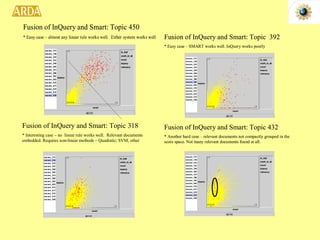
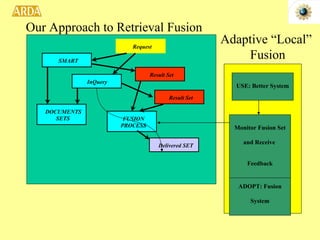
The document discusses two NSF-funded research projects on intelligence and security informatics:
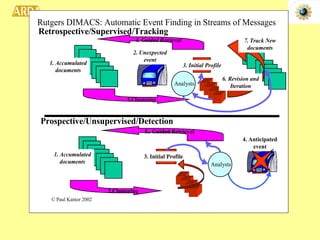
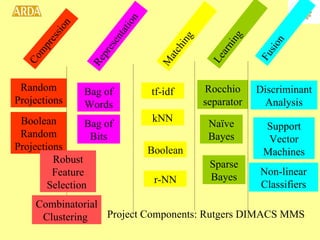
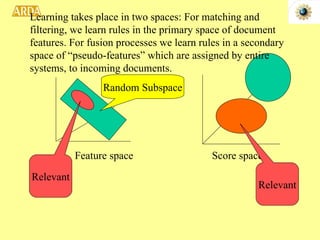
1. A project to filter and monitor message streams to detect "new events" and changes in topics or activity levels. It describes the technical challenges and components of automatic message processing.
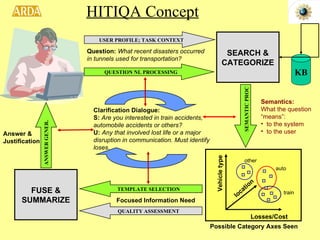
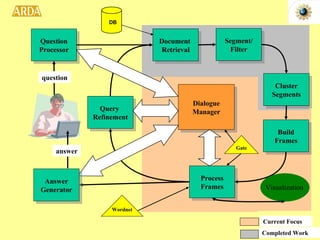
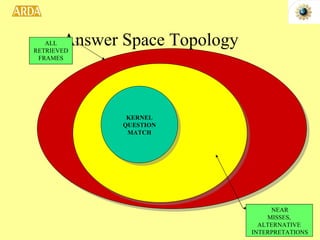
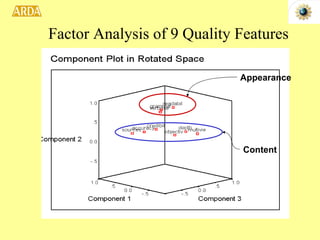
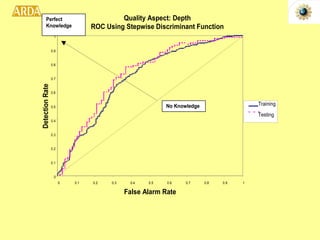
2. A project called HITIQA to develop high-quality interactive question answering. It describes the team members and key research issues like question semantics, human-computer dialogue, and information quality metrics.











































![[IJET-V1I6P17] Authors : Mrs.R.Kalpana, Mrs.P.Padmapriya](https://cdn.slidesharecdn.com/ss_thumbnails/ijet-v1i6p17-160110012712-thumbnail.jpg?width=640&height=640&fit=bounds)






































































