Download as PDF, PPTX











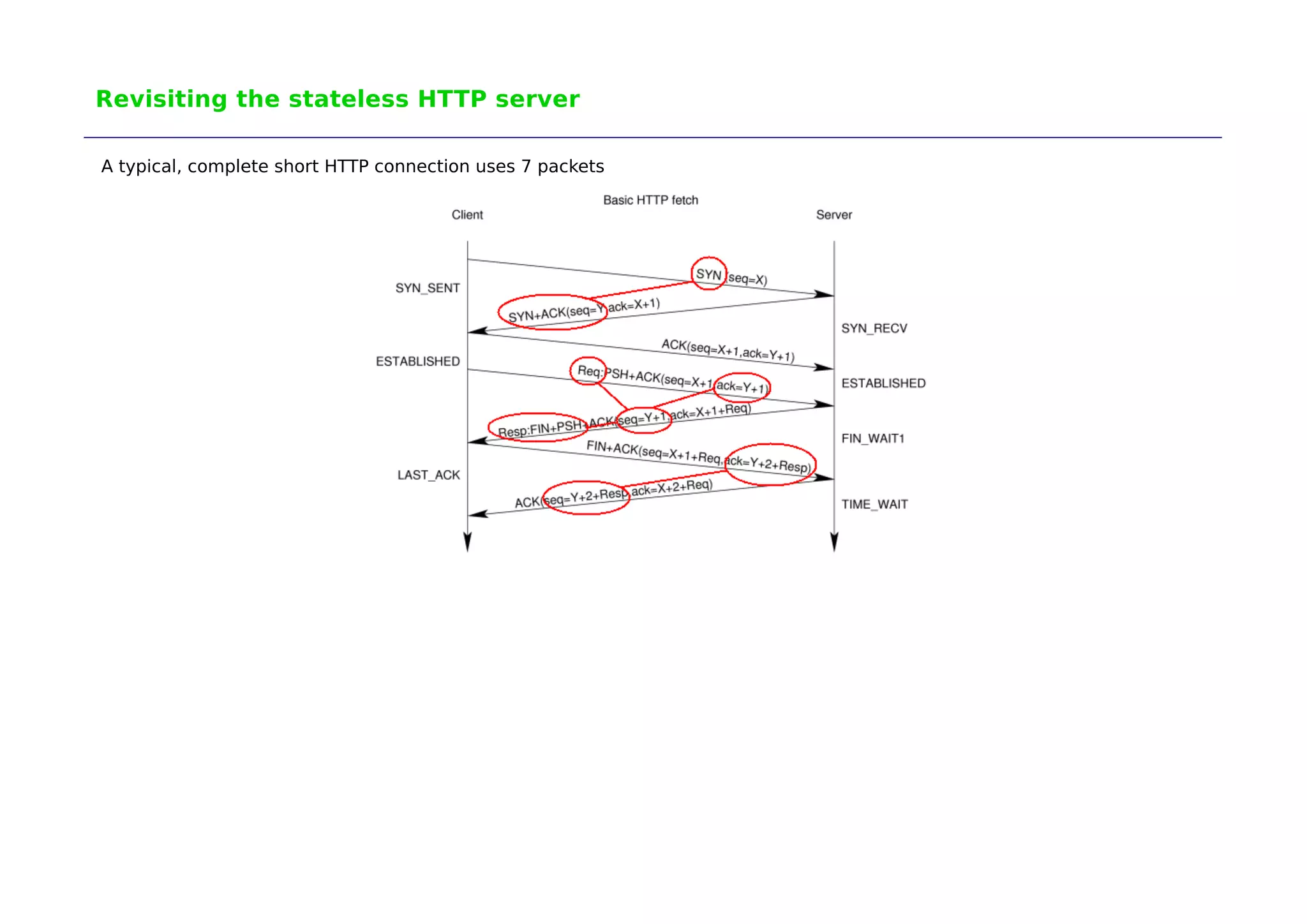






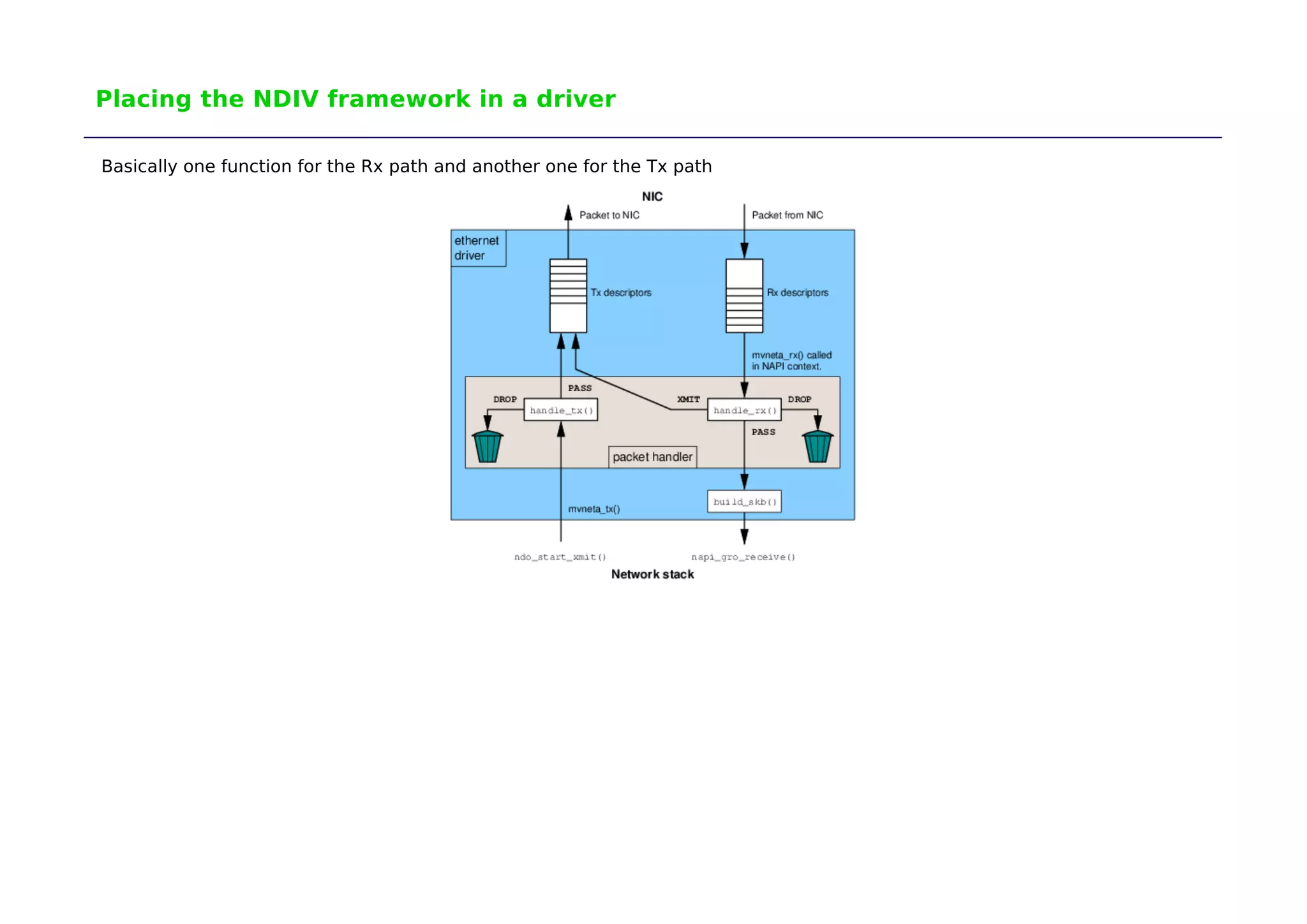
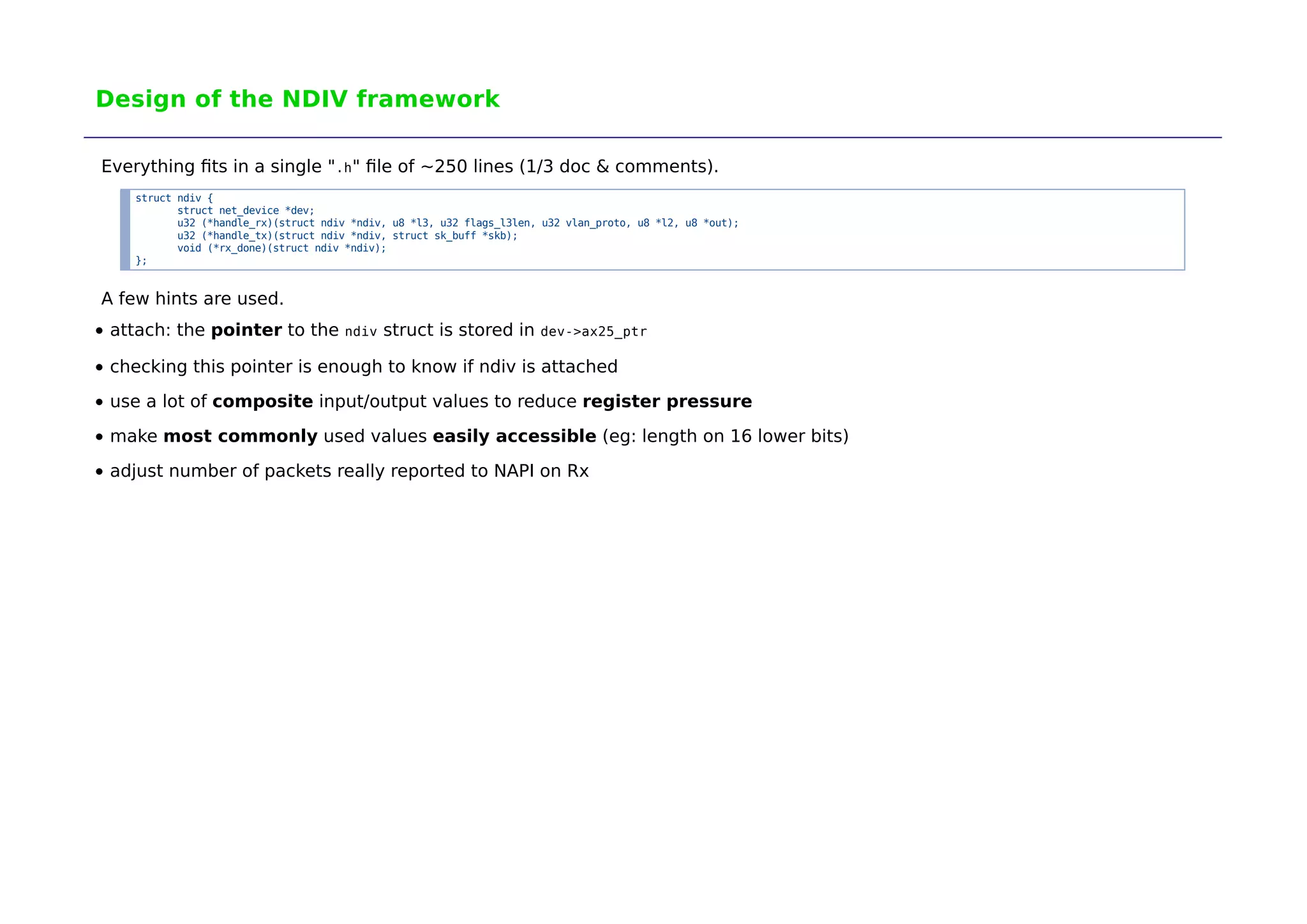








The document discusses the development of 'ndiv', a low overhead network traffic diverter aimed at improving performance for testing firewalls and servers. It outlines the history of related tools, design challenges, and the framework's implementation, which allows rapid packet processing with minimal overhead. Potential applications include network testing, packet capture, and traffic management, with further advancements expected in the future.













![CETH for XDP [Linux Meetup Santa Clara | July 2016]](https://cdn.slidesharecdn.com/ss_thumbnails/ceth5overview1-160801192921-thumbnail.jpg?width=640&height=640&fit=bounds)








































































