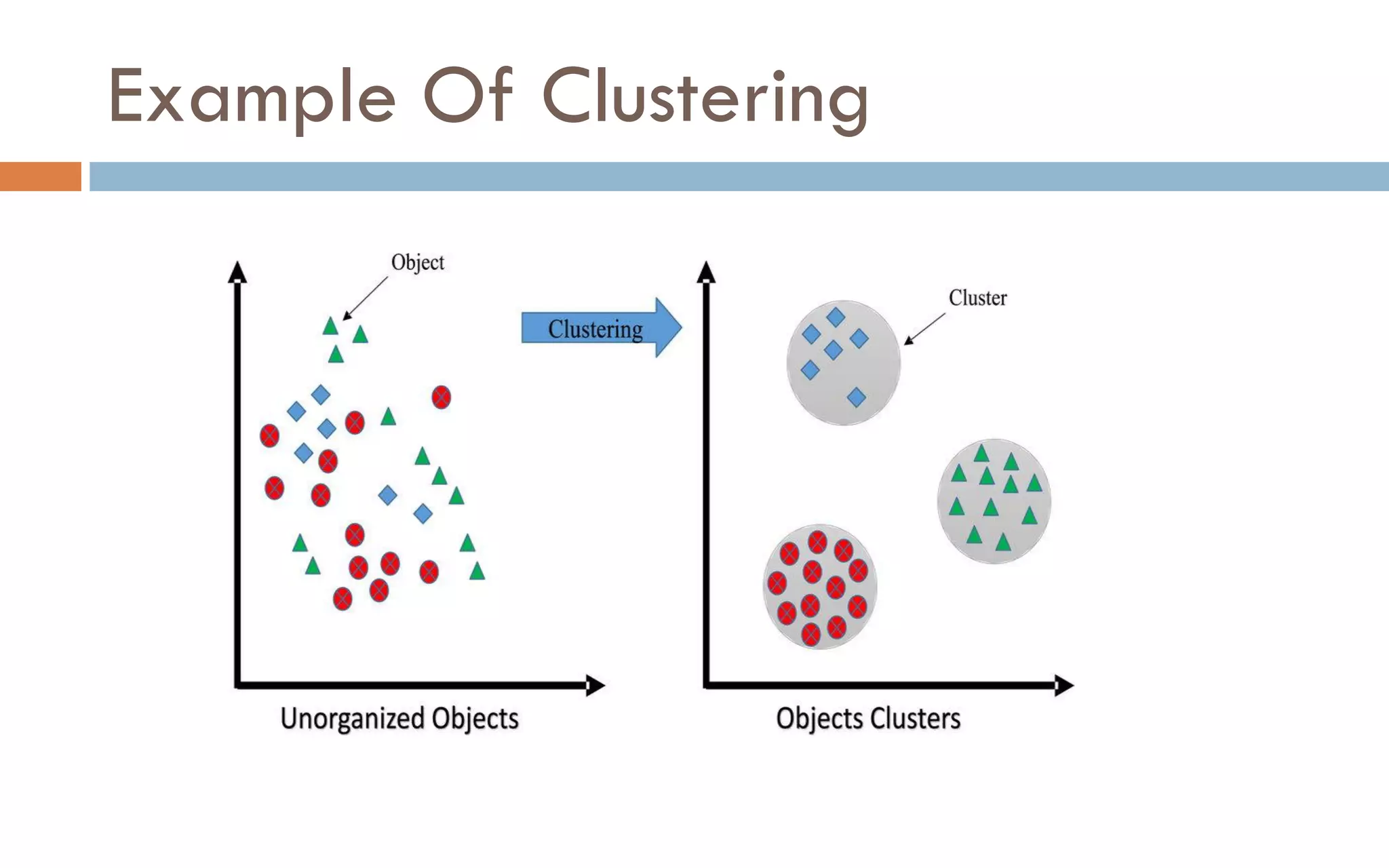
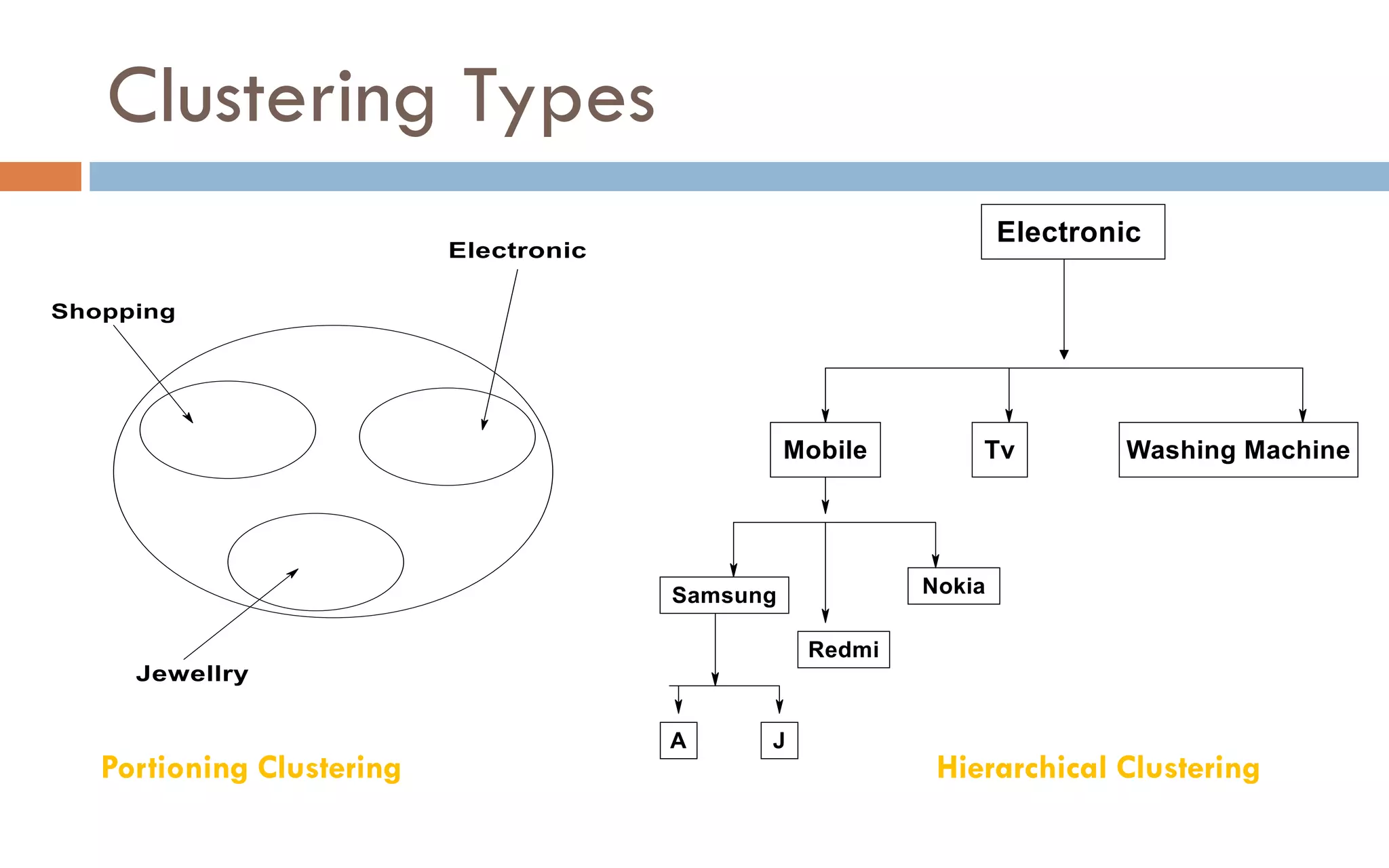
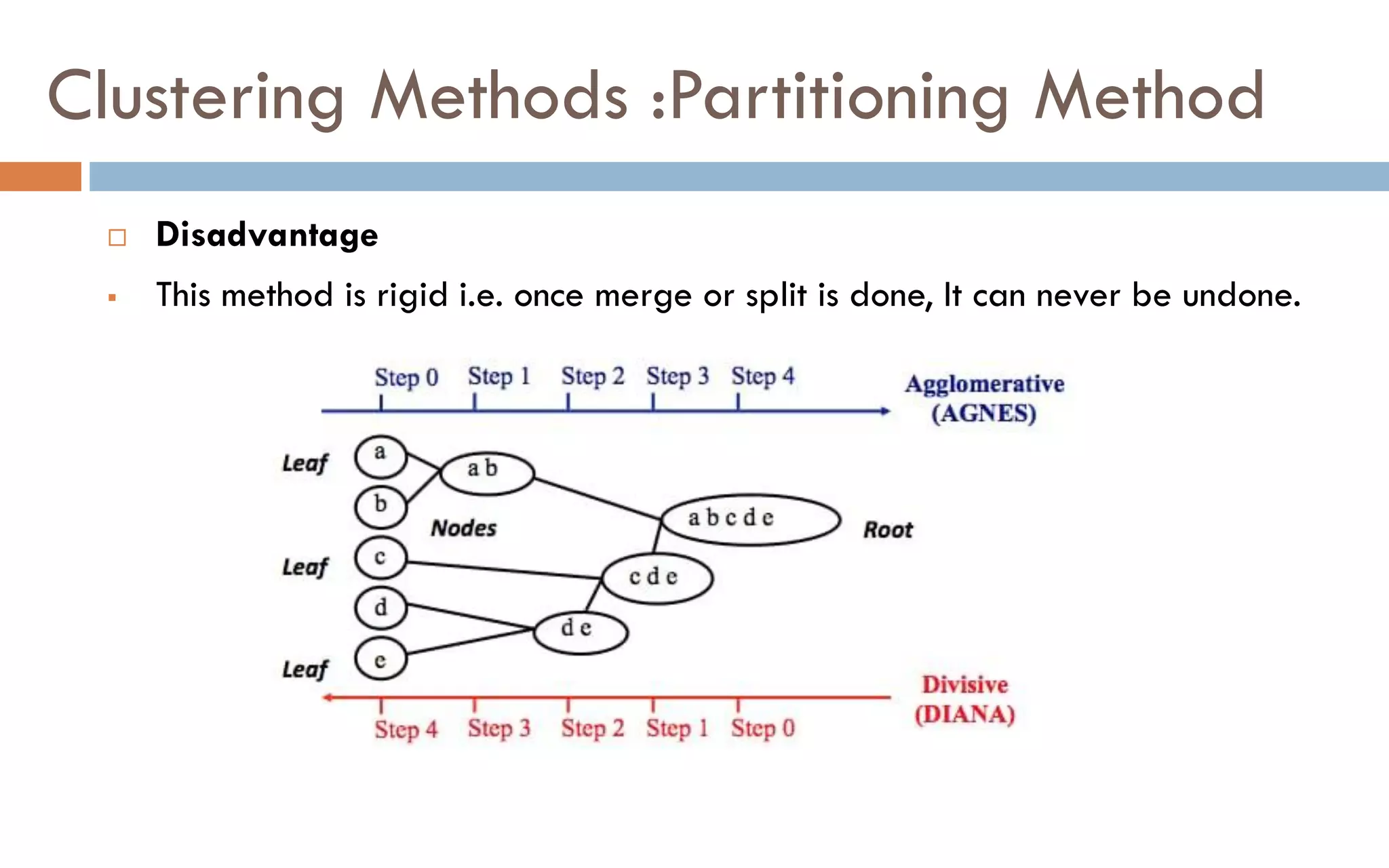
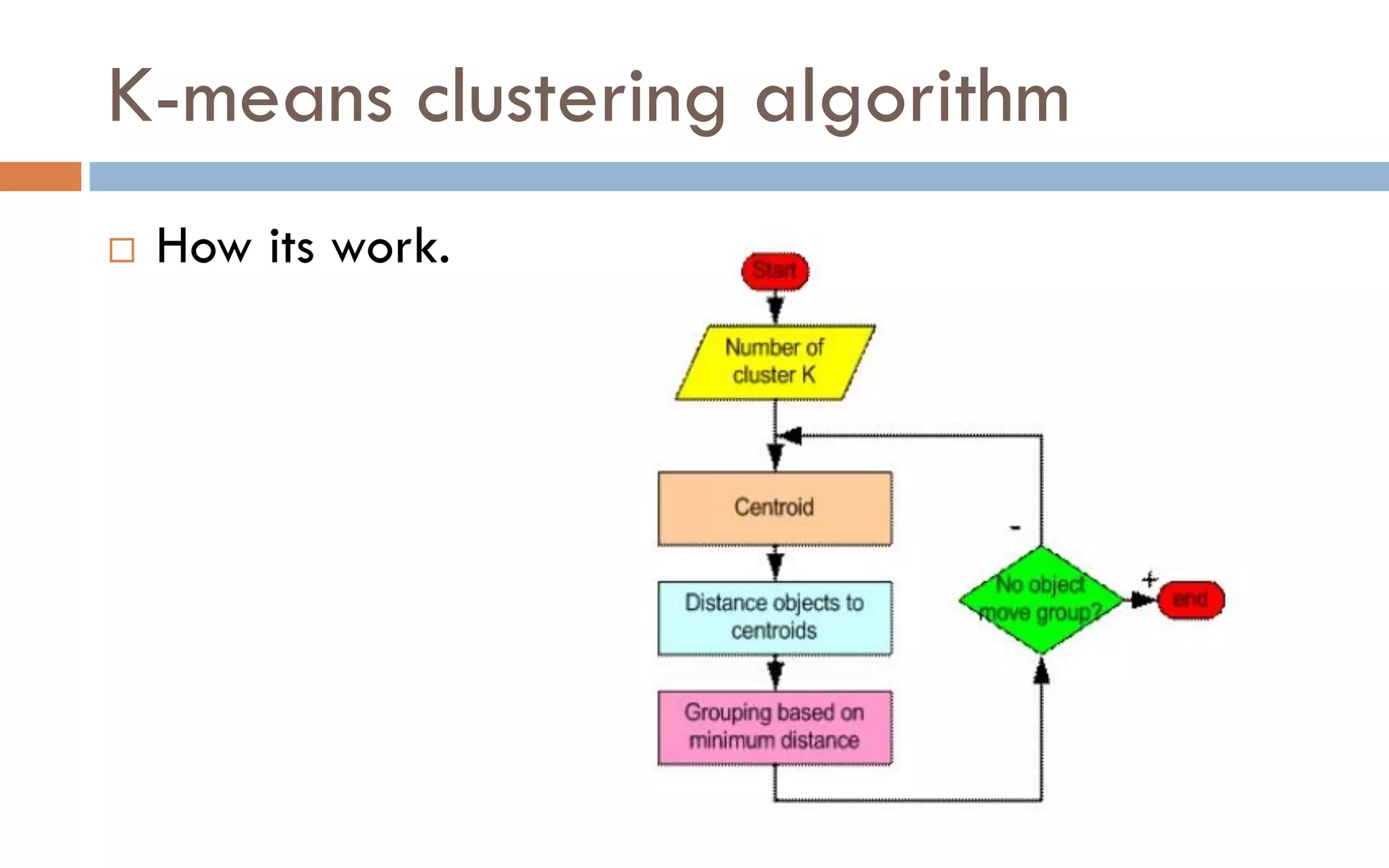
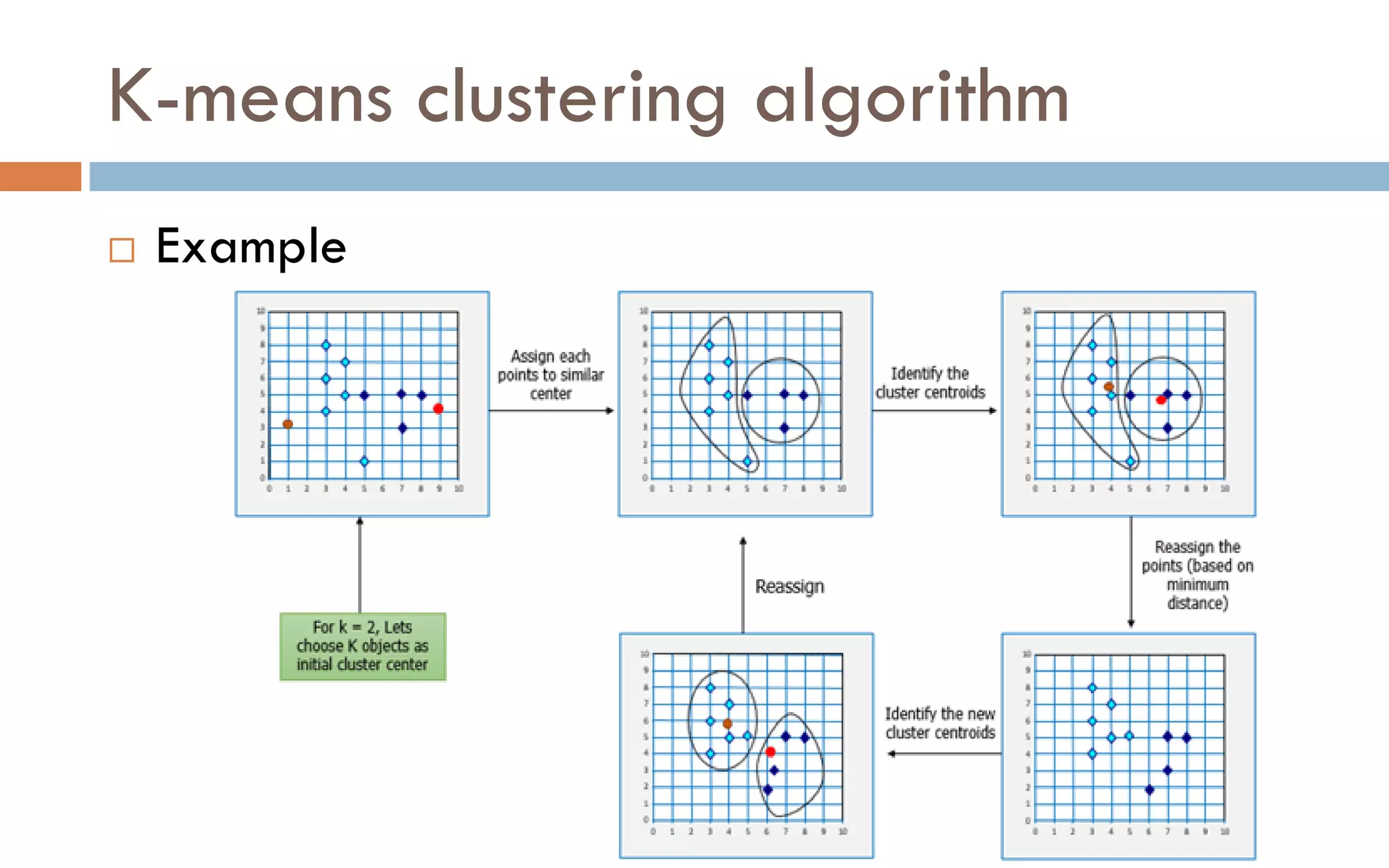
Clustering is an unsupervised machine learning technique that groups unlabeled data points into clusters based on similarities. It partitions data into meaningful subgroups without predefined labels. Common clustering algorithms include k-means, hierarchical, density-based, and grid-based methods. K-means clustering aims to partition data into k clusters where each data point belongs to the cluster with the nearest mean. It is sensitive to outliers but simple and fast.