Download as PDF, PPTX



![VLAN userspace interfaces in Linux kernel
● Ioctl-based
○ Introduced along with the initial VLAN implementation in 2002
○ Userspace tool is called vconfig:
# vconfig add eth0 100
Added VLAN with VID == 100 to IF -:eth0:-
# ip address add 192.168.0.1/24 dev eth0.100
● Netlink-based
○ Introduced by following commit:
commit 07b5b17e157b7018d0ca40ca0d1581a23096fb45
Author: Patrick McHardy <kaber@trash.net>
Date: Wed Jun 13 12:07:54 2007 -0700
[VLAN]: Use rtnl_link API
○ Extends use of ip tool (a part of iproute2 package):
# ip link add link eth0 name eth0.100 type vlan id 100
# ip address add 192.168.0.1/24 dev eth0.100](https://image.slidesharecdn.com/kerneltlvvlan-160530071020/75/VLANs-in-the-Linux-Kernel-7-2048.jpg)














![BPF usage for networking purposes
● TC clsact support added to iproute2 by:
commit 8f9afdd531560c1534be44424669add2e19deeec
Author: Daniel Borkmann <daniel@iogearbox.net>
Date: Tue Jan 12 01:42:20 2016 +0100
tc, clsact: add clsact frontend
Add the tc part for the kernel commit 1f211a1b929c ("net, sched: add
clsact qdisc"). Quoting example usage from that commit description:
Example, adding qdisc:
# tc qdisc add dev foo clsact
# tc qdisc show dev foo
qdisc mq 0: root
qdisc pfifo_fast 0: parent :1 bands 3 priomap 1 2 2 2 1 2 0 0 1 1 1 1 1 1 1 1
qdisc pfifo_fast 0: parent :2 bands 3 priomap 1 2 2 2 1 2 0 0 1 1 1 1 1 1 1 1
qdisc pfifo_fast 0: parent :3 bands 3 priomap 1 2 2 2 1 2 0 0 1 1 1 1 1 1 1 1
qdisc pfifo_fast 0: parent :4 bands 3 priomap 1 2 2 2 1 2 0 0 1 1 1 1 1 1 1 1
qdisc clsact ffff: parent ffff:fff1
Adding filters (deleting, etc works analogous by specifying ingress/egress):
# tc filter add dev foo ingress bpf da obj bar.o sec ingress
# tc filter add dev foo egress bpf da obj bar.o sec egress
# tc filter show dev foo ingress
filter protocol all pref 49152 bpf
filter protocol all pref 49152 bpf handle 0x1 bar.o:[ingress] direct-action
# tc filter show dev foo egress
filter protocol all pref 49152 bpf
filter protocol all pref 49152 bpf handle 0x1 bar.o:[egress] direct-action
The ingress parent alias can also be used with ingress qdisc.](https://image.slidesharecdn.com/kerneltlvvlan-160530071020/75/VLANs-in-the-Linux-Kernel-32-2048.jpg)


The document discusses the complexities and implementation details of VLANs within the Linux kernel, authored by Jiří Pírko, a seasoned Linux kernel and network developer. It covers various aspects such as VLAN packet formats, data paths for reception and transmission, hardware acceleration for VLANs, and the evolution of VLAN handling in the kernel over several years, culminating in over 500 commits and significant code adjustments. Additionally, it briefly addresses alternative VLAN implementations in Linux bridges and Open vSwitch, highlighting the overall progress in network device integration and management within the Linux ecosystem.
Introduction to VLANs and overview of the speaker's expertise in kernel development.
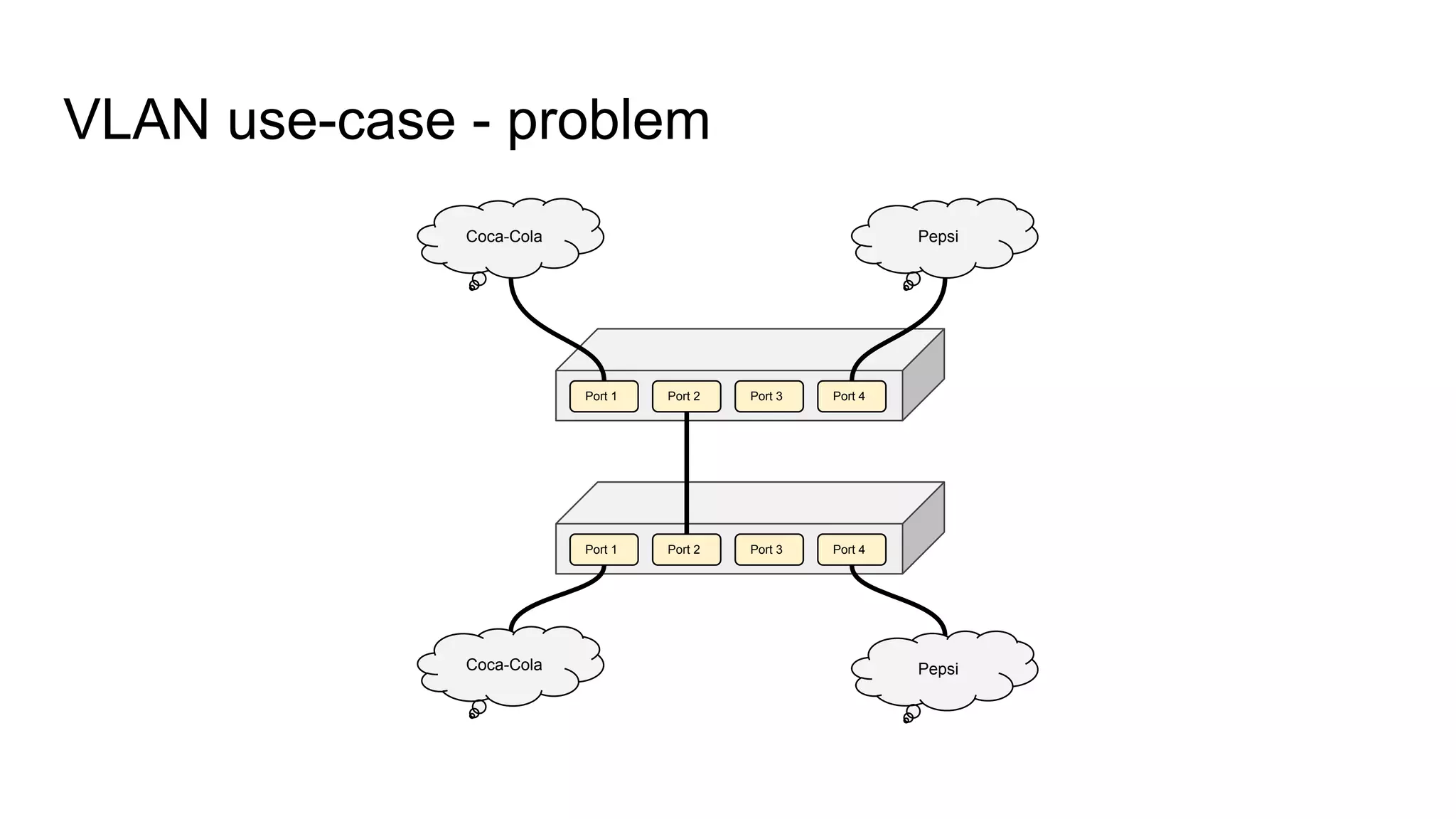
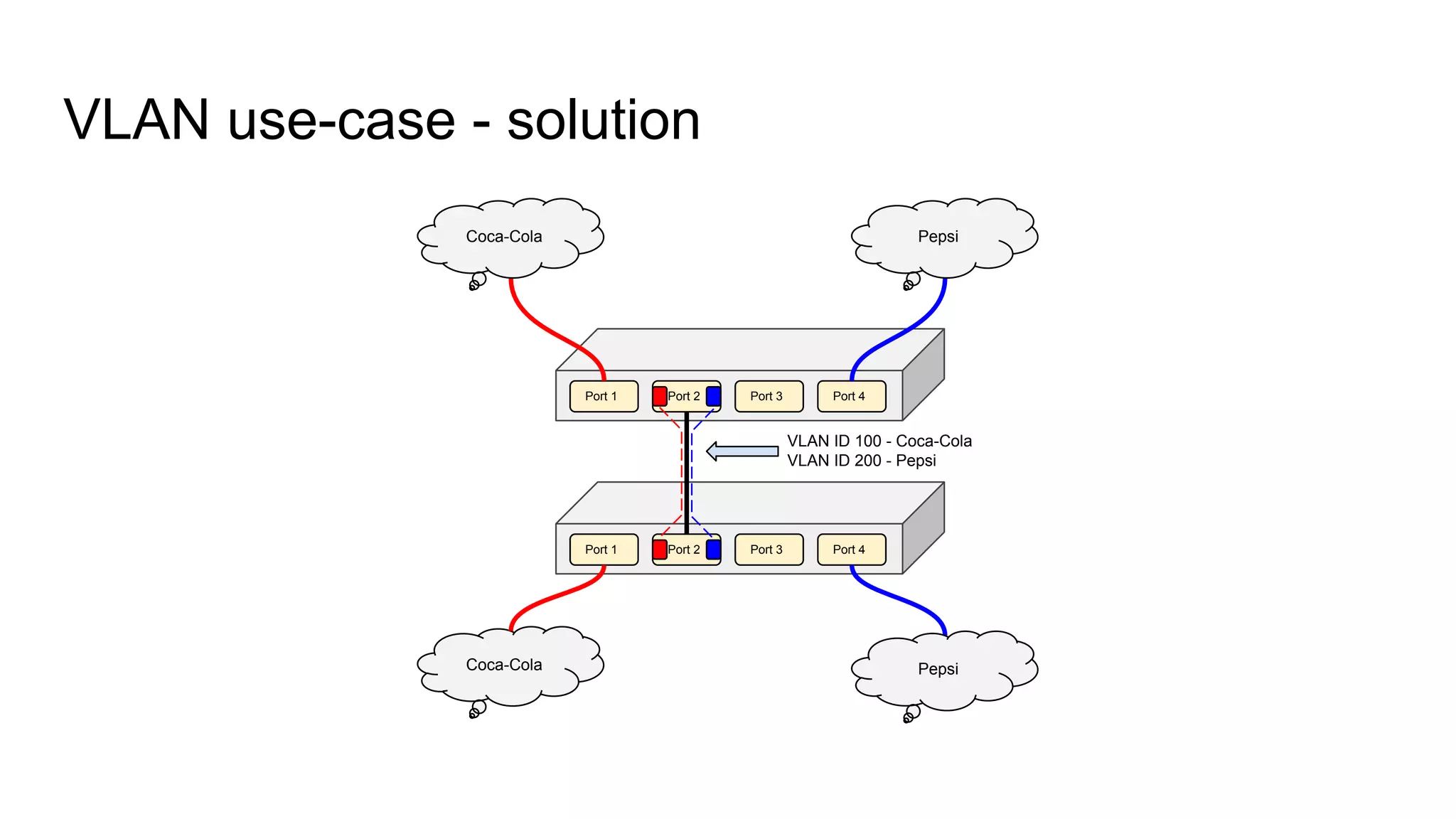
Explains the VLAN use-case scenario with Coca-Cola and Pepsi, showing problem and proposed solution for VLAN IDs.
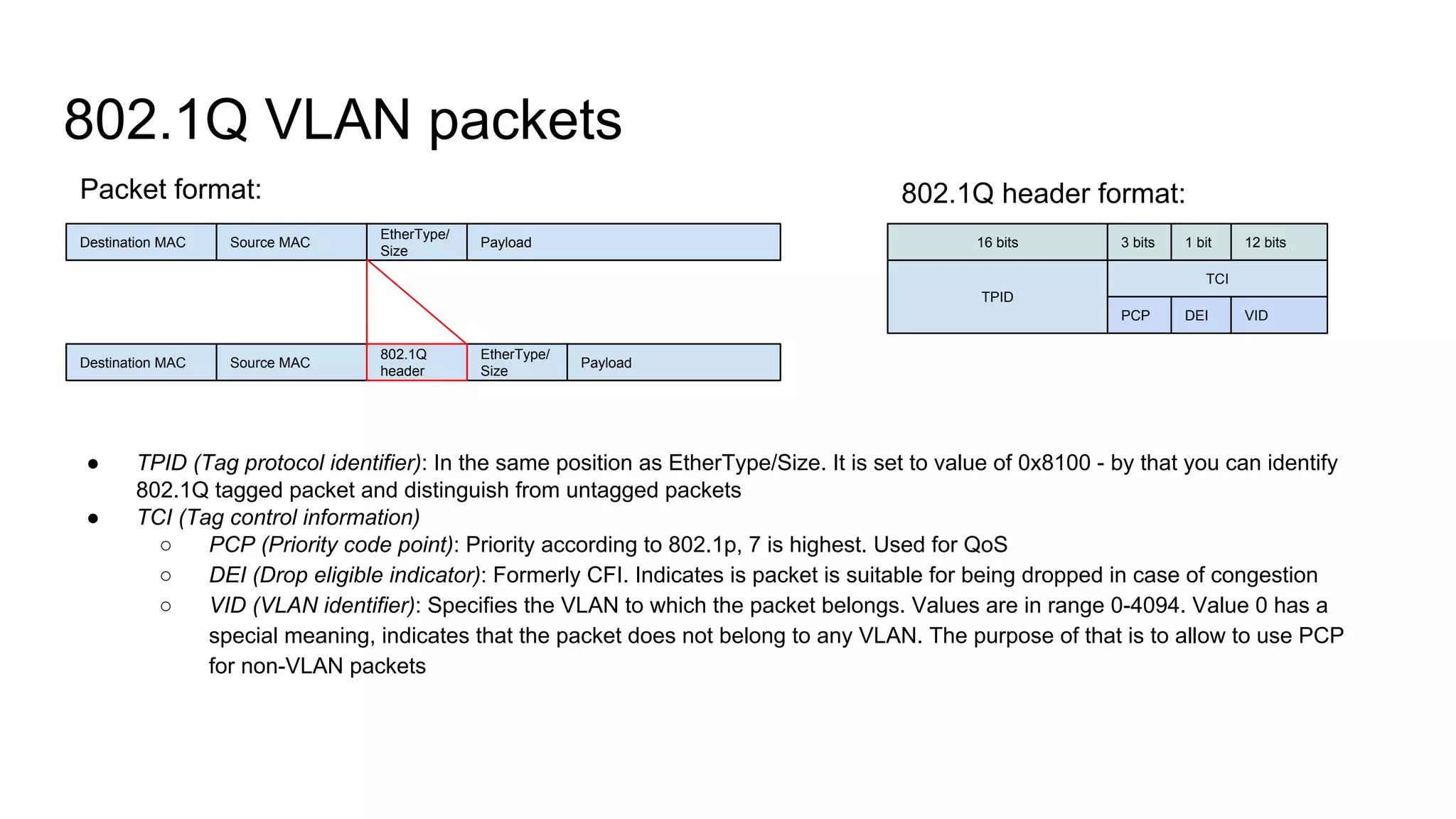
Details the structure of 802.1Q VLAN packets, covering components like TPID, TCI, PCP, and VID.
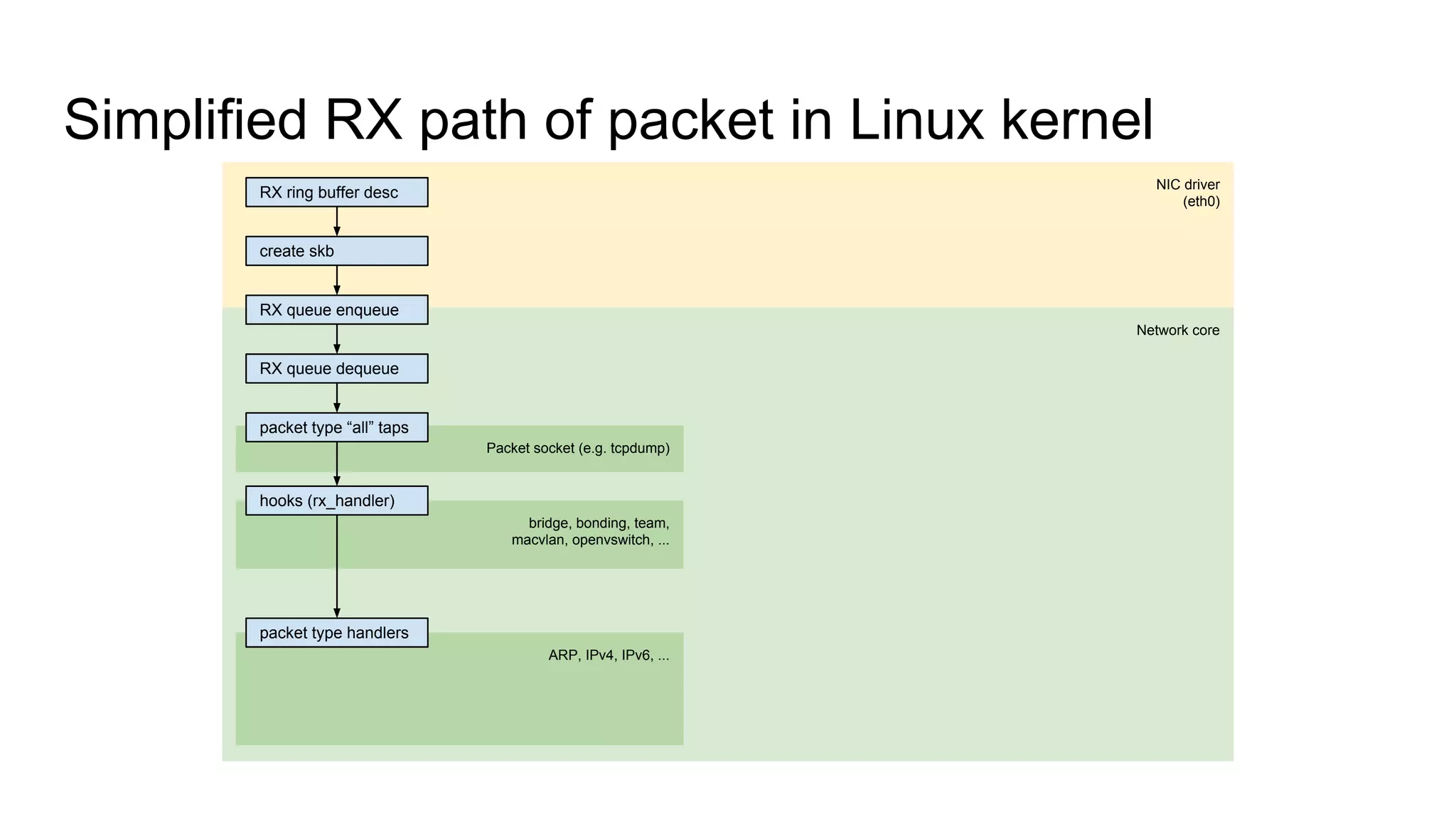
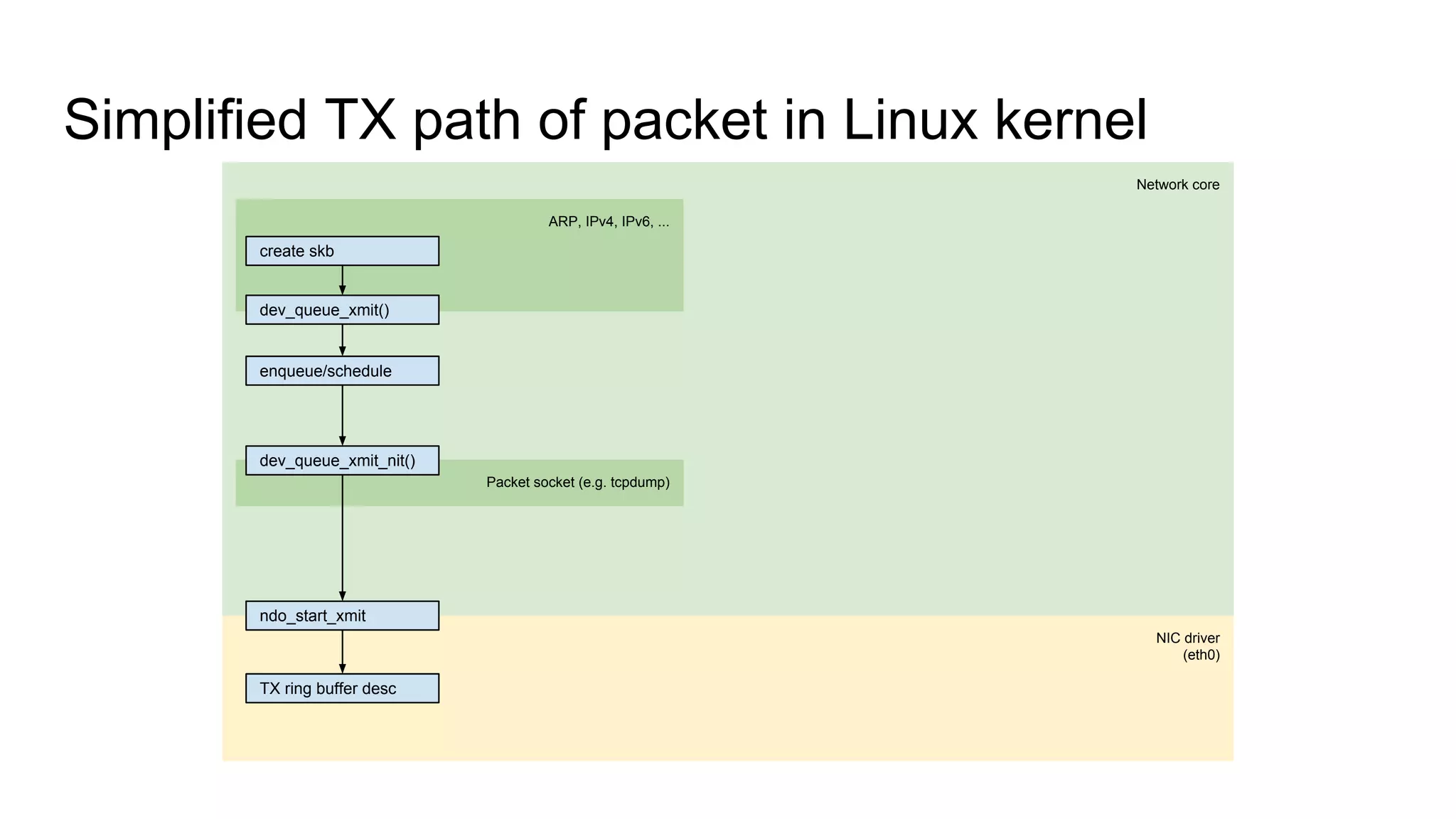
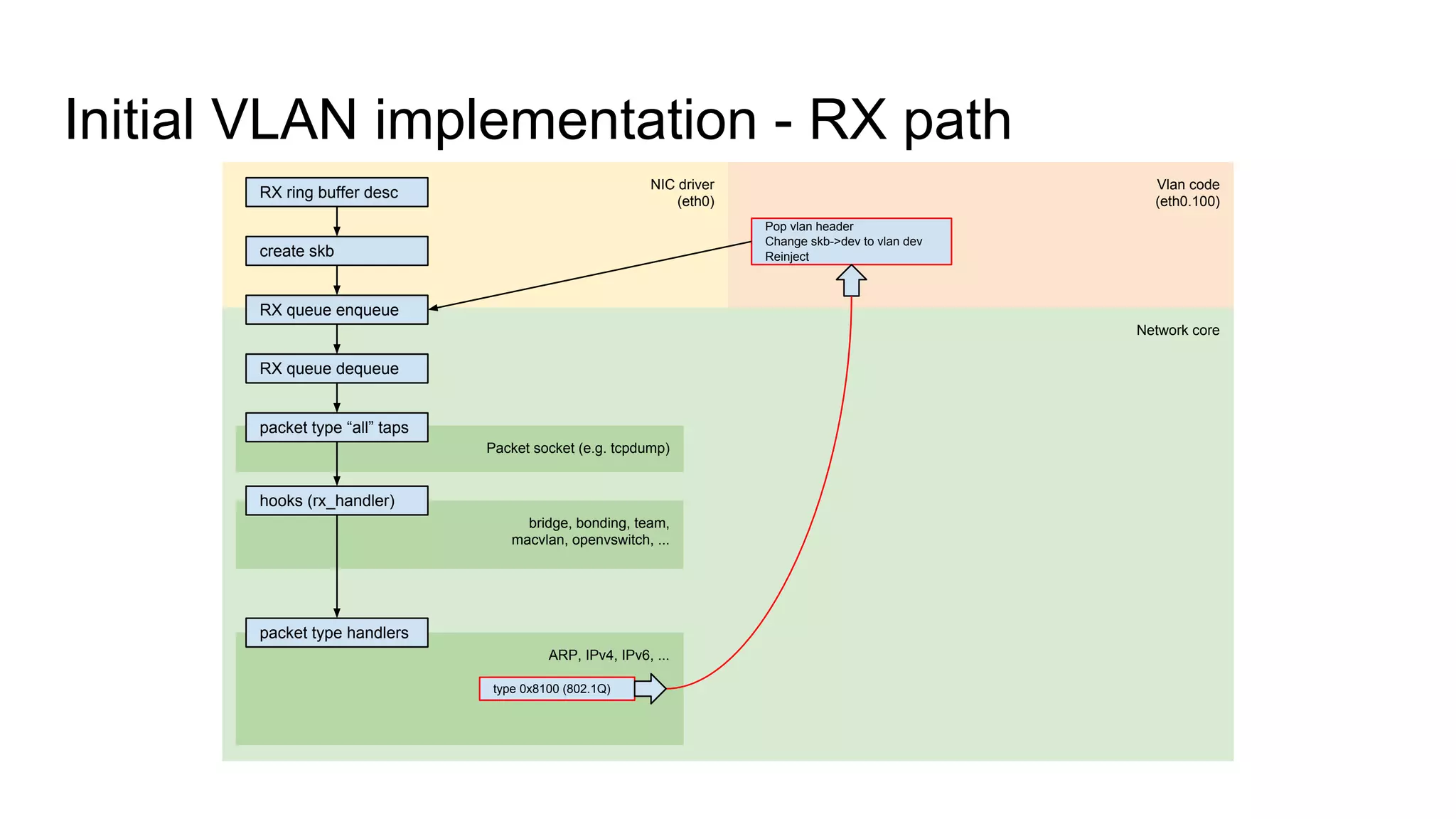
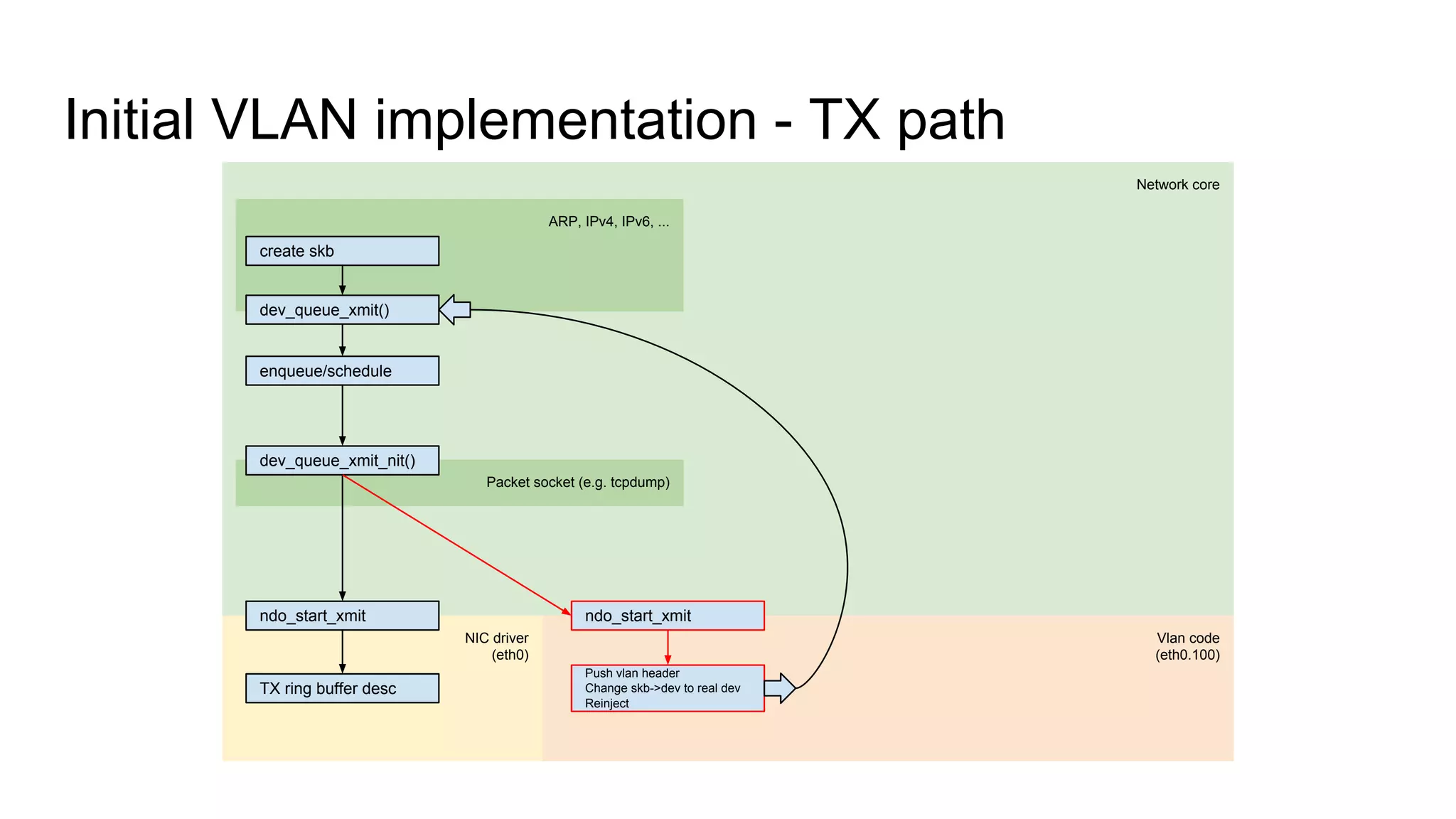
Introduces key structures like net_device and sk_buff, and illustrates RX and TX data paths in VLAN.
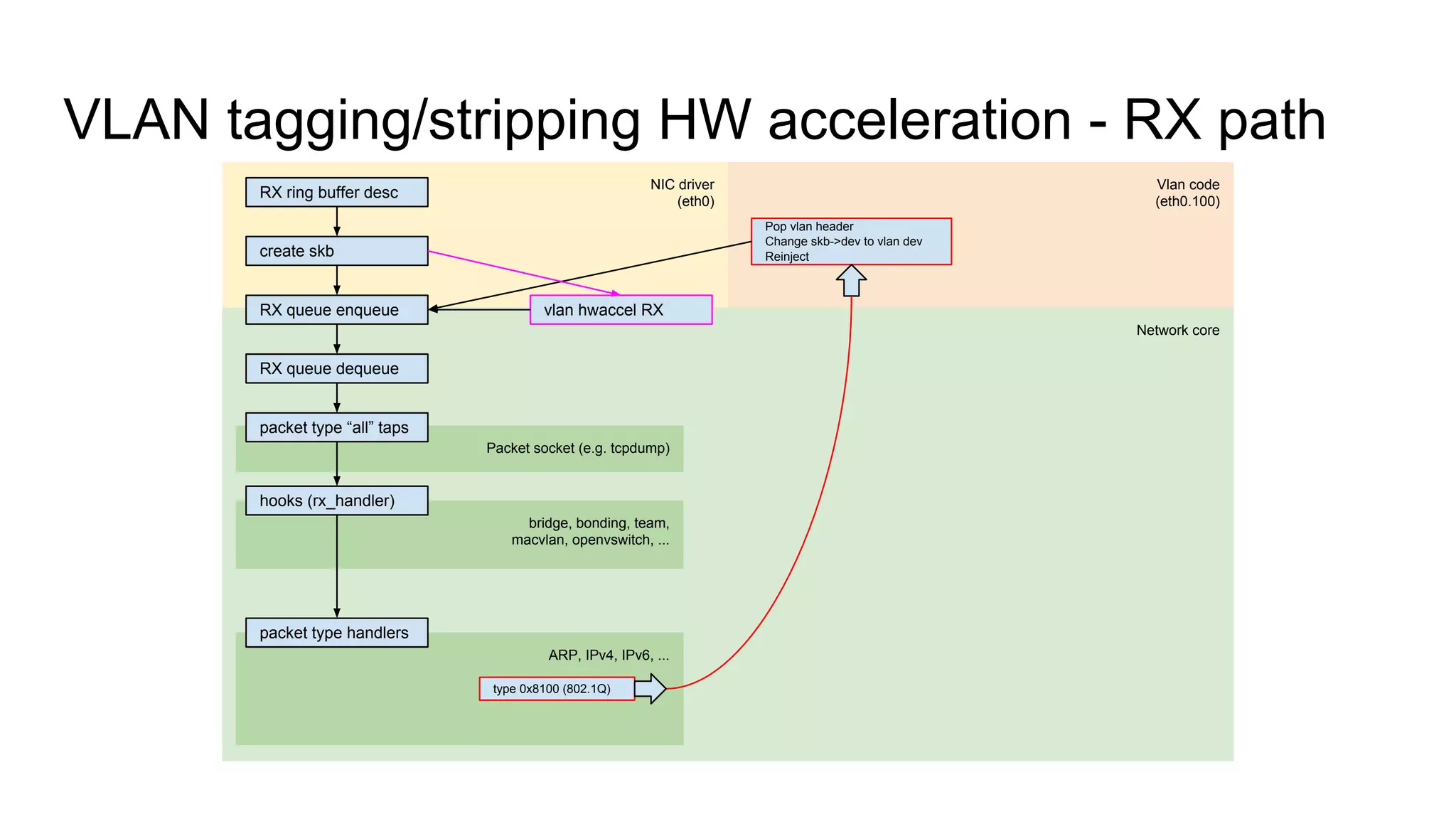
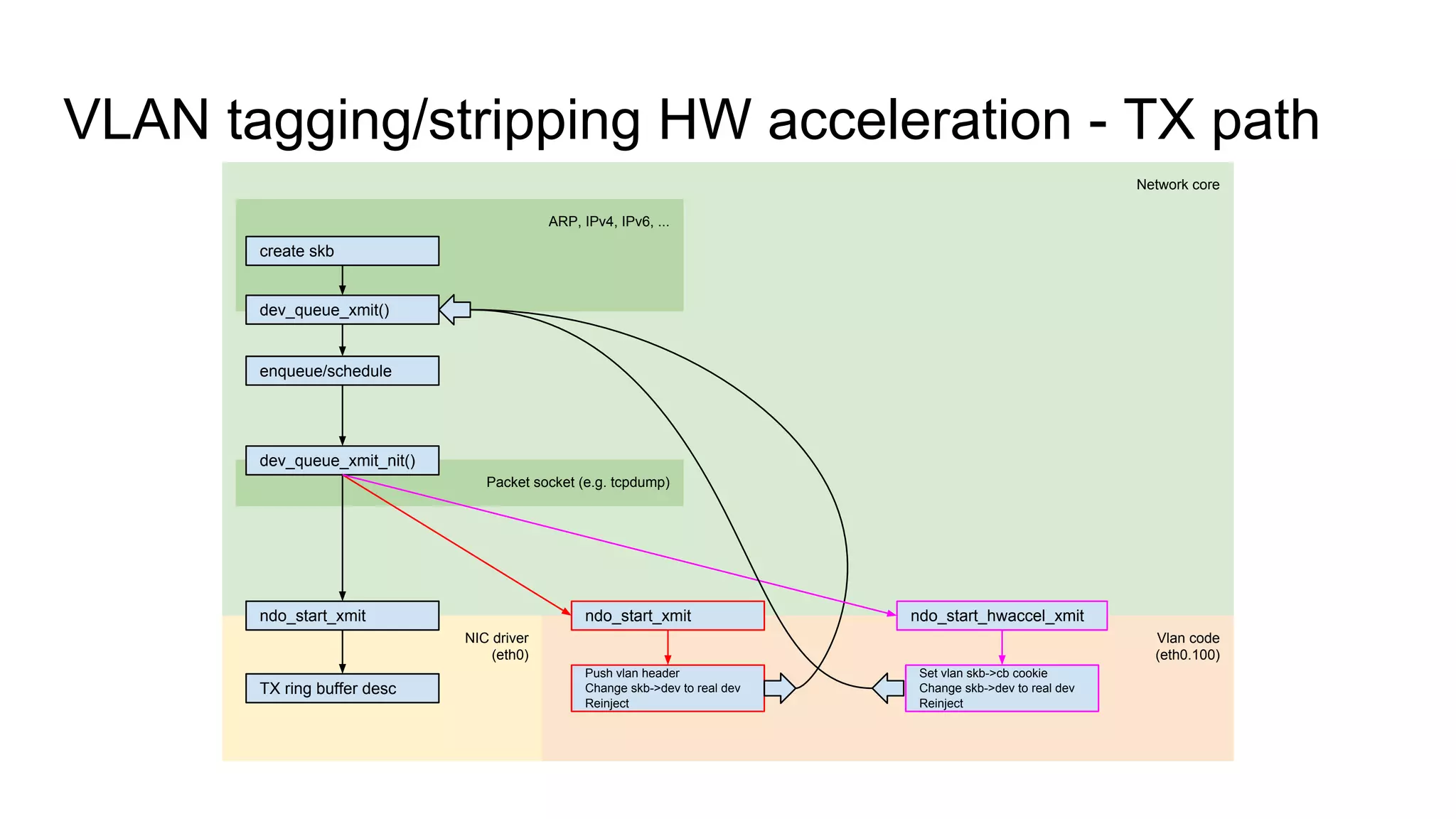
Overview of VLAN tagging and stripping hardware acceleration for RX and TX paths.
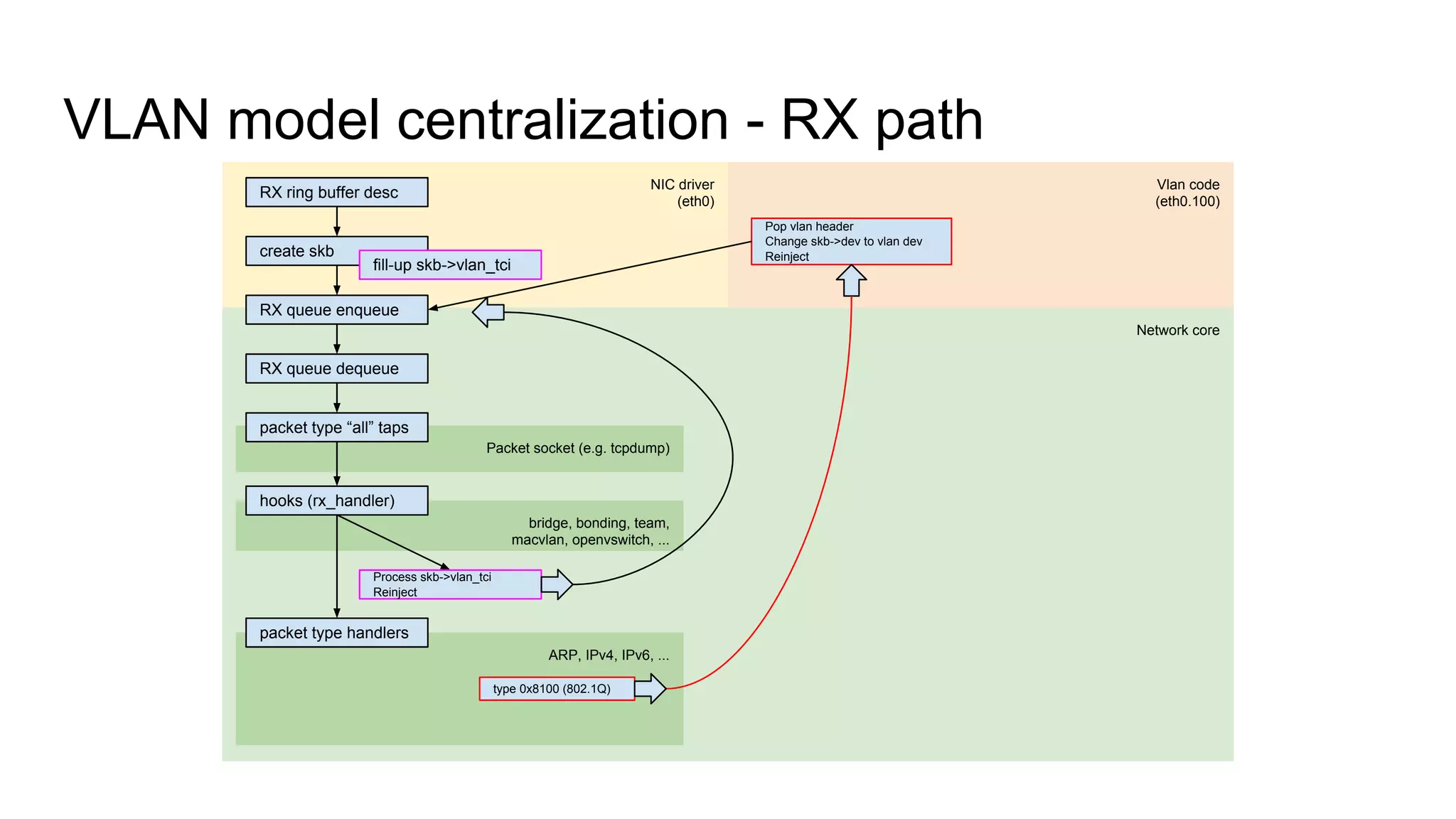
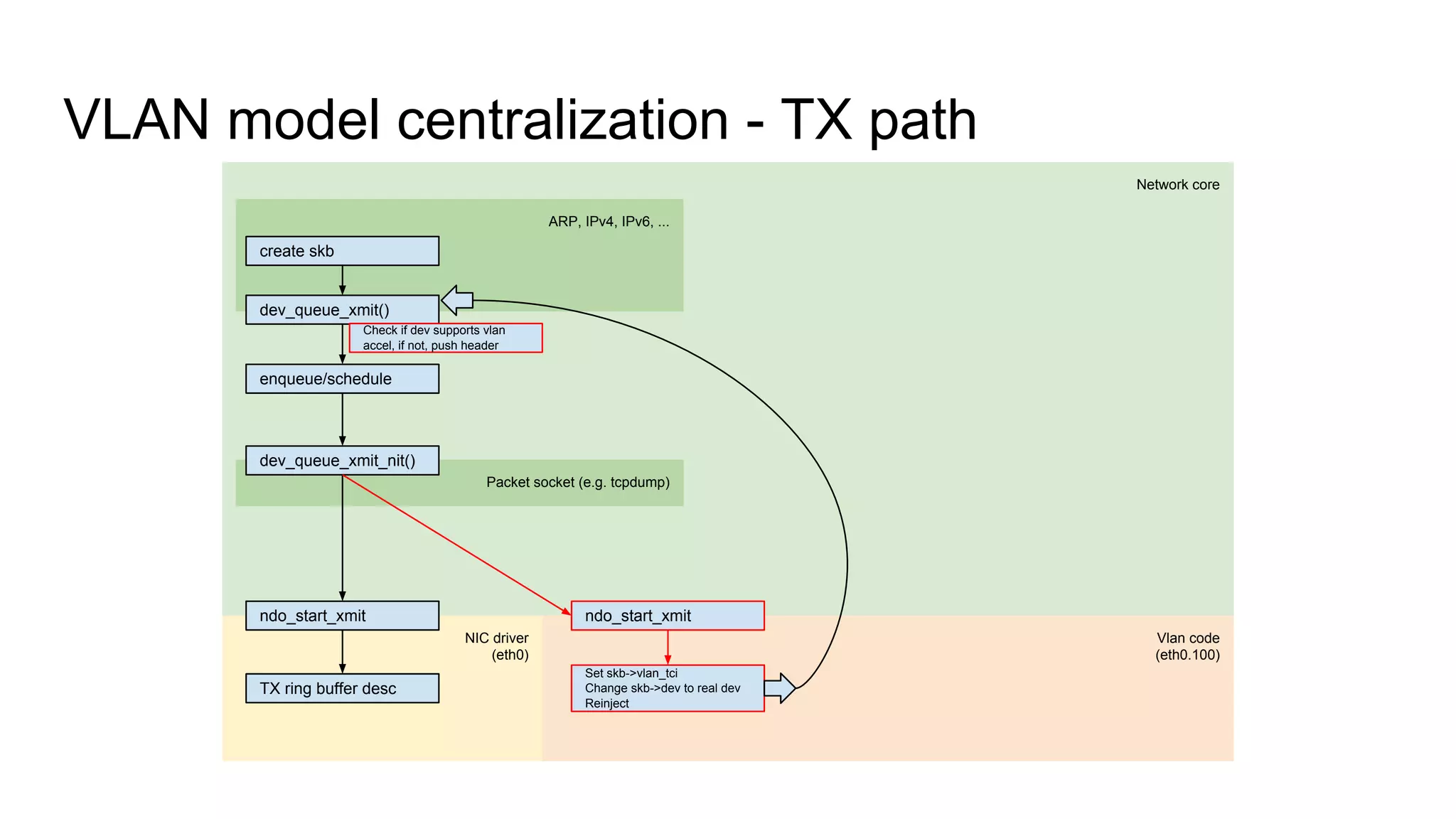
Discusses VLAN model centralization and the unification of RX paths for accelerated and non-accelerated handling.
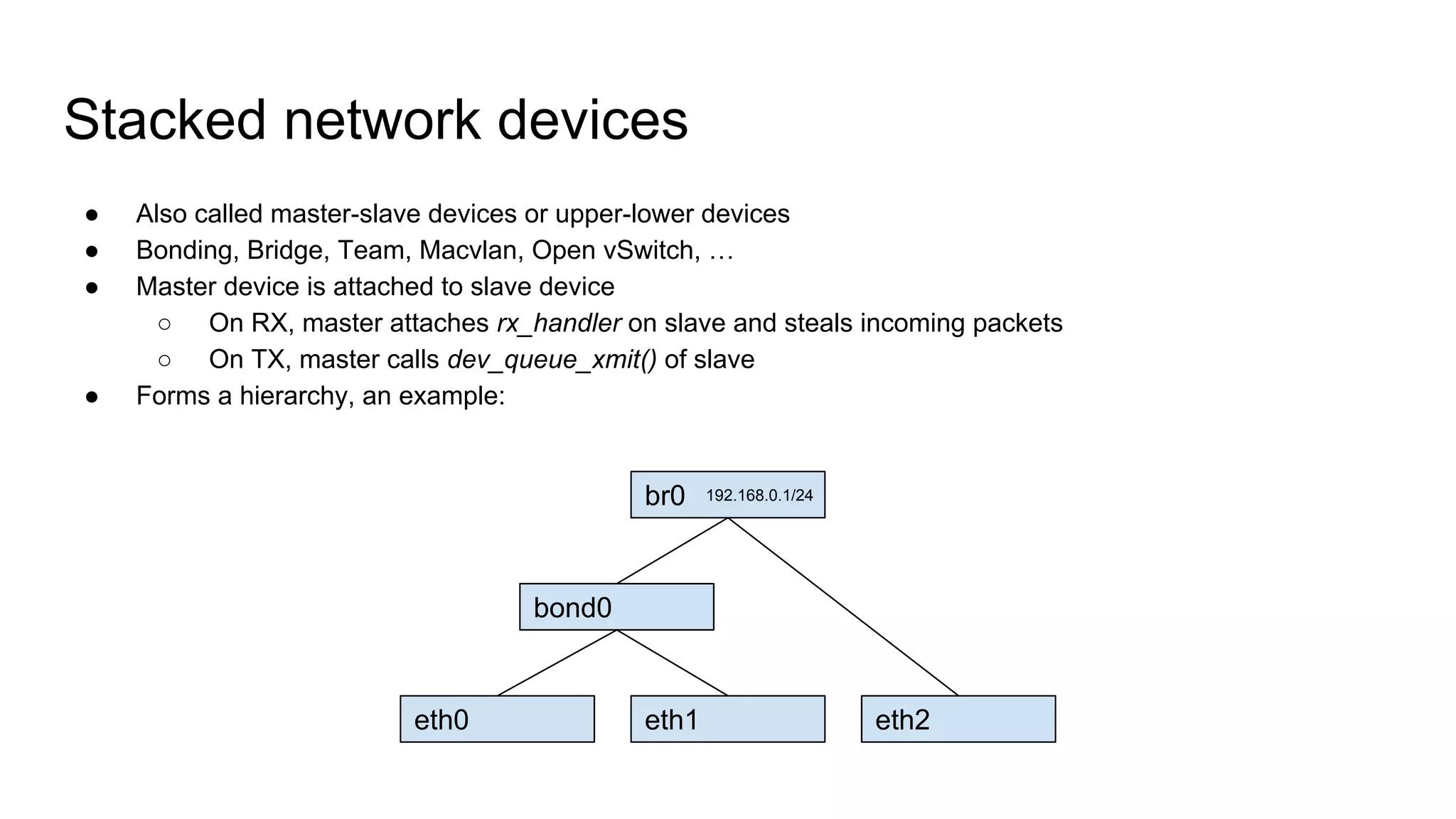
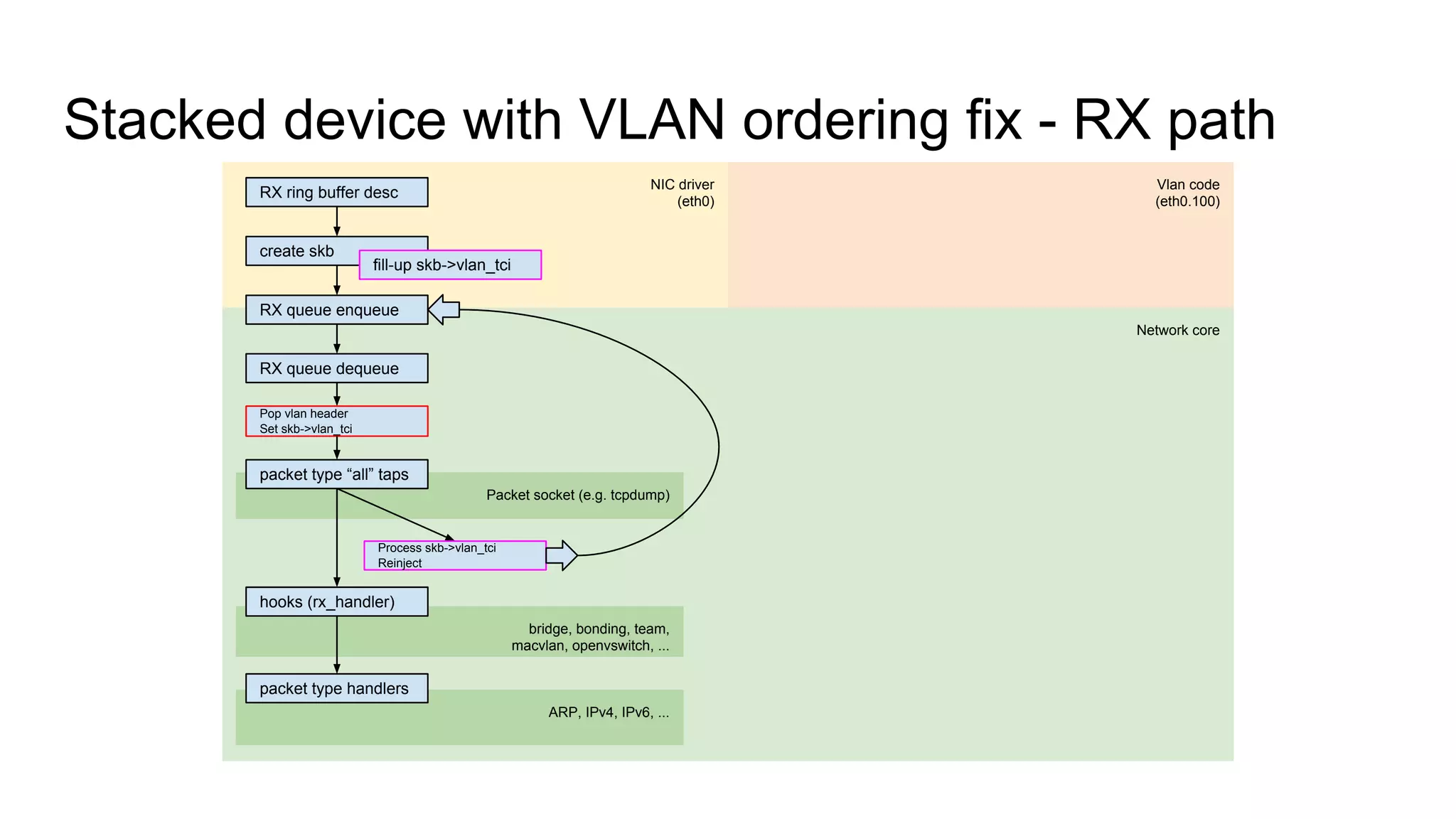
Describes stacked network devices, the challenges faced with VLAN filtering, and proposed solutions.
Summarizes the development journey of VLAN in Linux kernel over 14 years, highlighting commits and code changes.
Discusses alternative implementations of VLAN in Linux bridge, Open vSwitch, TC, and BPF.
Provides a closing opportunity for questions and offers a link to the presentation slides.






















































![CETH for XDP [Linux Meetup Santa Clara | July 2016]](https://cdn.slidesharecdn.com/ss_thumbnails/ceth5overview1-160801192921-thumbnail.jpg?width=640&height=640&fit=bounds)












































