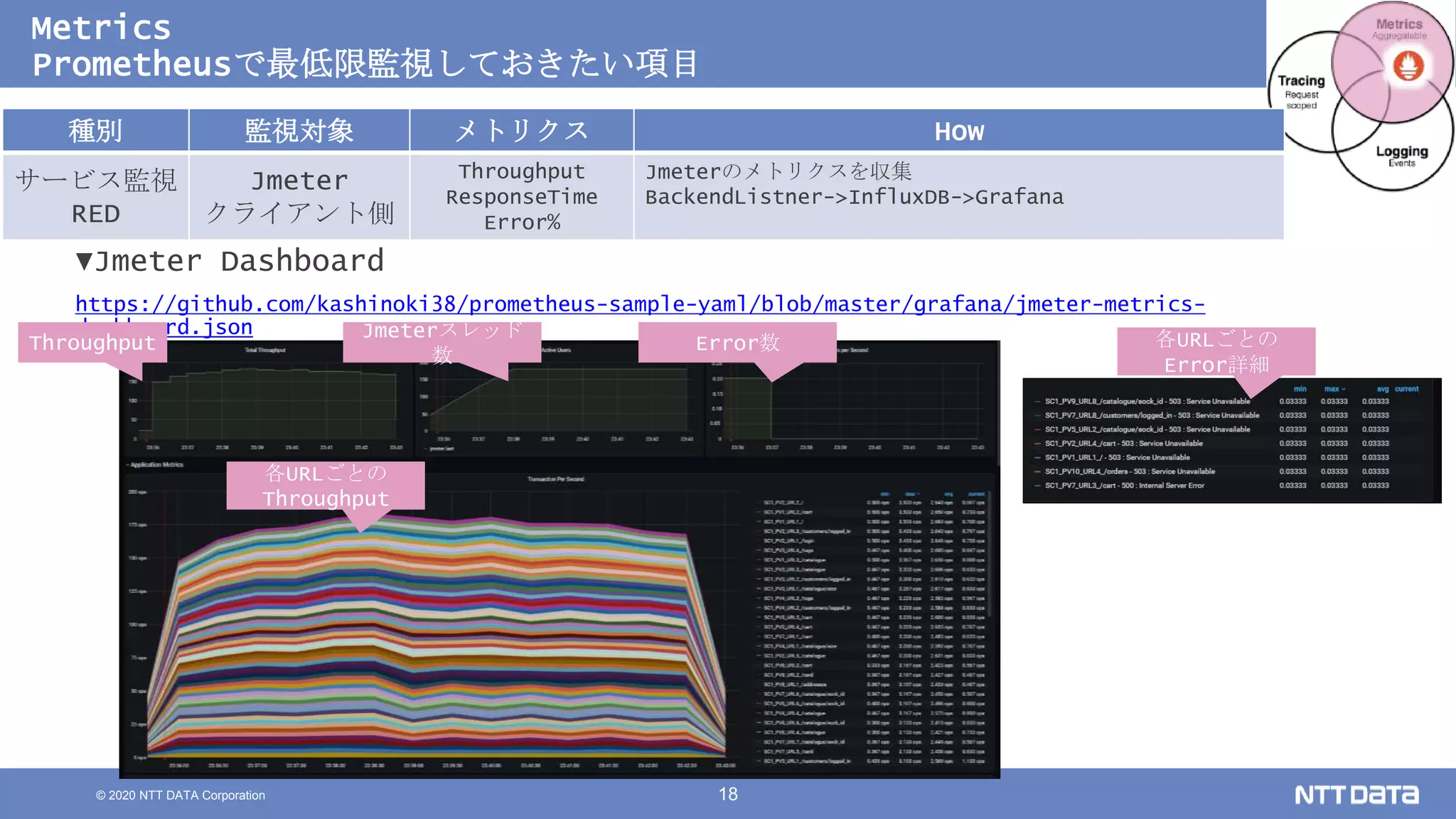
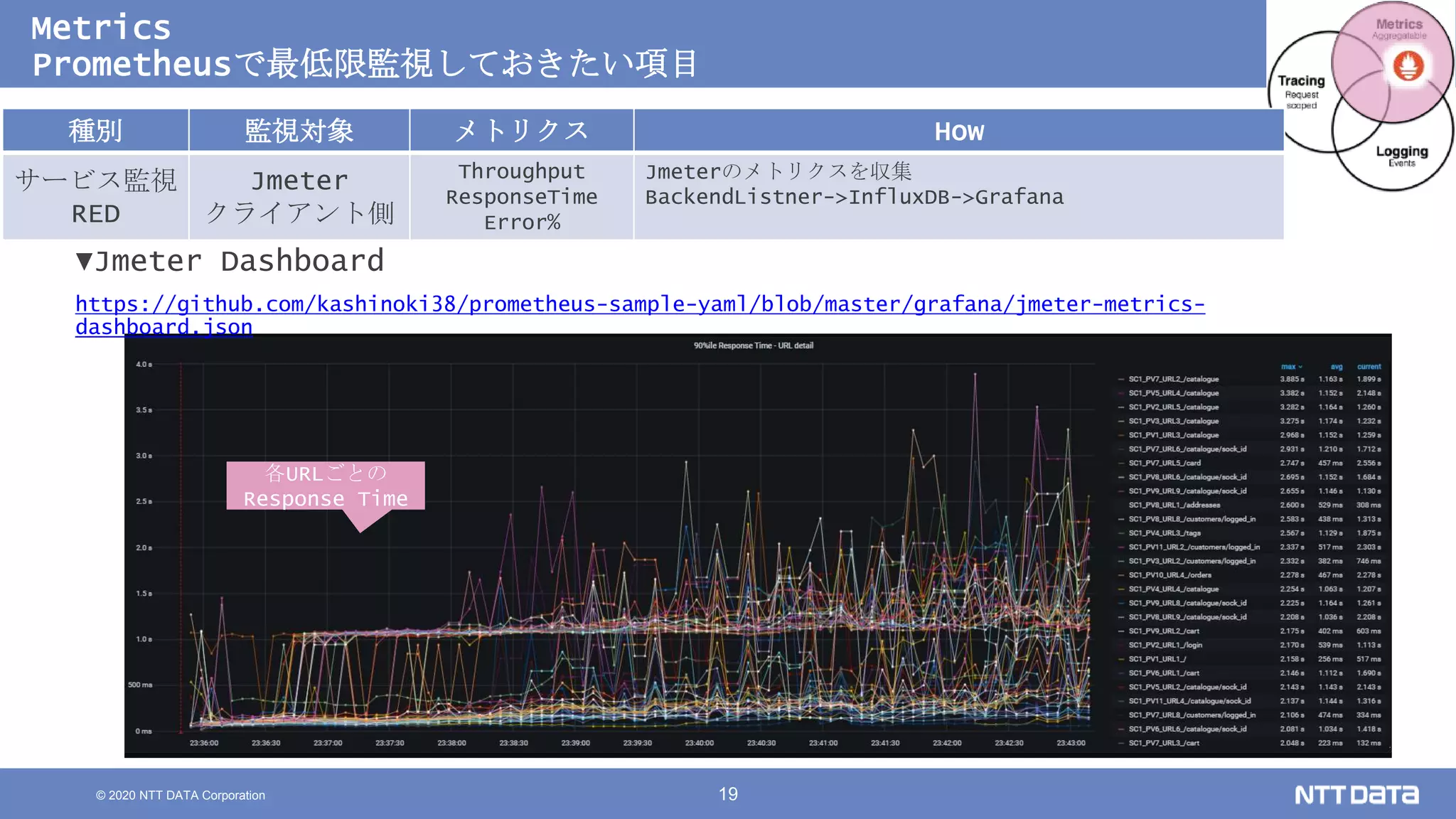
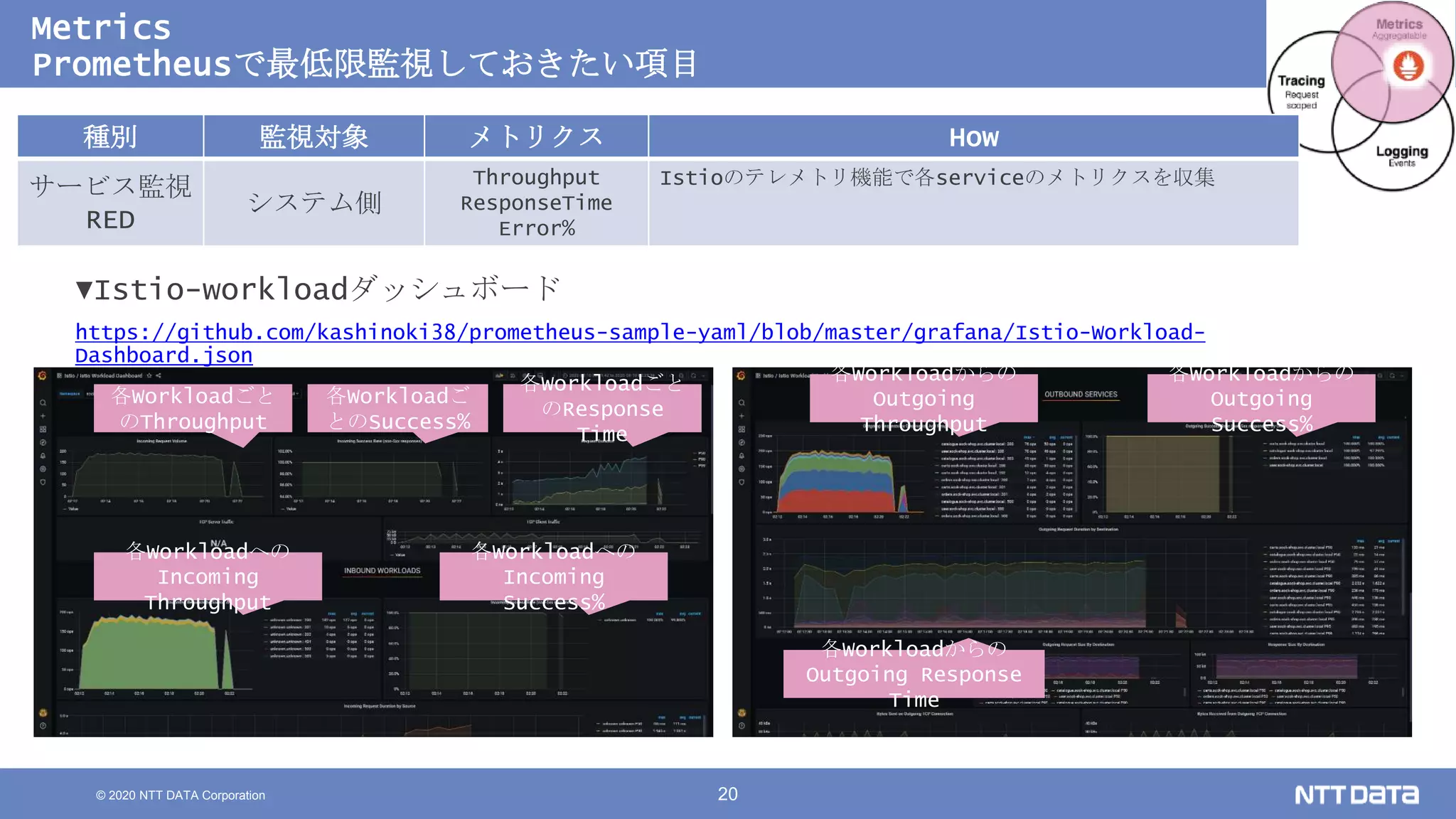
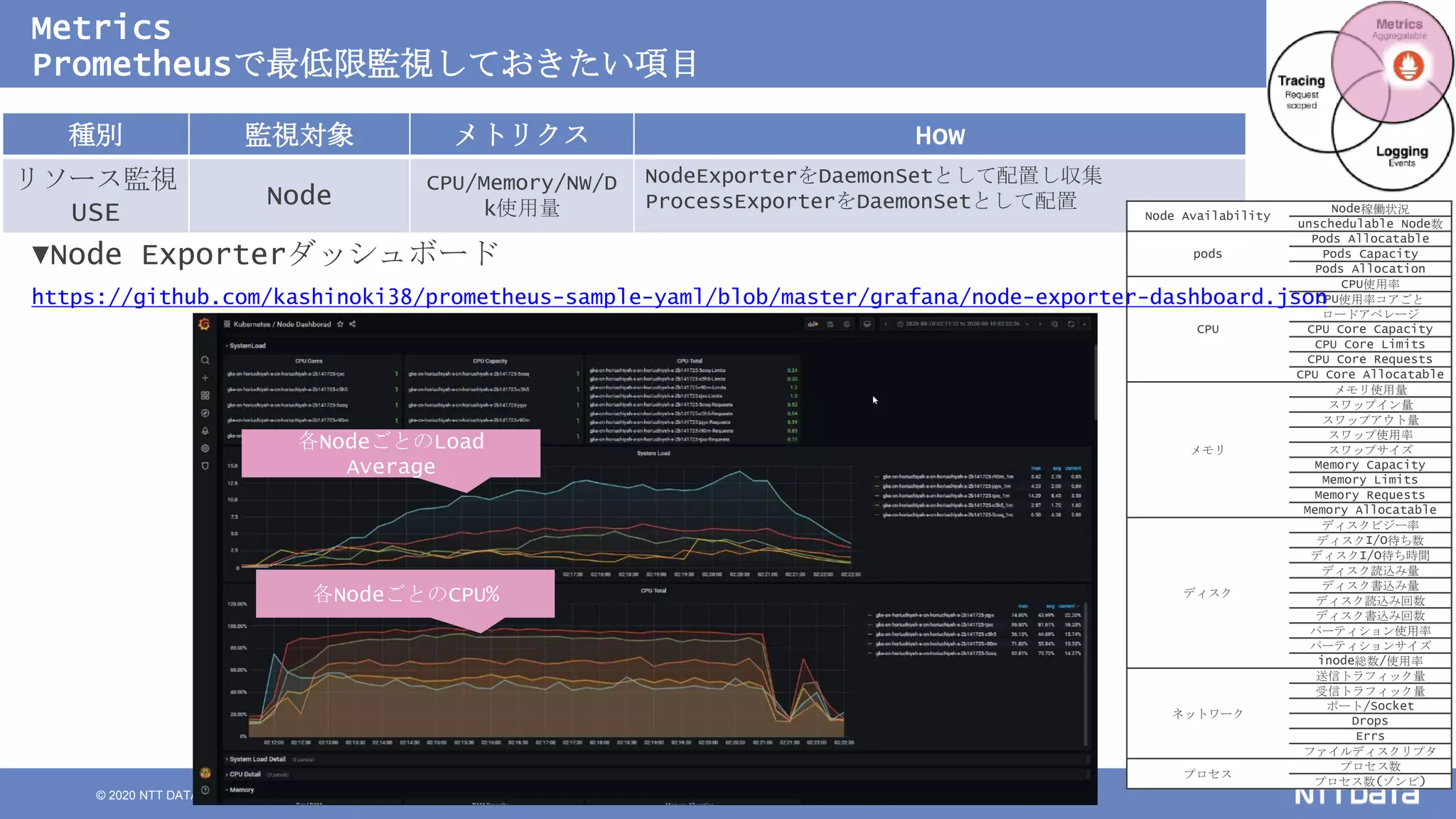
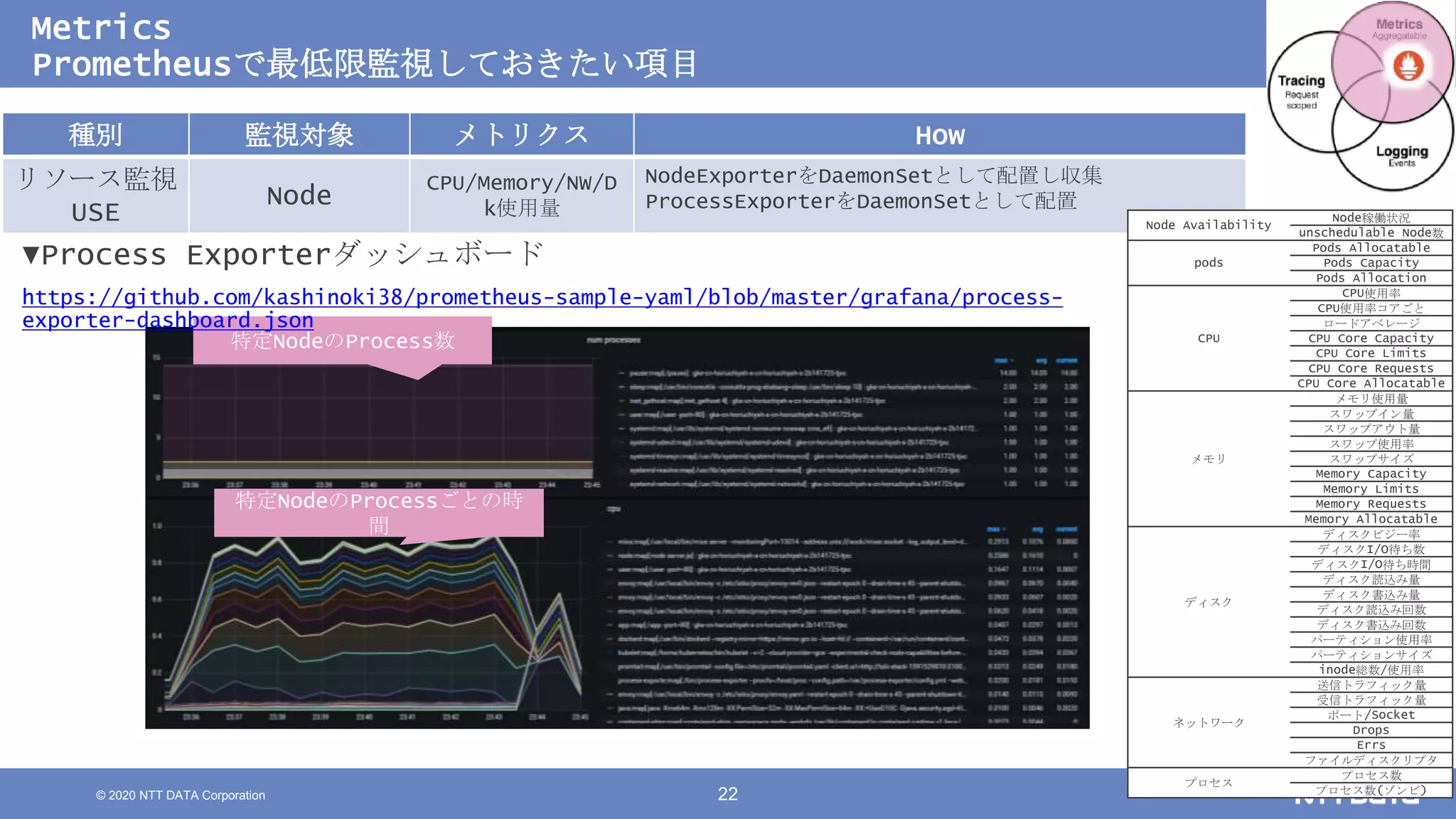
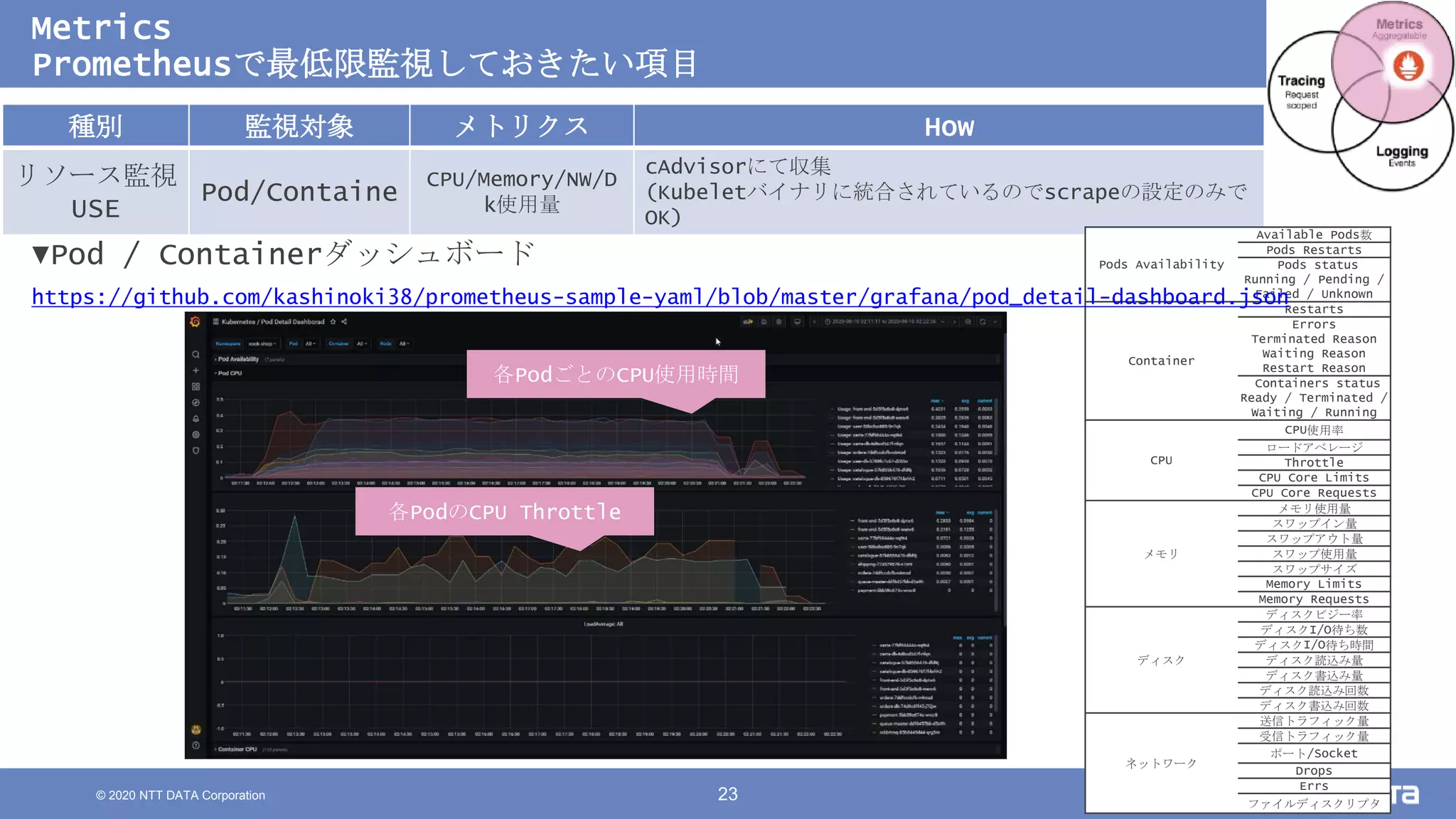
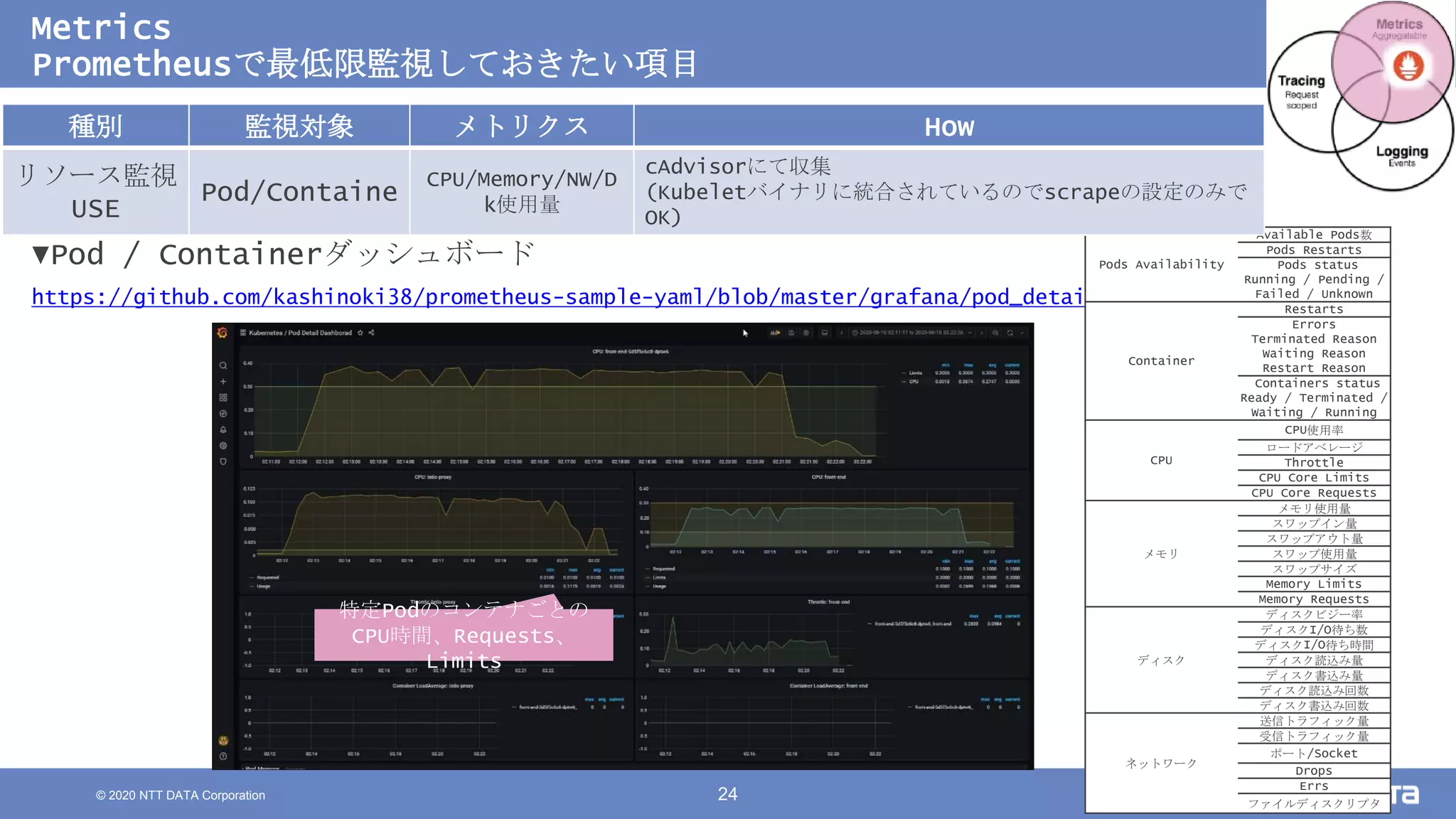
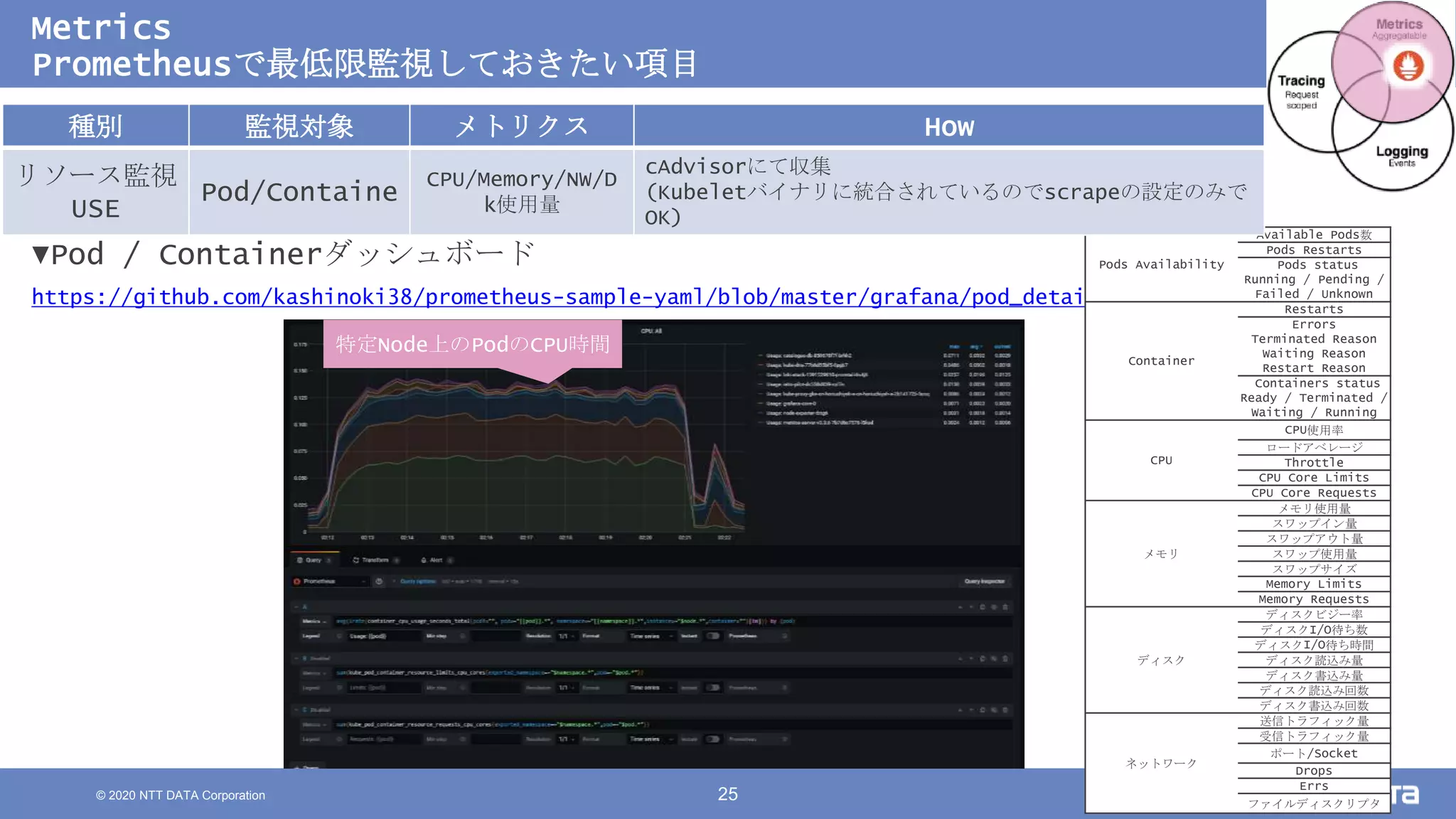
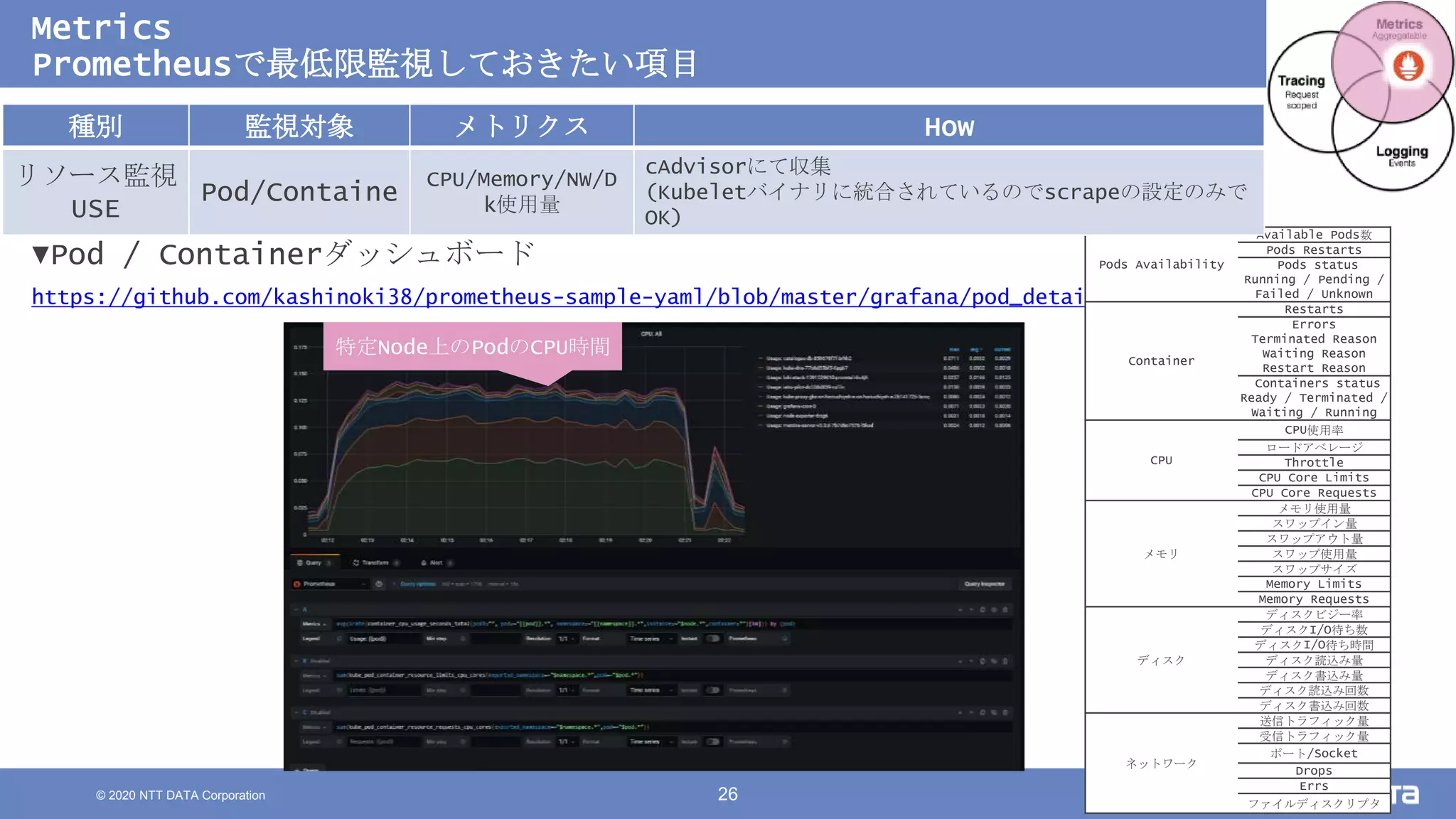
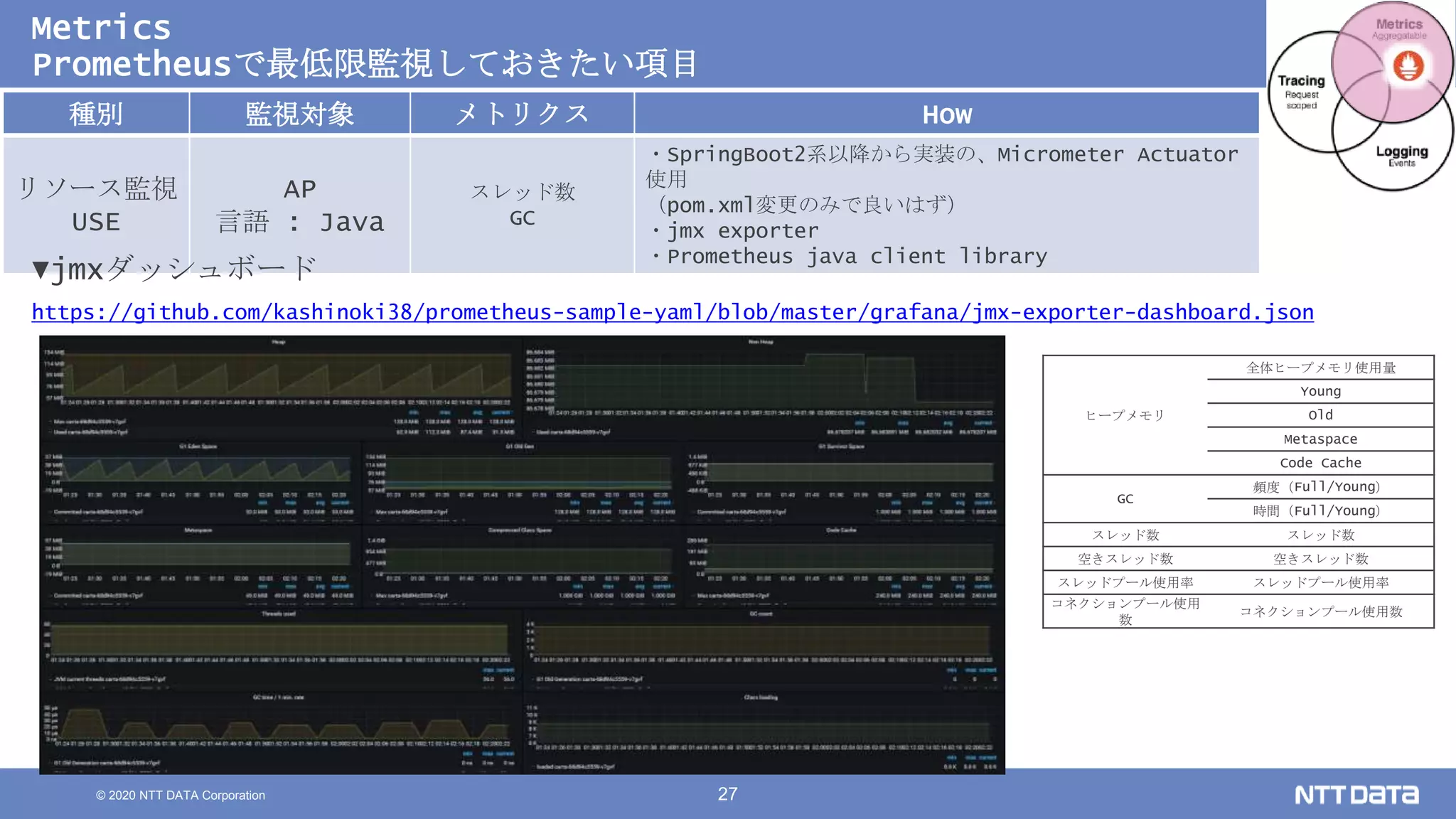
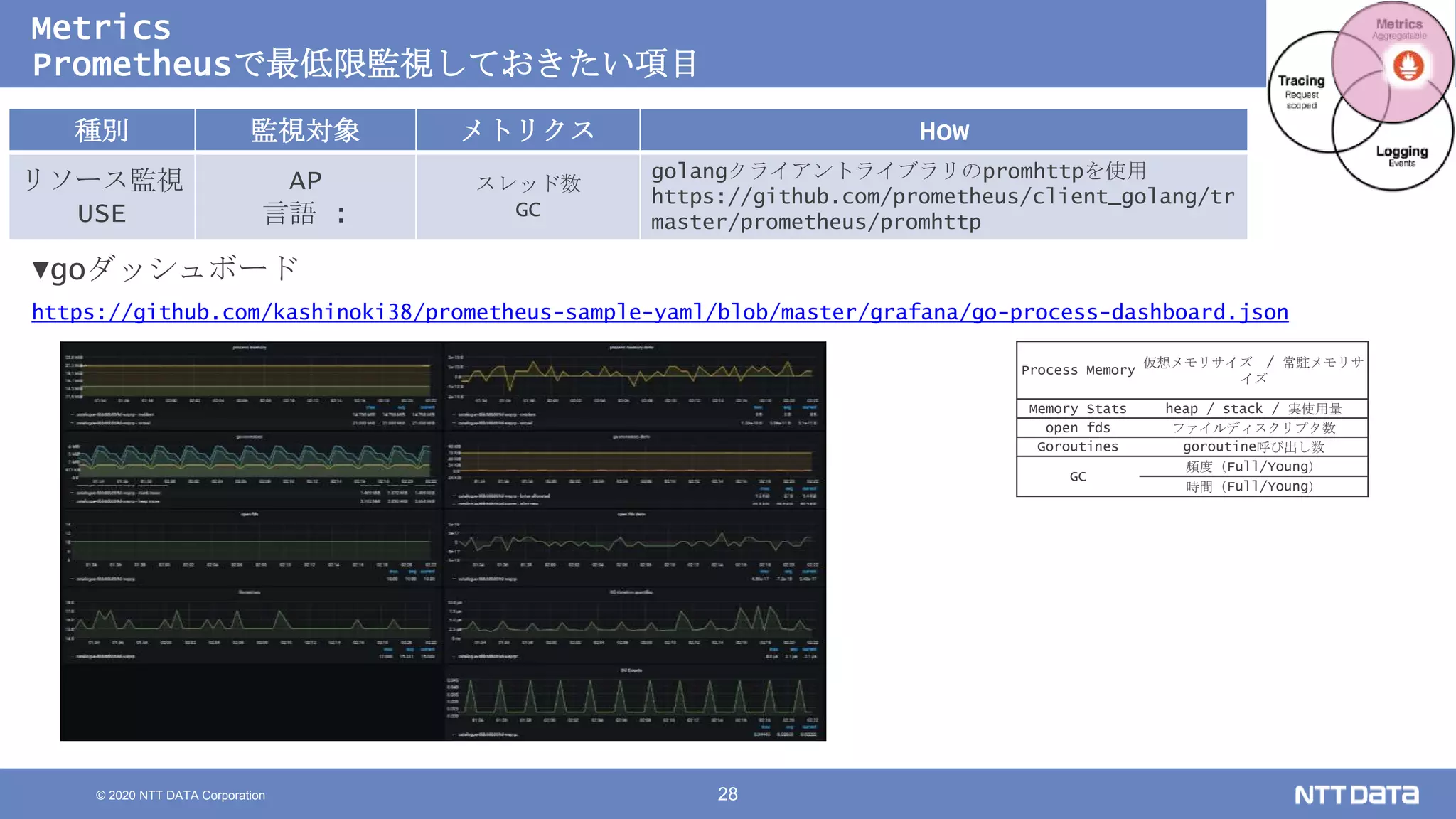
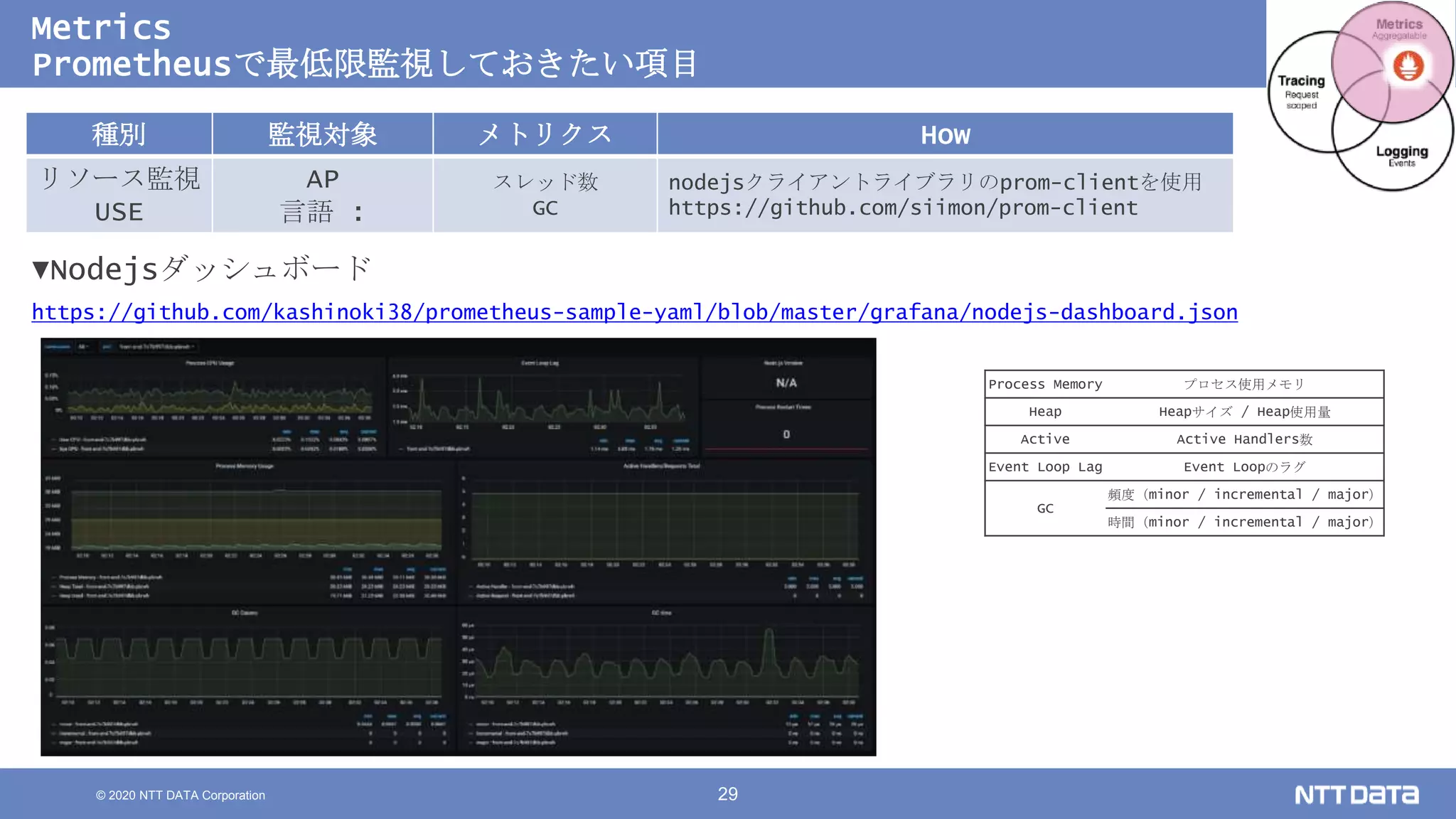
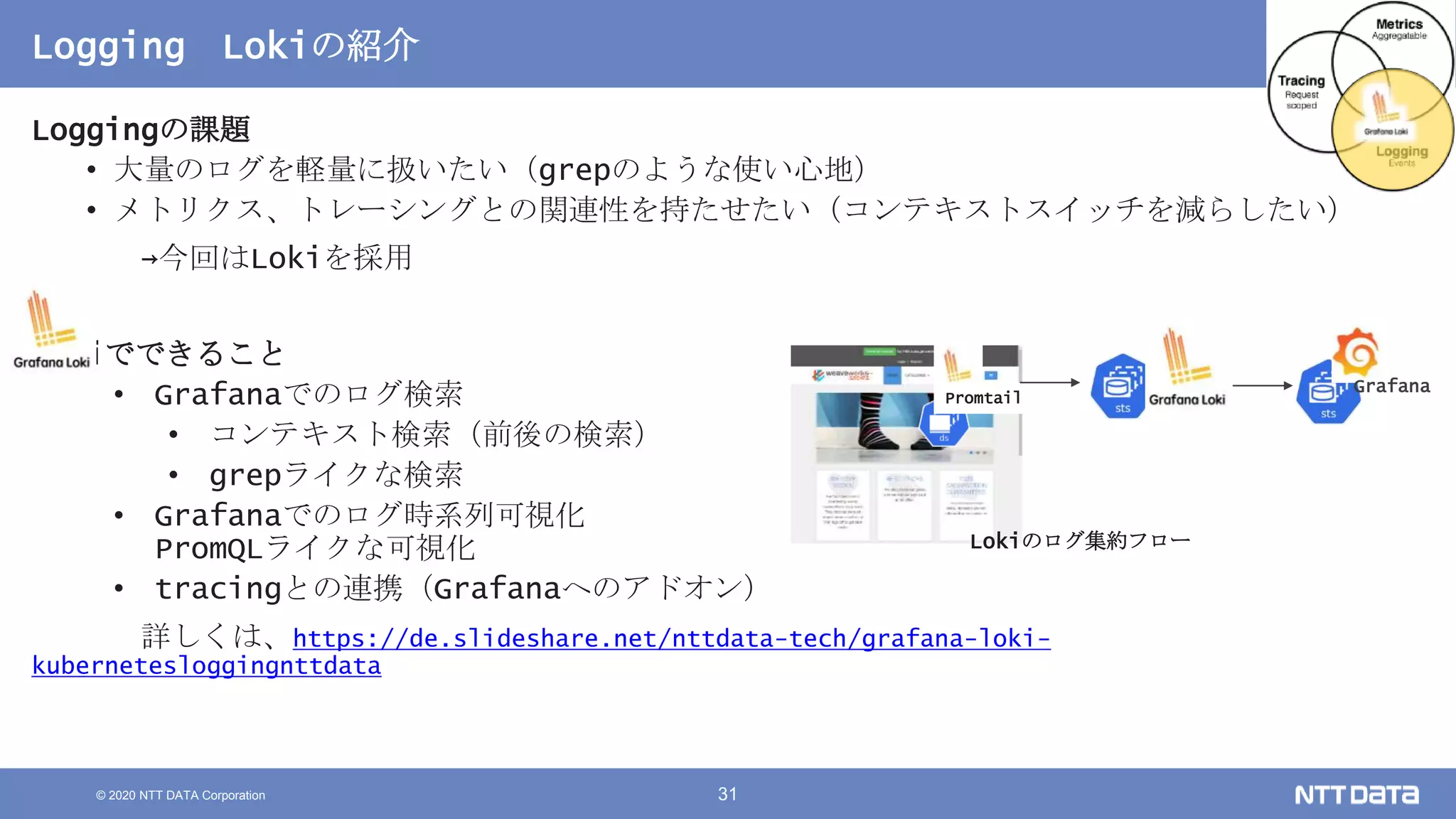
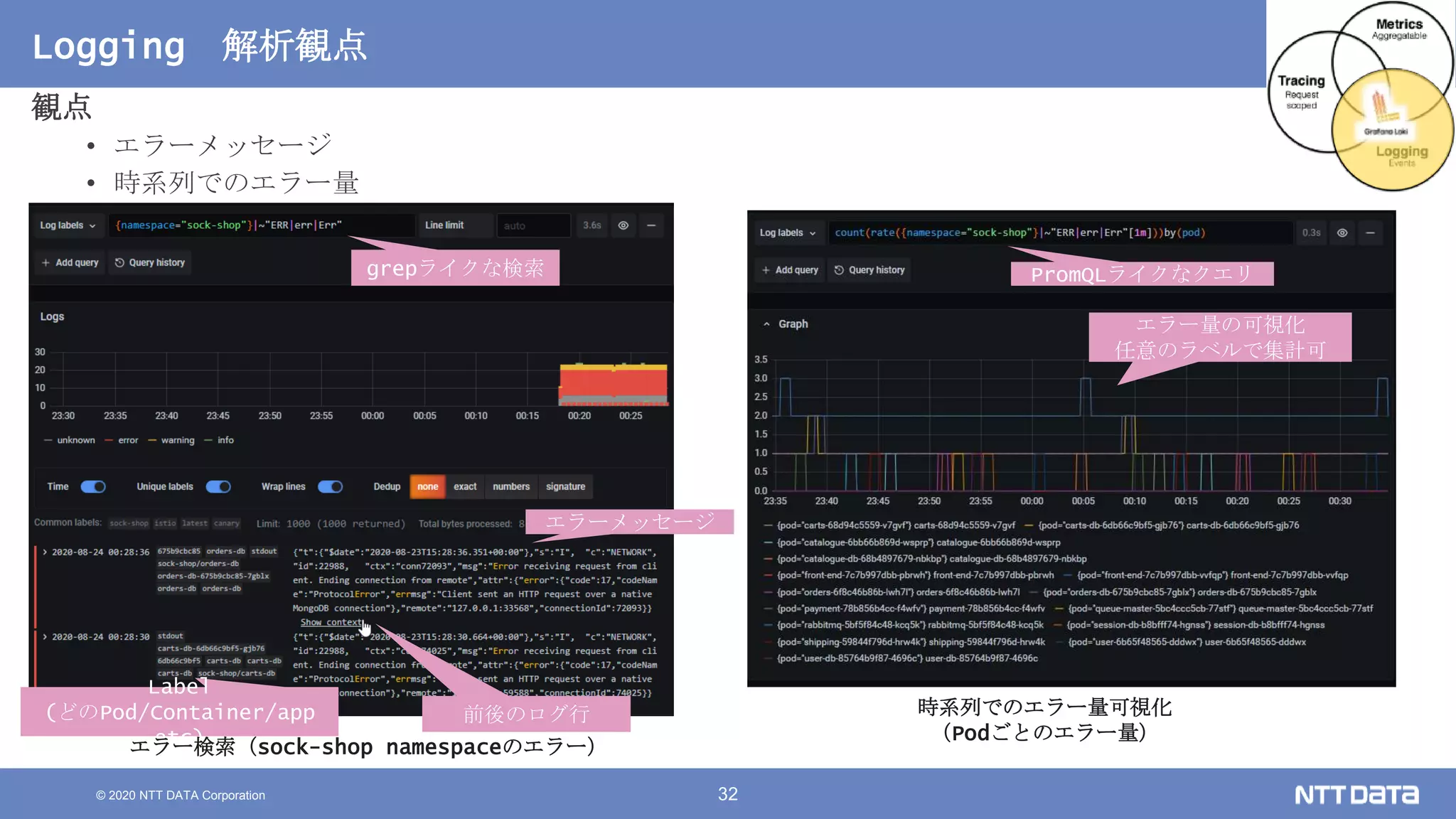
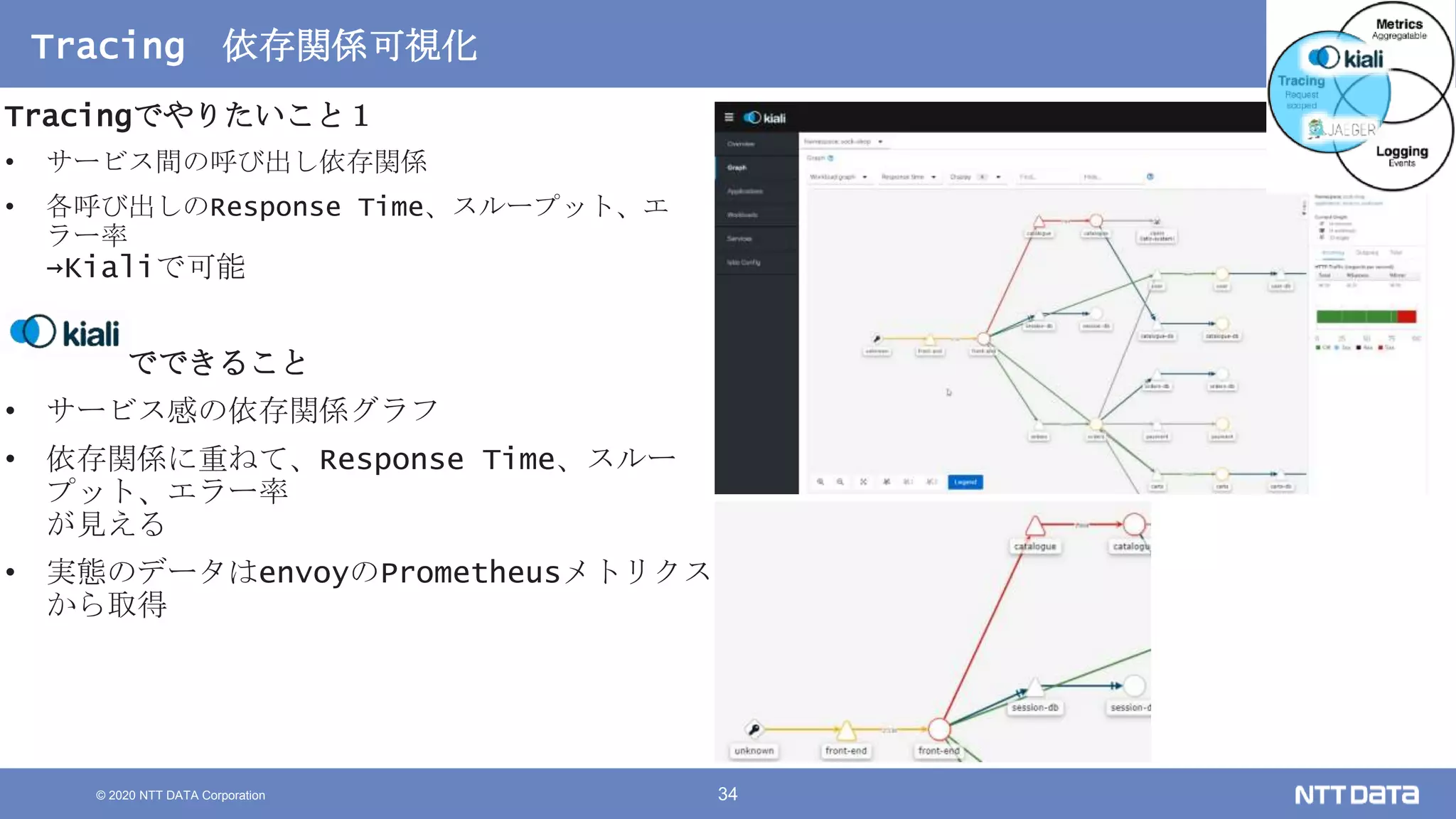
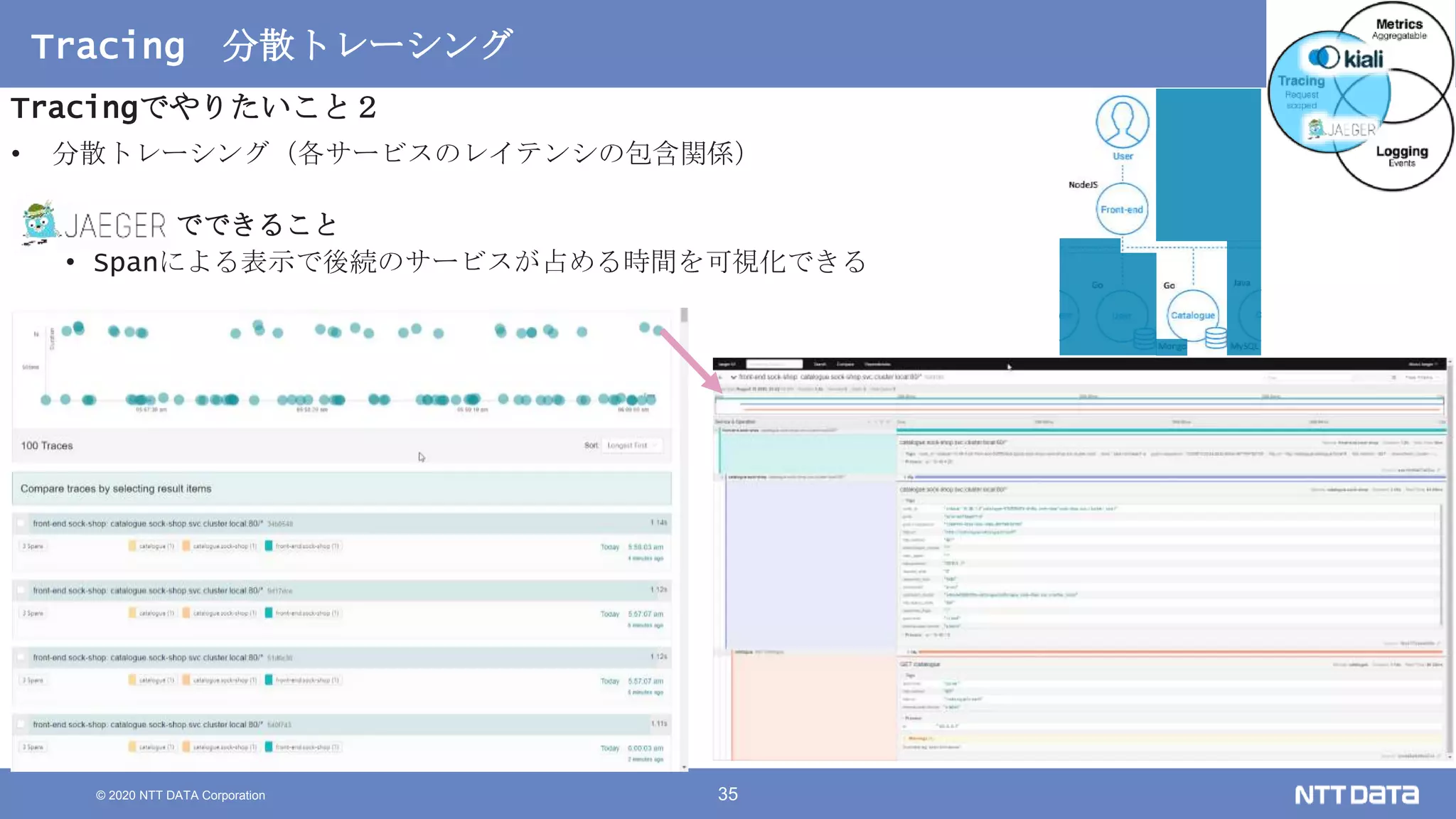
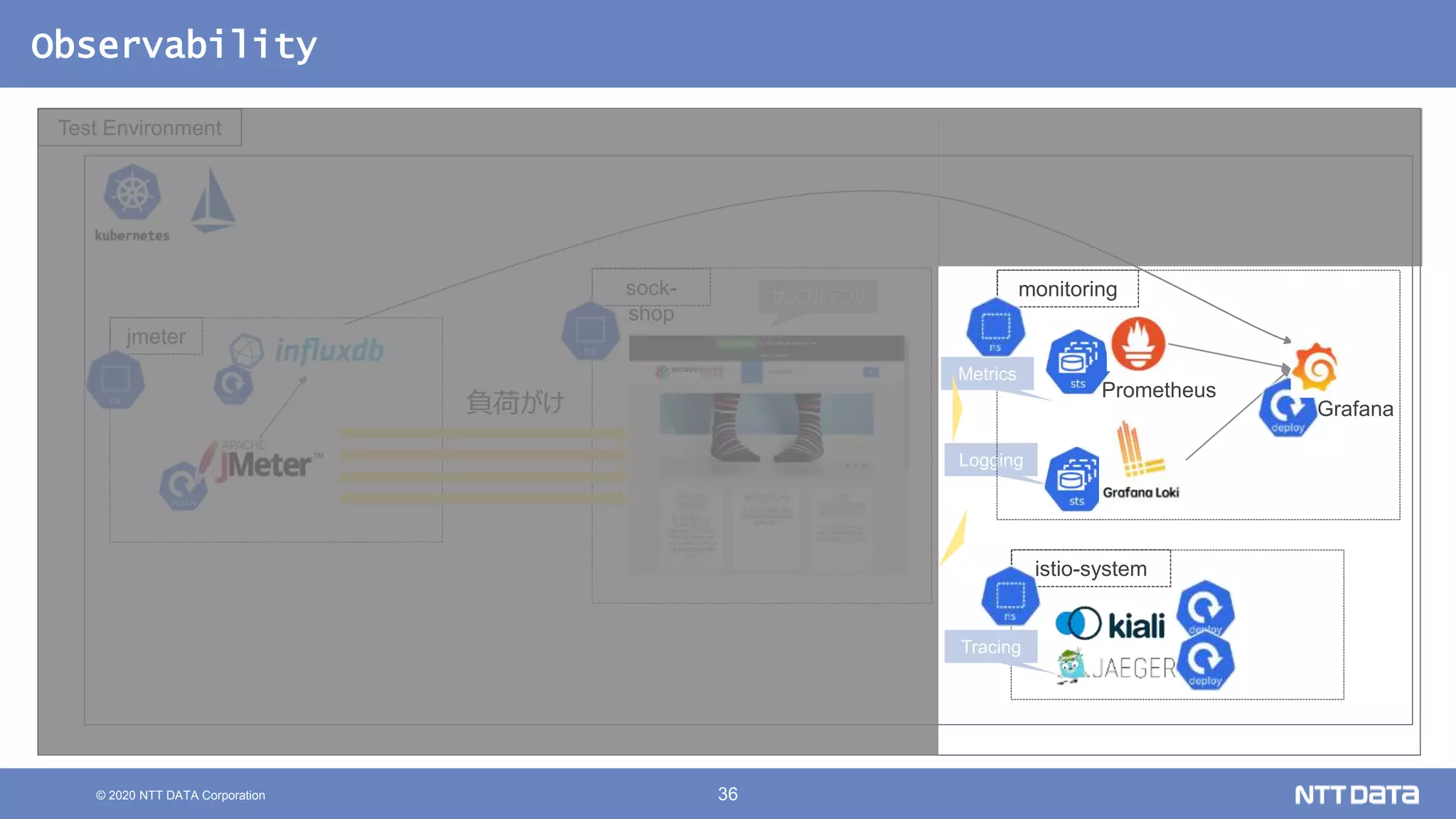
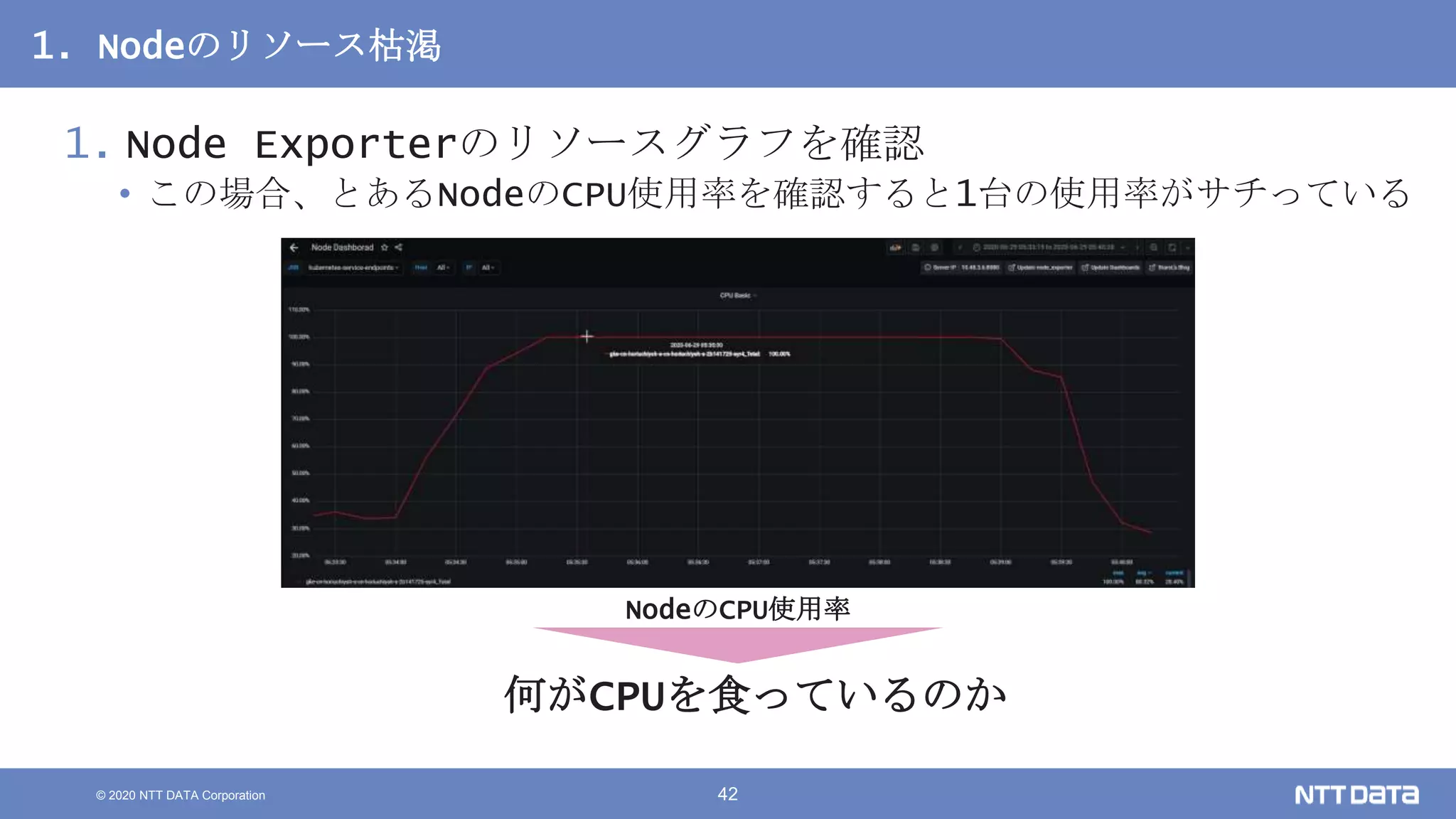
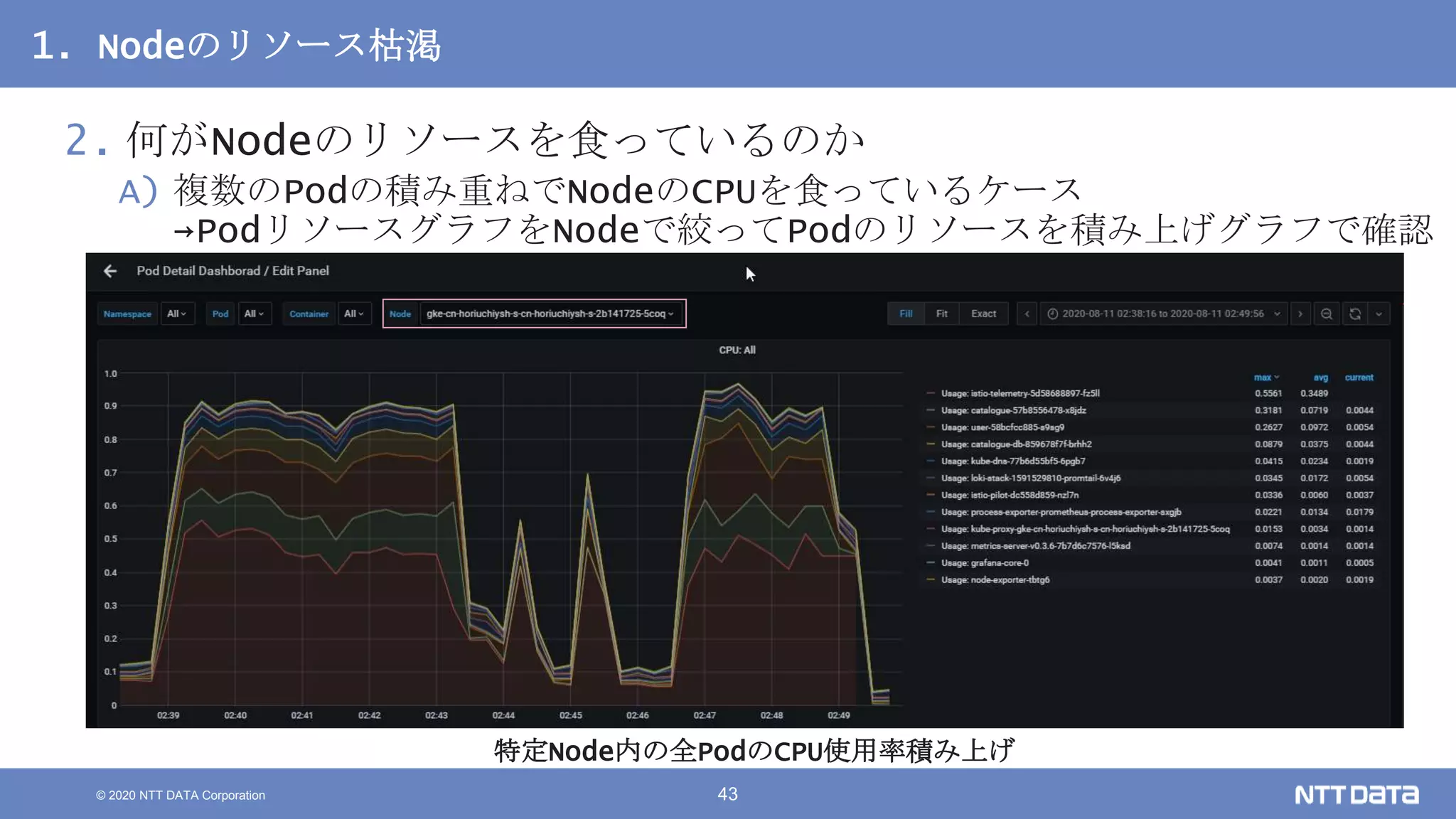
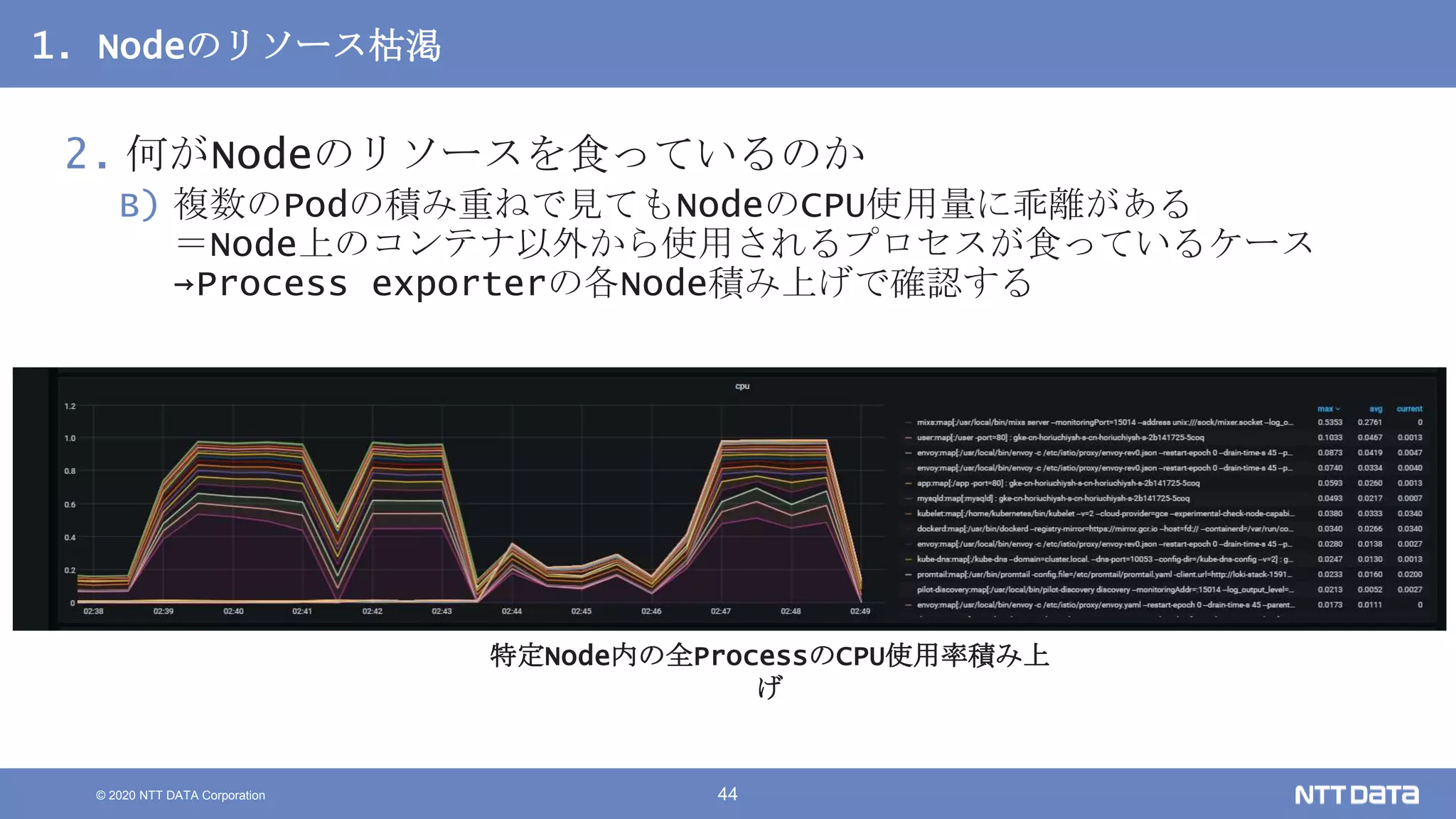
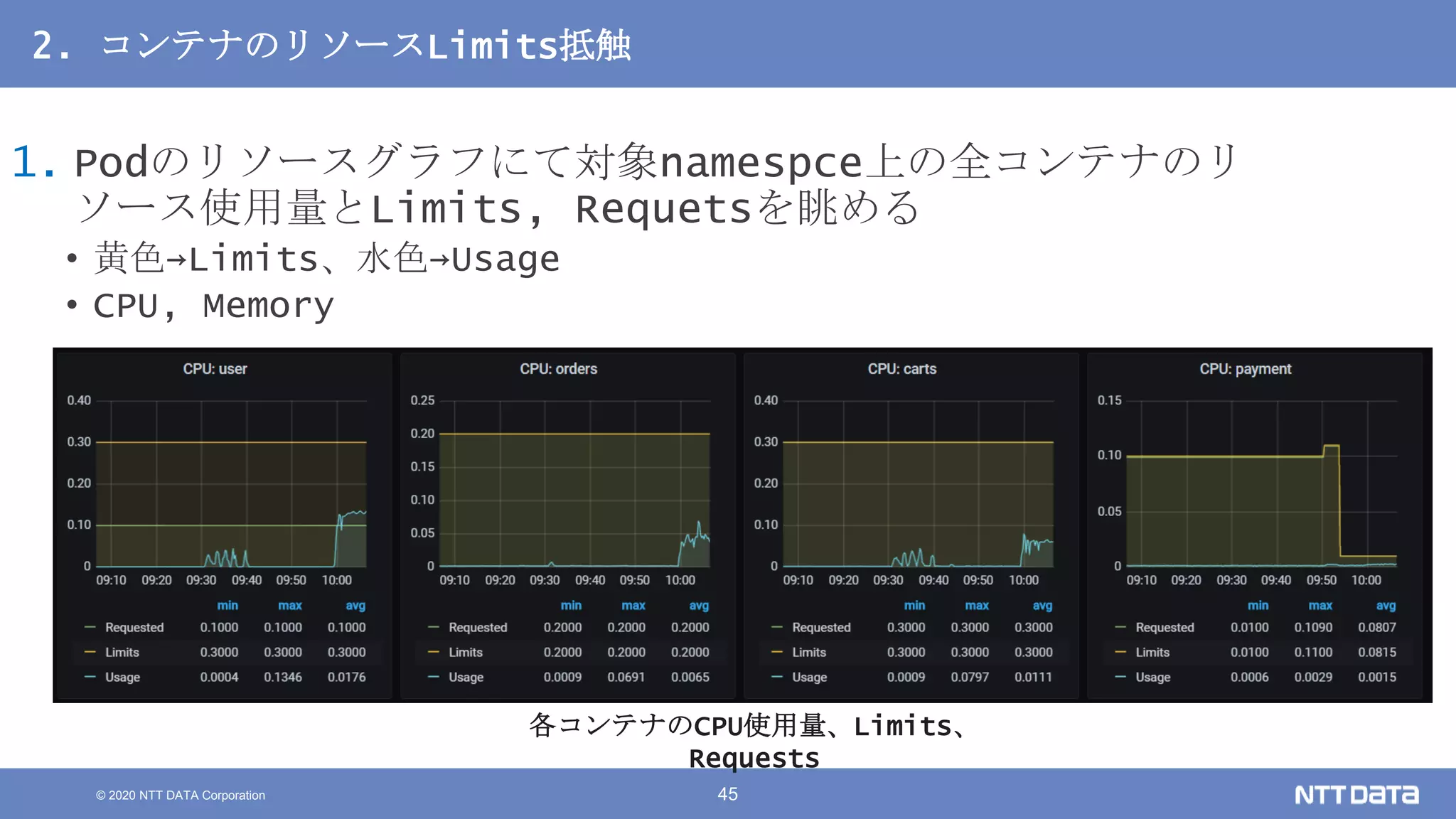
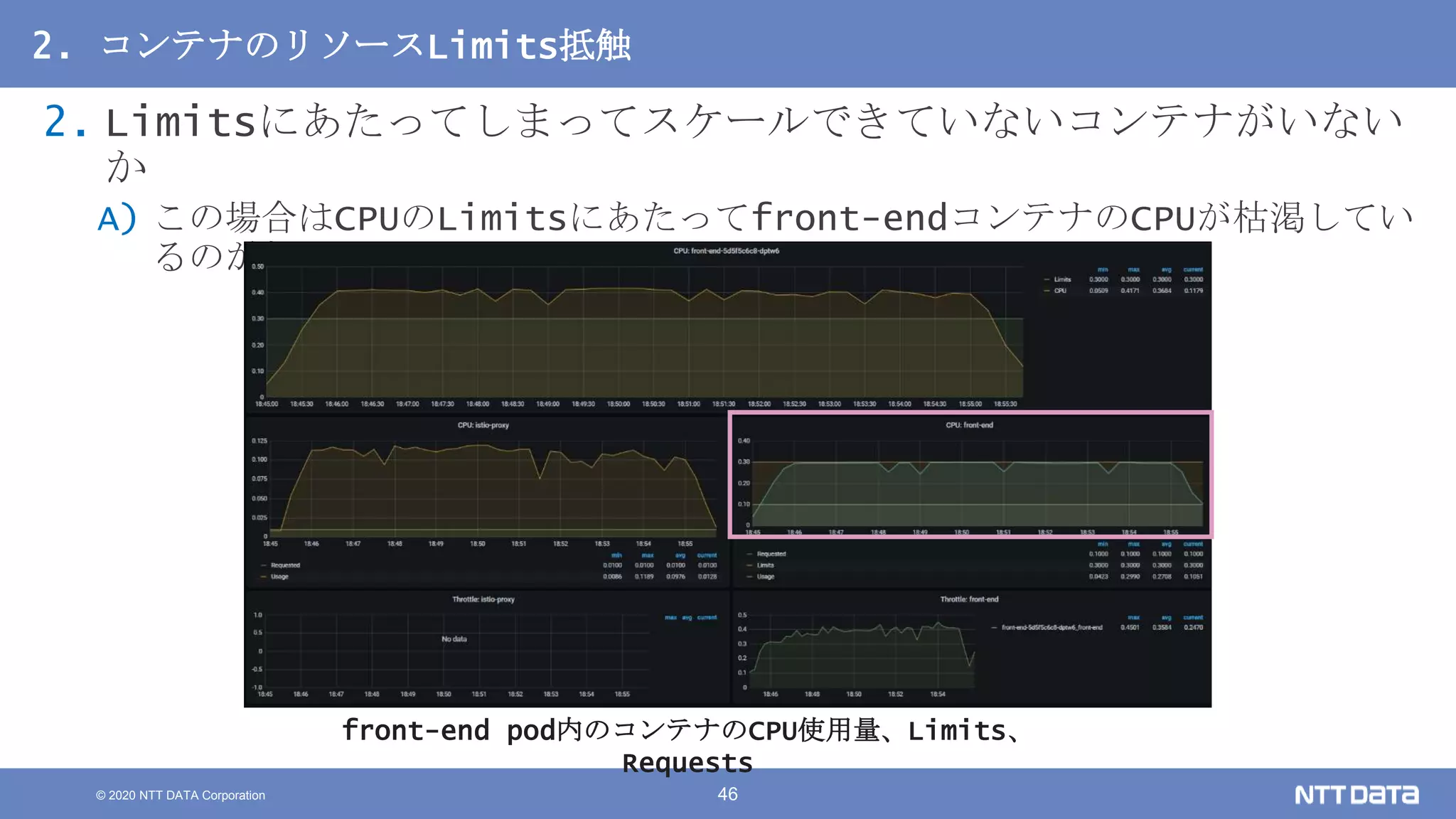
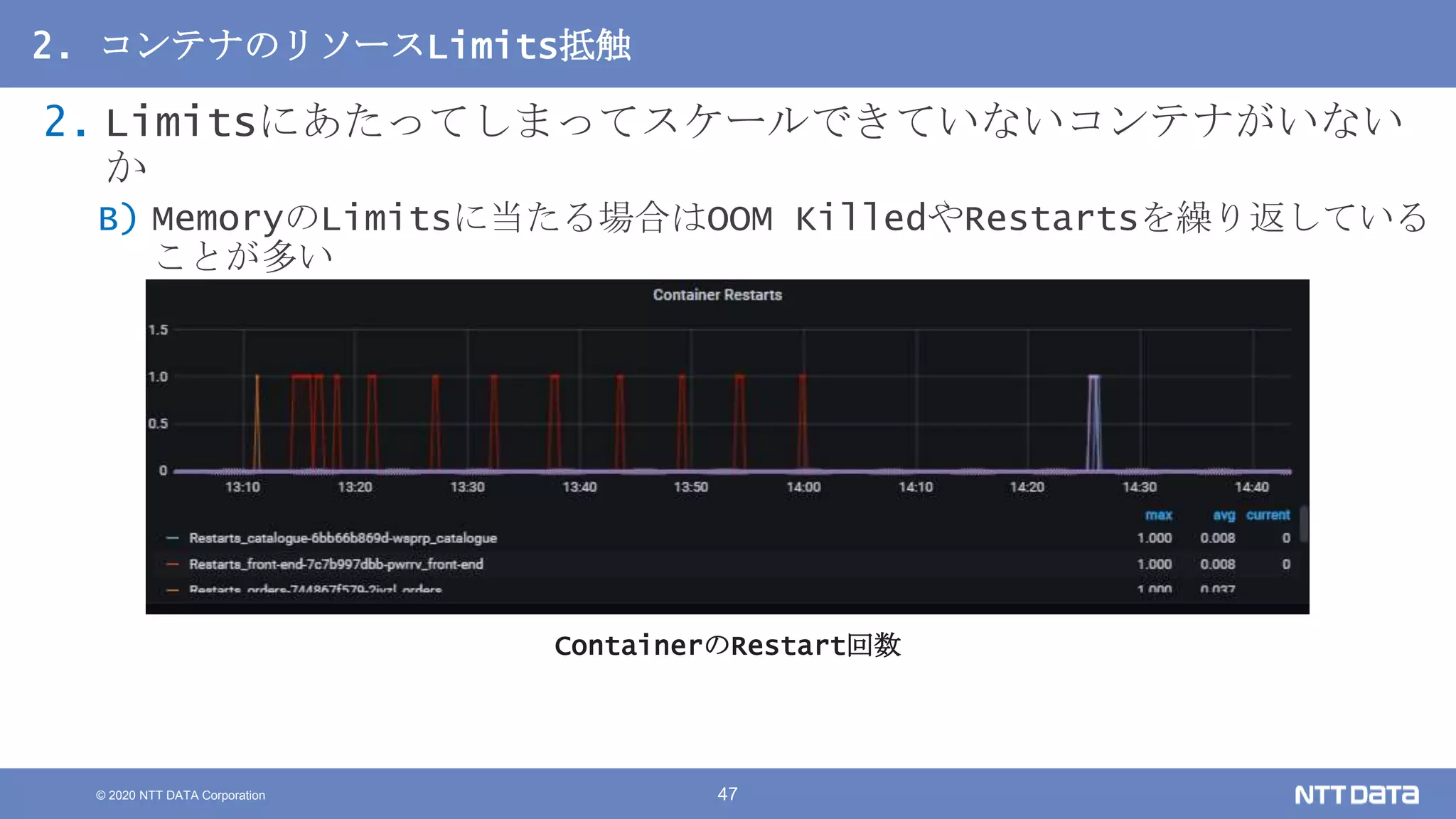
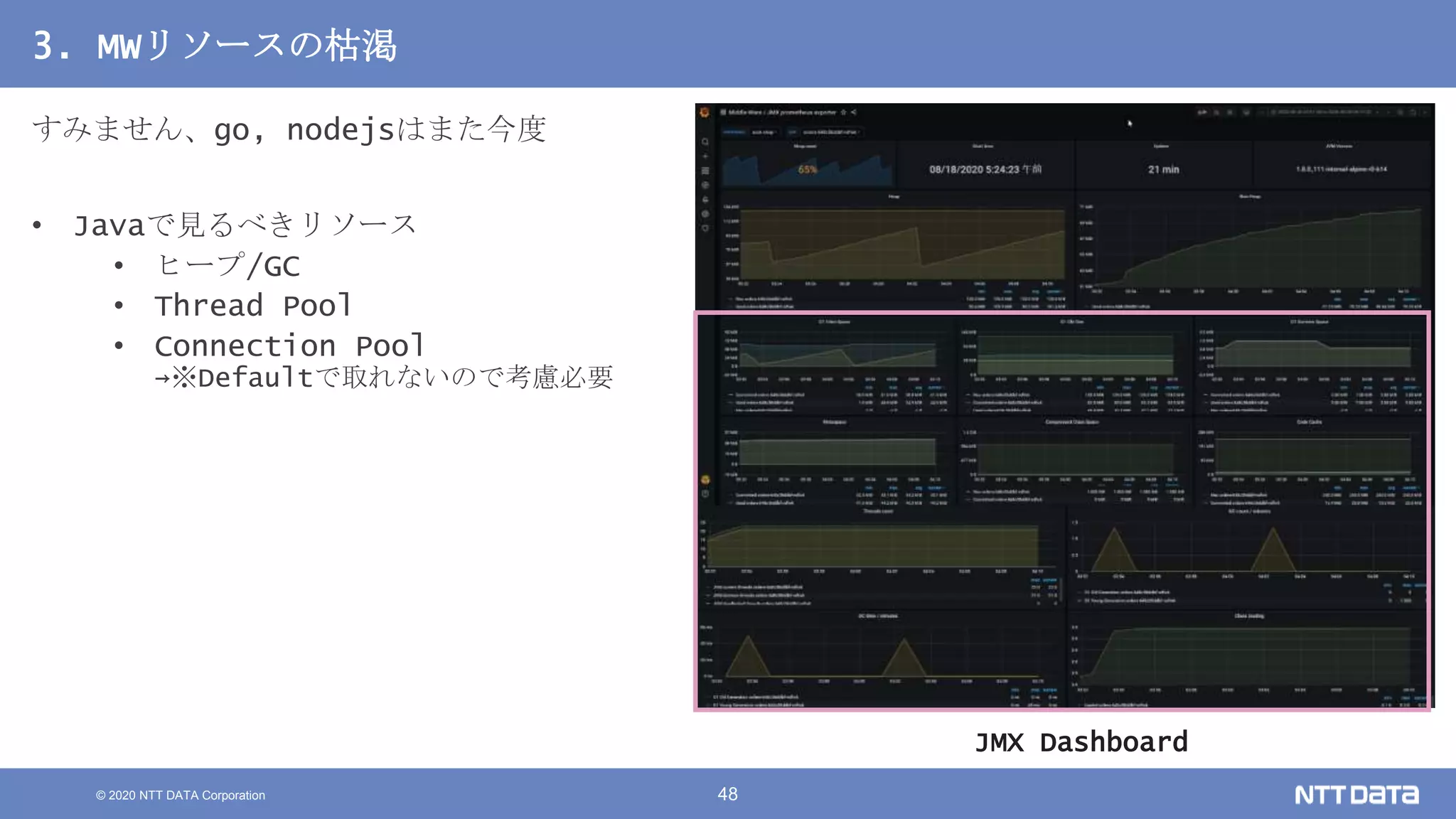
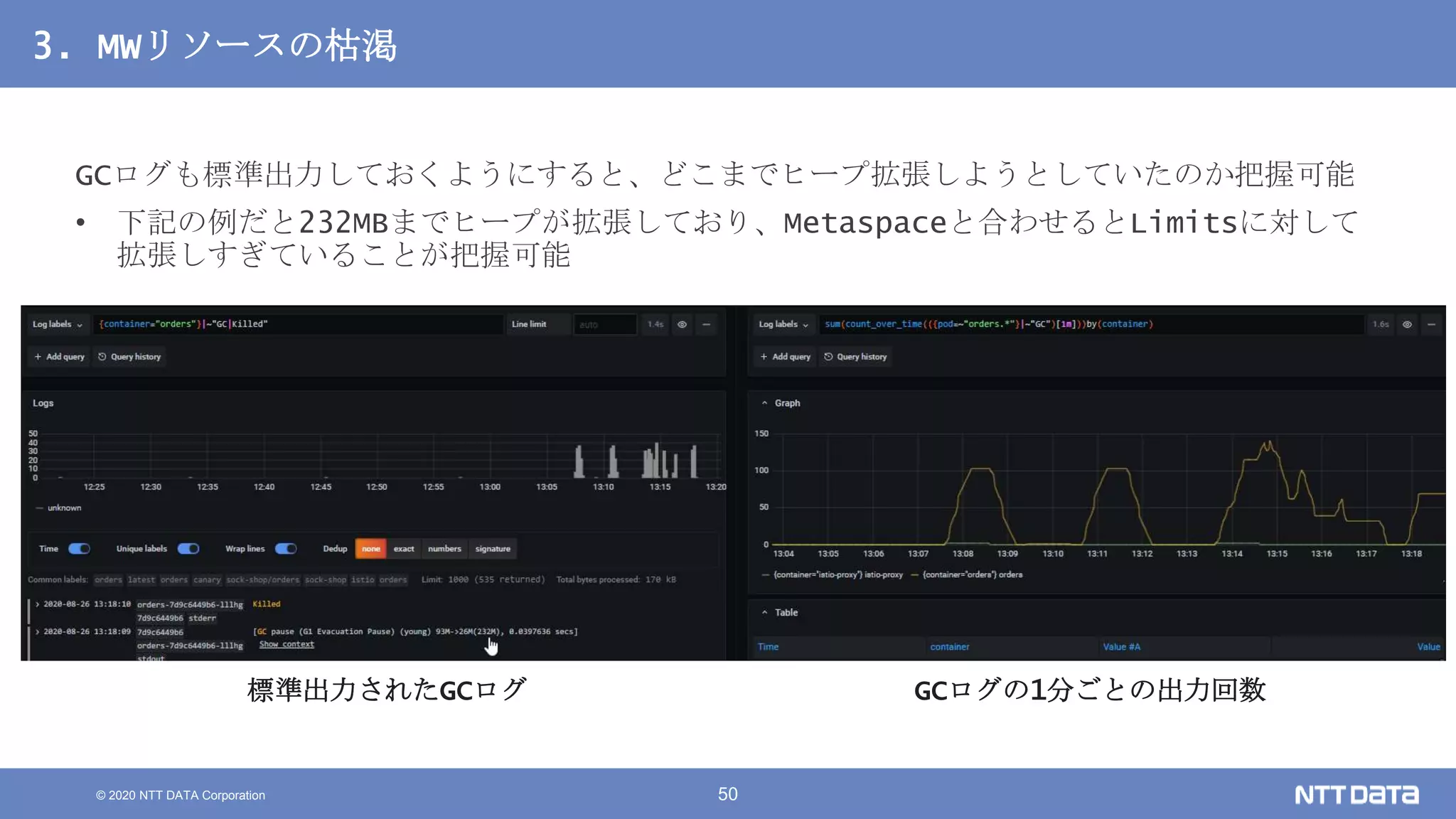
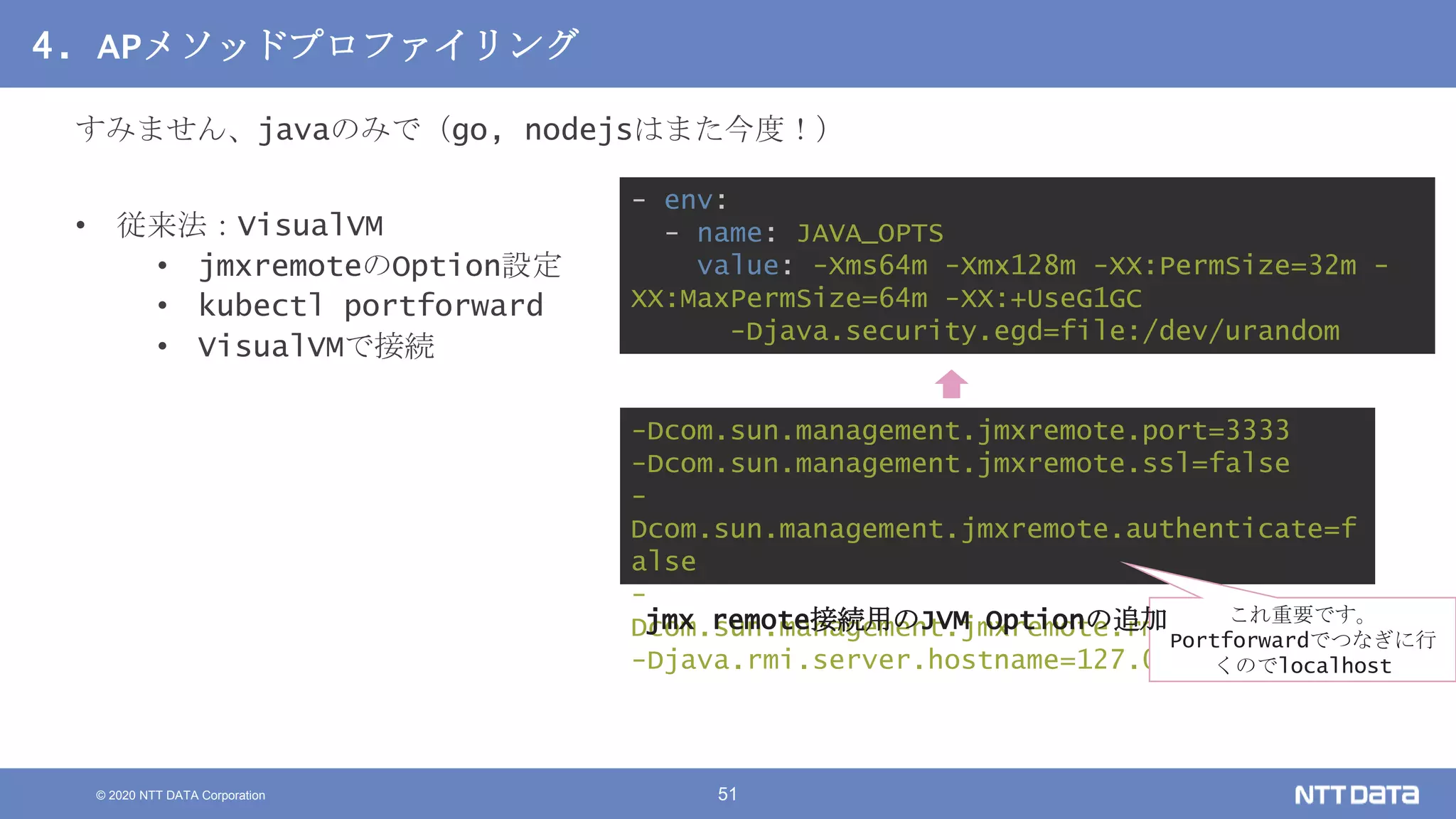
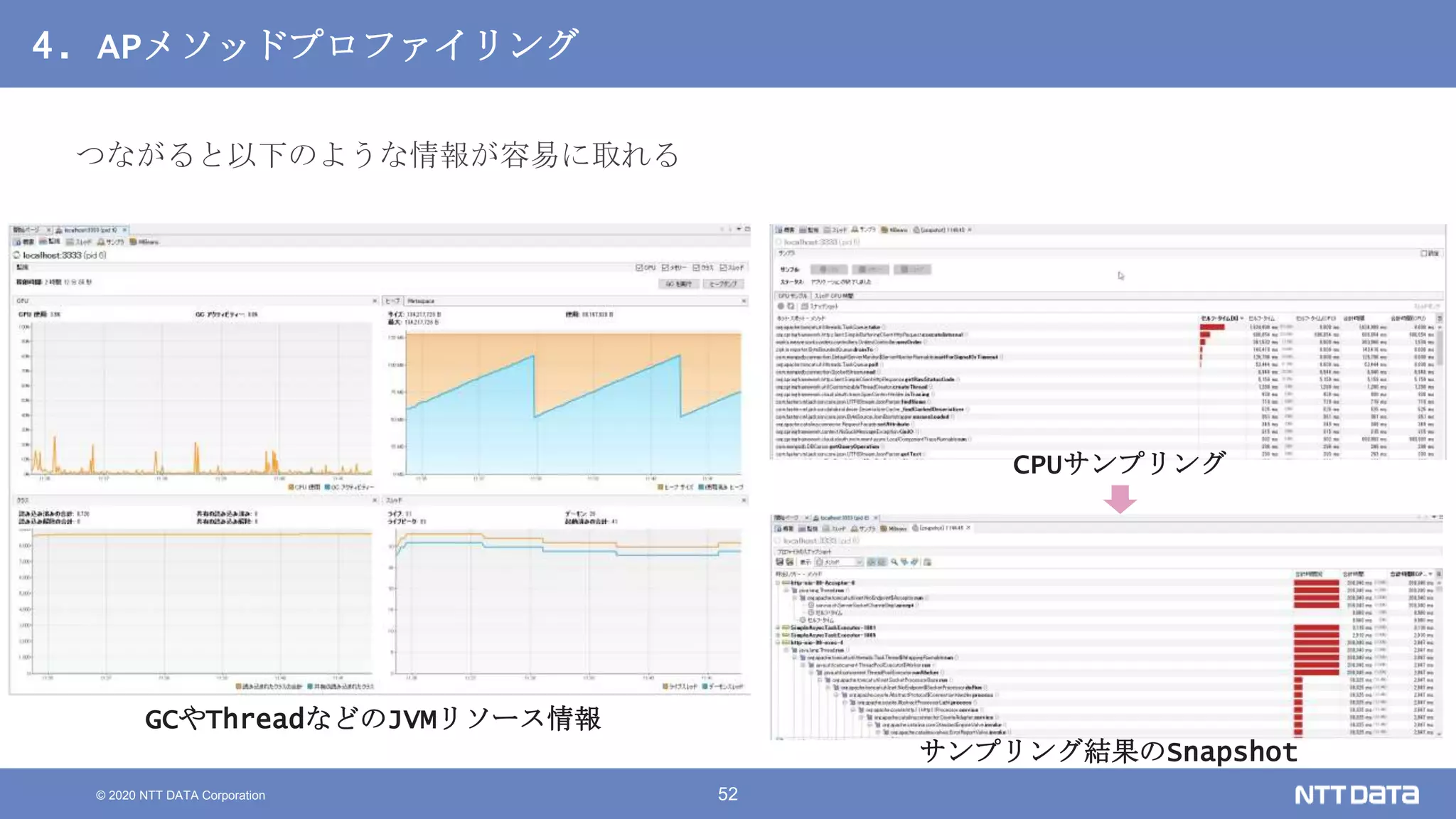
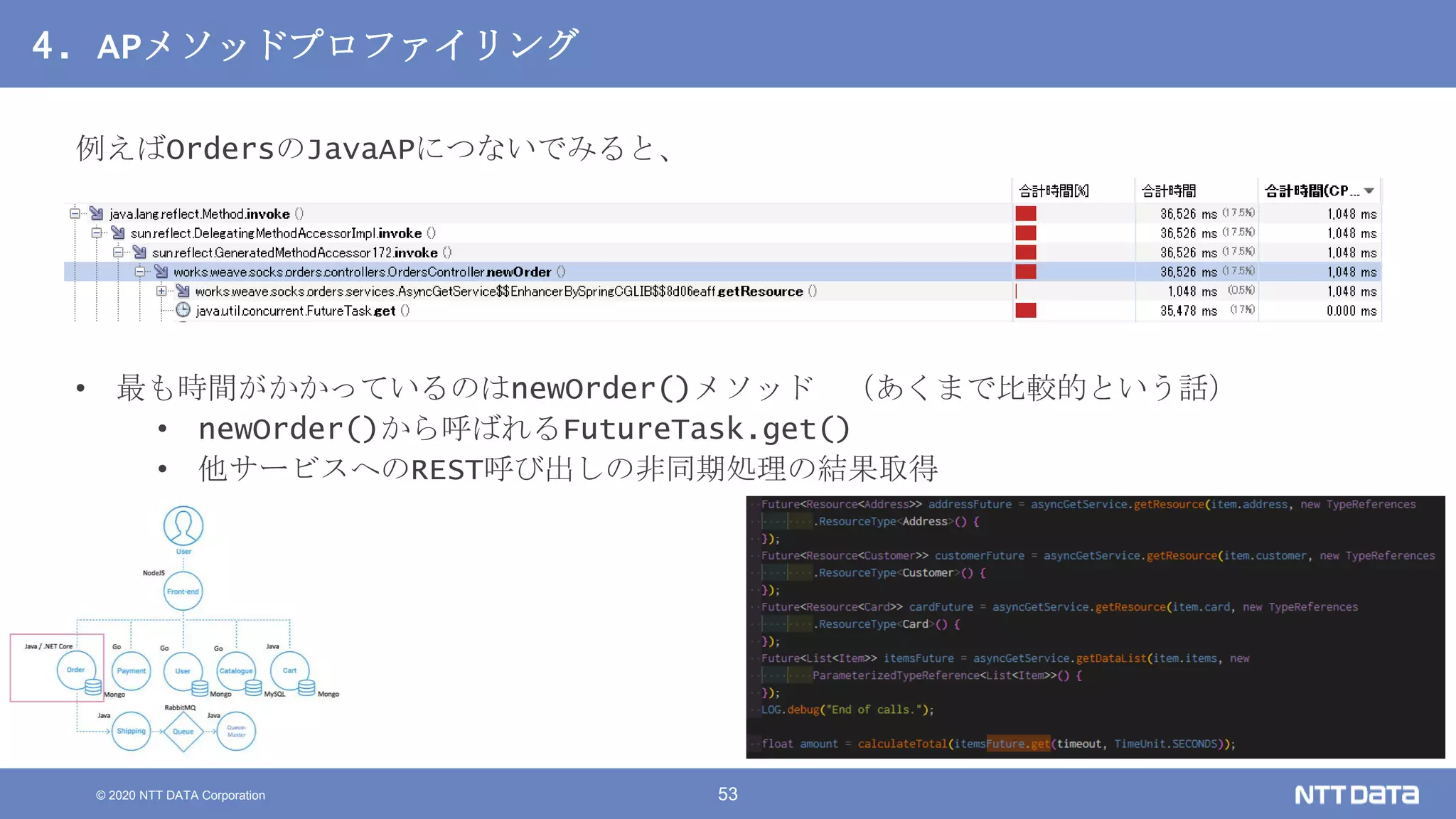
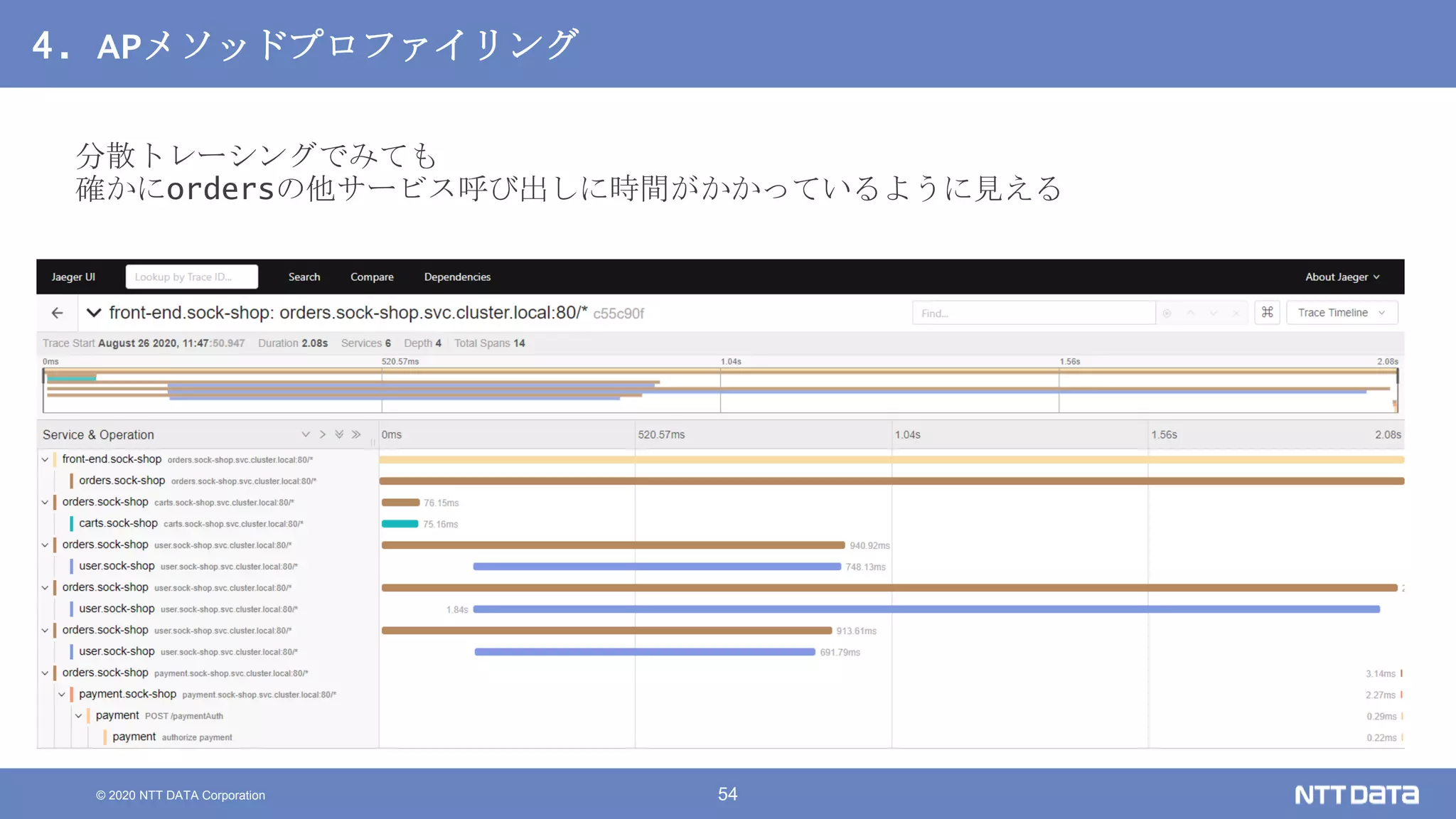
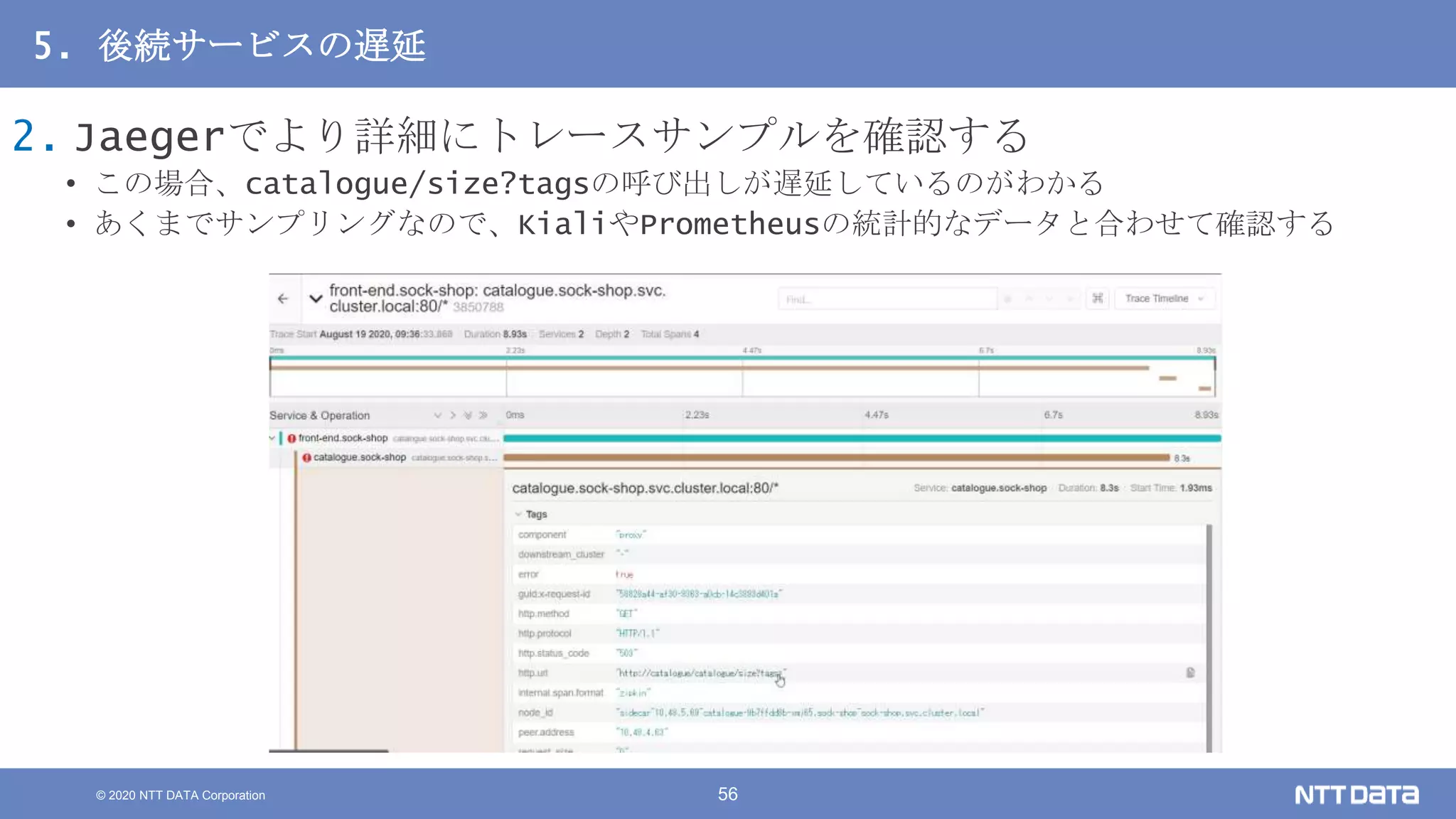
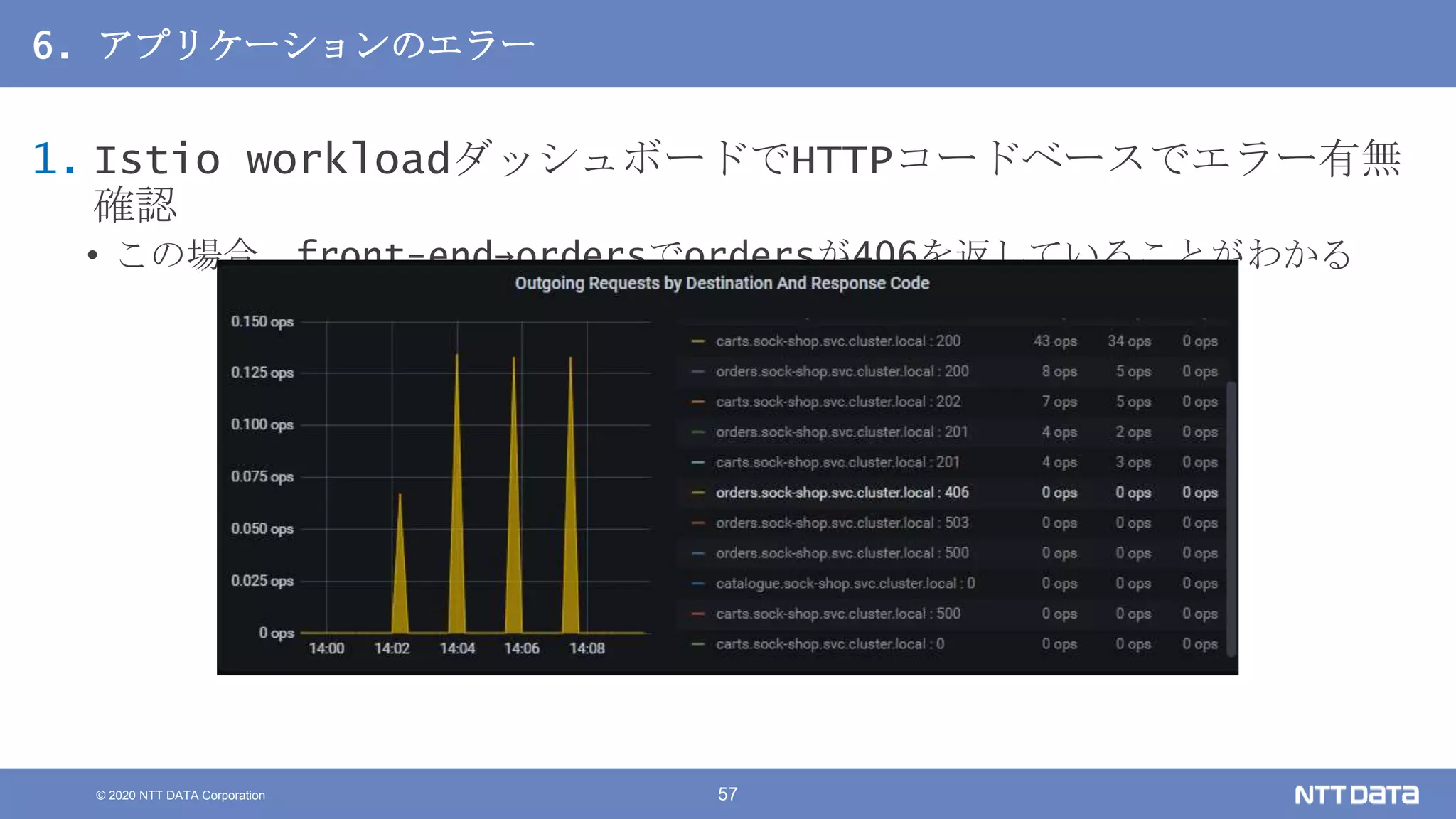
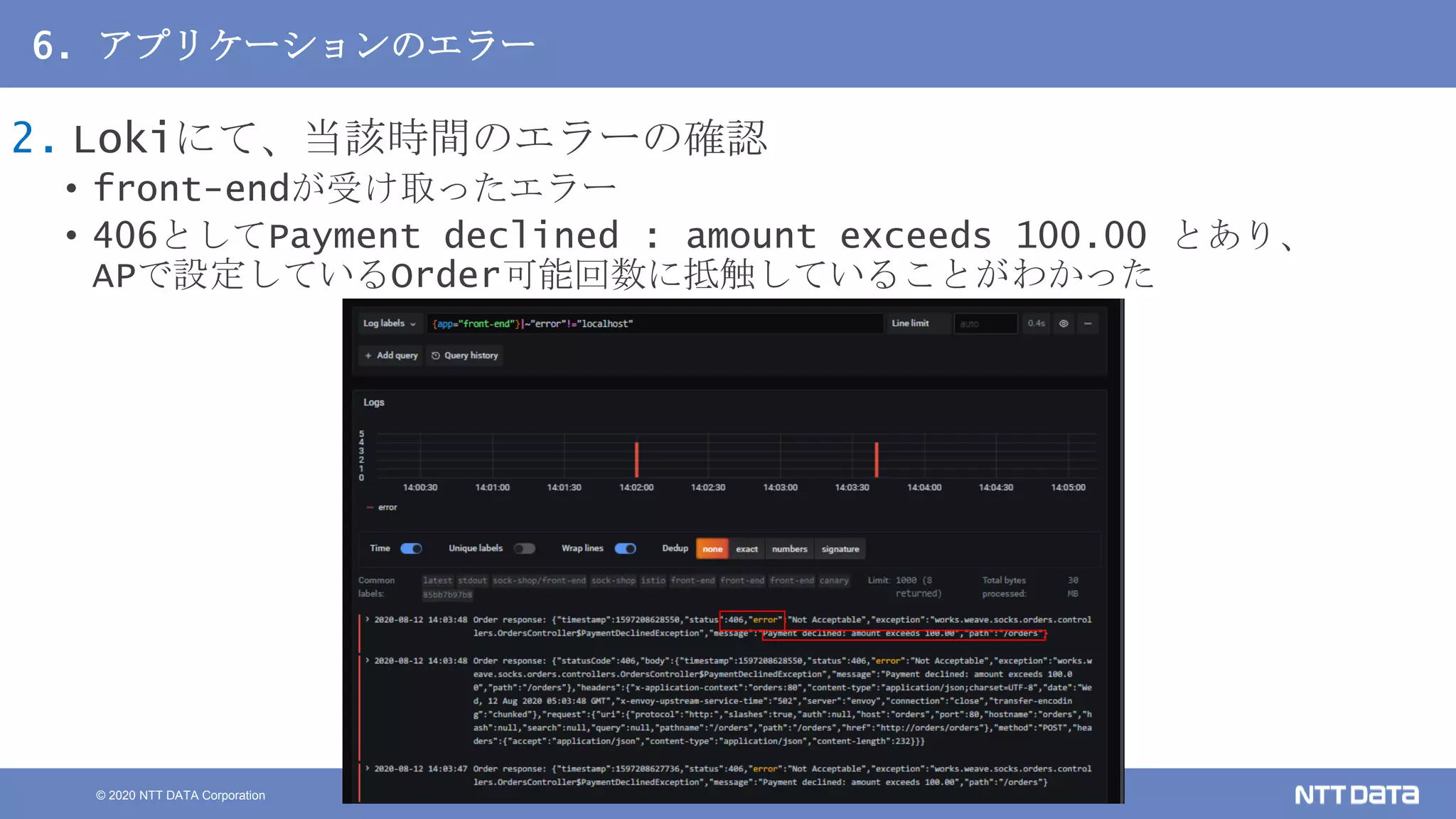
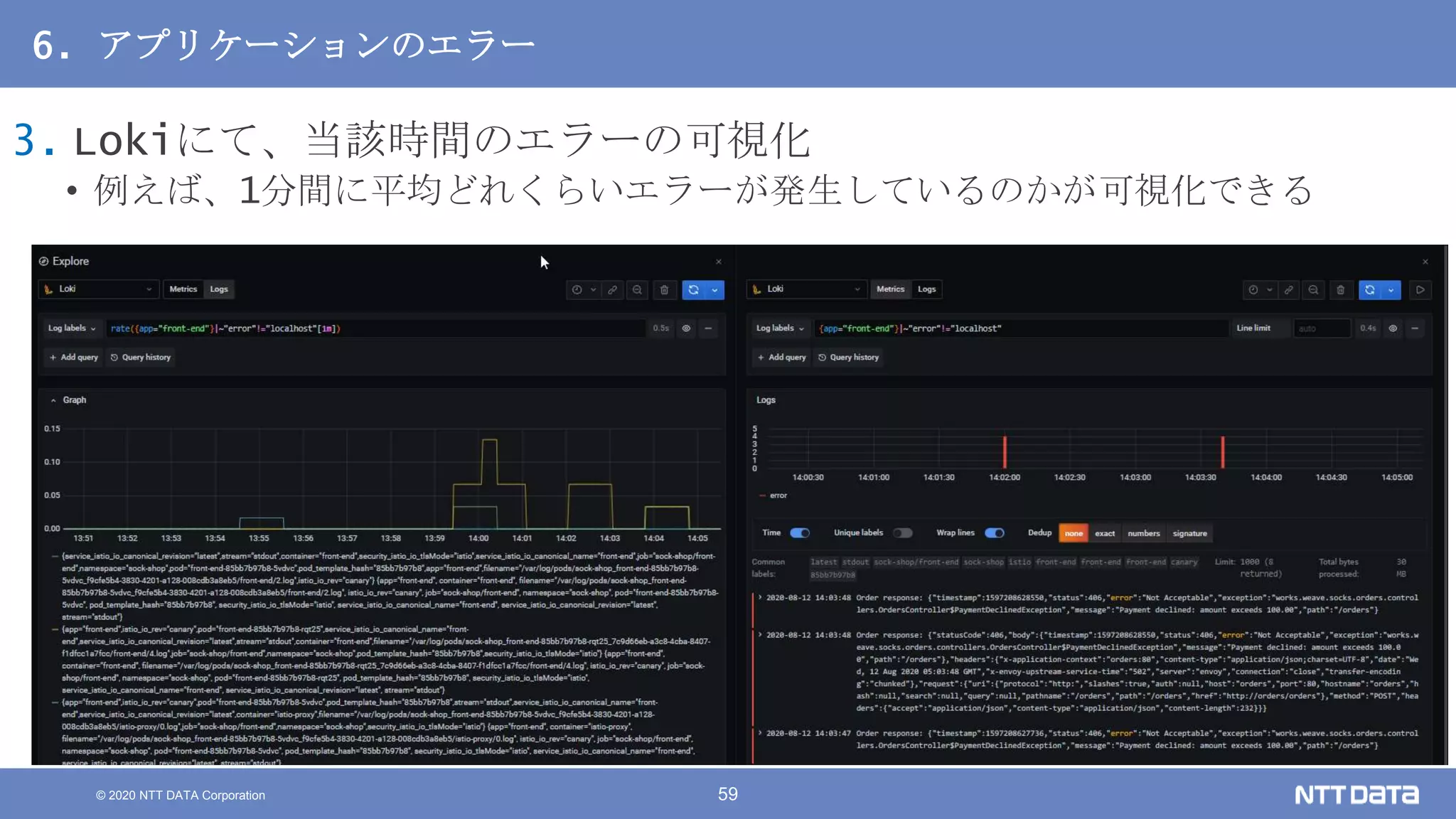
Kubernetesでの性能解析 ~なんとなく遅いからの脱却~ (Kubernetes Meetup Tokyo #33 発表資料) 2020/08/26 NTT DATA Yasuhiro Horiuchi