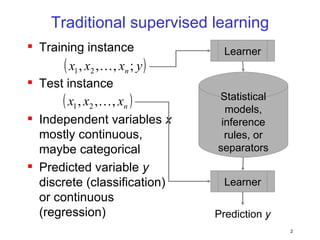
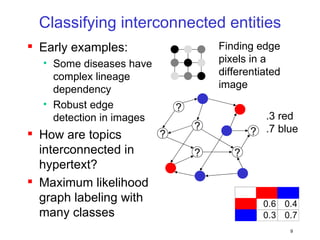
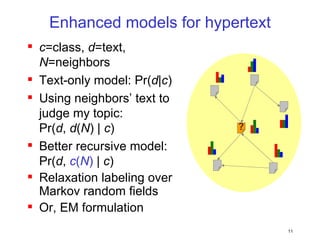
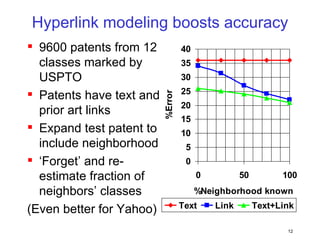
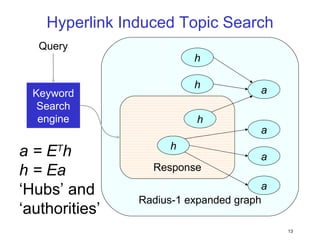
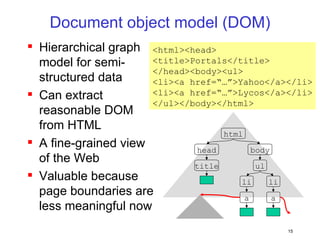
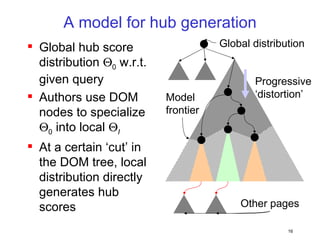
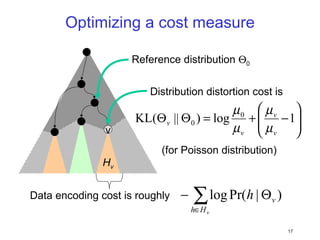
This document discusses machine learning challenges posed by hypertext and the web. It presents two examples of applying machine learning to hypertext documents: 1) semi-supervised learning to classify topics of hypertext documents using both text and hyperlinks, and 2) classifying interconnected entities by labeling graphs with many classes. The author proposes models that combine text and link information to better learn from hypertext documents and address issues like "topic drift".











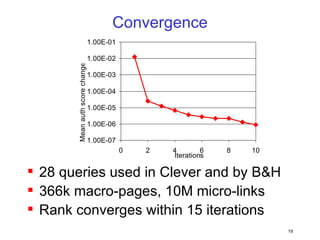
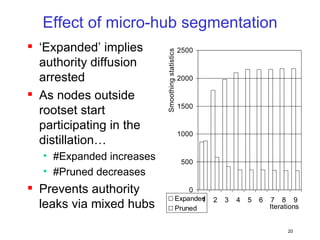
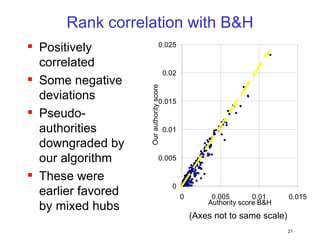









































![[CB16] Method of detecting vulnerability in WebApps using Machine Learning by...](https://cdn.slidesharecdn.com/ss_thumbnails/cb16takaesuen-161108075406-thumbnail.jpg?width=640&height=640&fit=bounds)




![[Tutorial] building machine learning models for predictive maintenance applic...](https://cdn.slidesharecdn.com/ss_thumbnails/tutorialbuildingmachinelearningmodelsforpredictivemaintenanceapplications-yanzhang-150820102412-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)









































