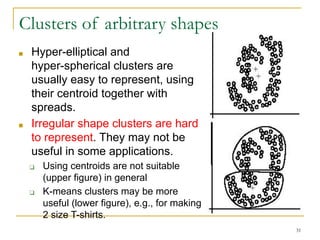
This document provides an overview of unsupervised learning and clustering algorithms. It discusses key concepts in unsupervised learning and clustering such as k-means clustering and hierarchical clustering. K-means clustering partitions data into k clusters by minimizing distances between data points and cluster centroids. Hierarchical clustering builds nested clusters by successively merging or dividing clusters based on distance measures. Representing clusters and evaluating clustering results are also covered.



























































































































![Chapter#04[Part#01]K-Means Clusterig.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/chapter04part01k-meansclusterig-250525201708-2d369307-thumbnail.jpg?width=640&height=640&fit=bounds)


























