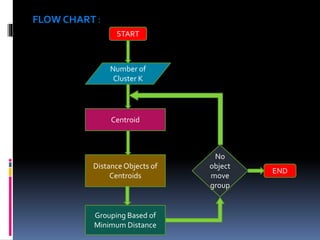
This document discusses K-means clustering, an unsupervised machine learning algorithm. It begins with an introduction to clustering and describes K-means clustering as assigning data points to K number of centroids, or cluster centers. The document outlines the K-means clustering procedure, which iteratively assigns data points to the closest centroid and recomputes centroids until centroids do not change. Advantages include faster computation than hierarchical clustering for large datasets, while disadvantages include difficulty selecting the optimal K value. Applications include wireless sensor networks, city planning, search engines, and email filtering.
















































![Clustering[306] [Read-Only].pdf](https://cdn.slidesharecdn.com/ss_thumbnails/clustering306read-only-230112103535-3fb144db-thumbnail.jpg?width=640&height=640&fit=bounds)





![Chapter#04[Part#01]K-Means Clusterig.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/chapter04part01k-meansclusterig-250525201708-2d369307-thumbnail.jpg?width=640&height=640&fit=bounds)



![[ML]-Unsupervised-learning_Unit2.ppt.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/ml-unsupervised-learningunit2-230916145038-acbd0397-thumbnail.jpg?width=640&height=640&fit=bounds)



























