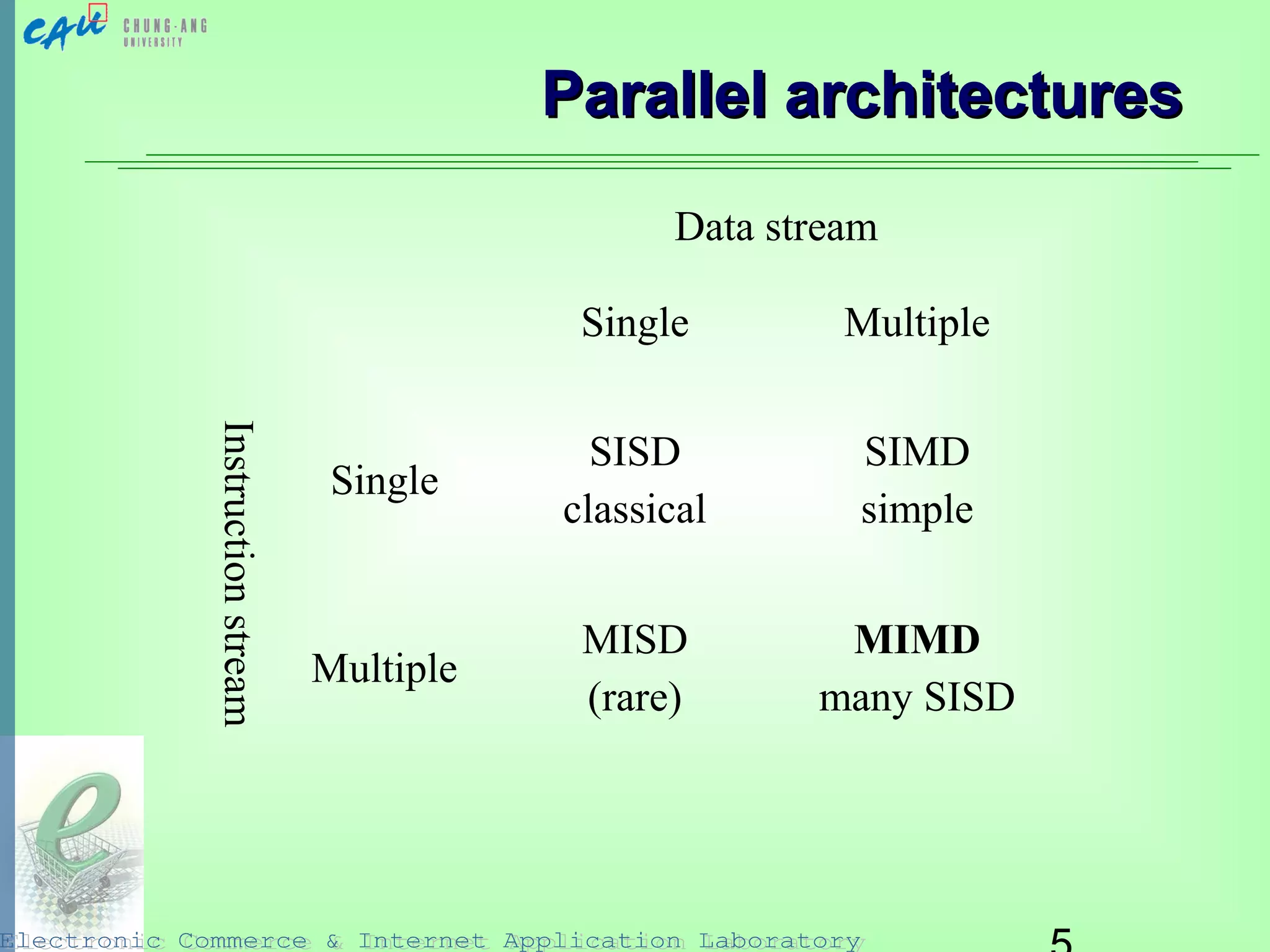
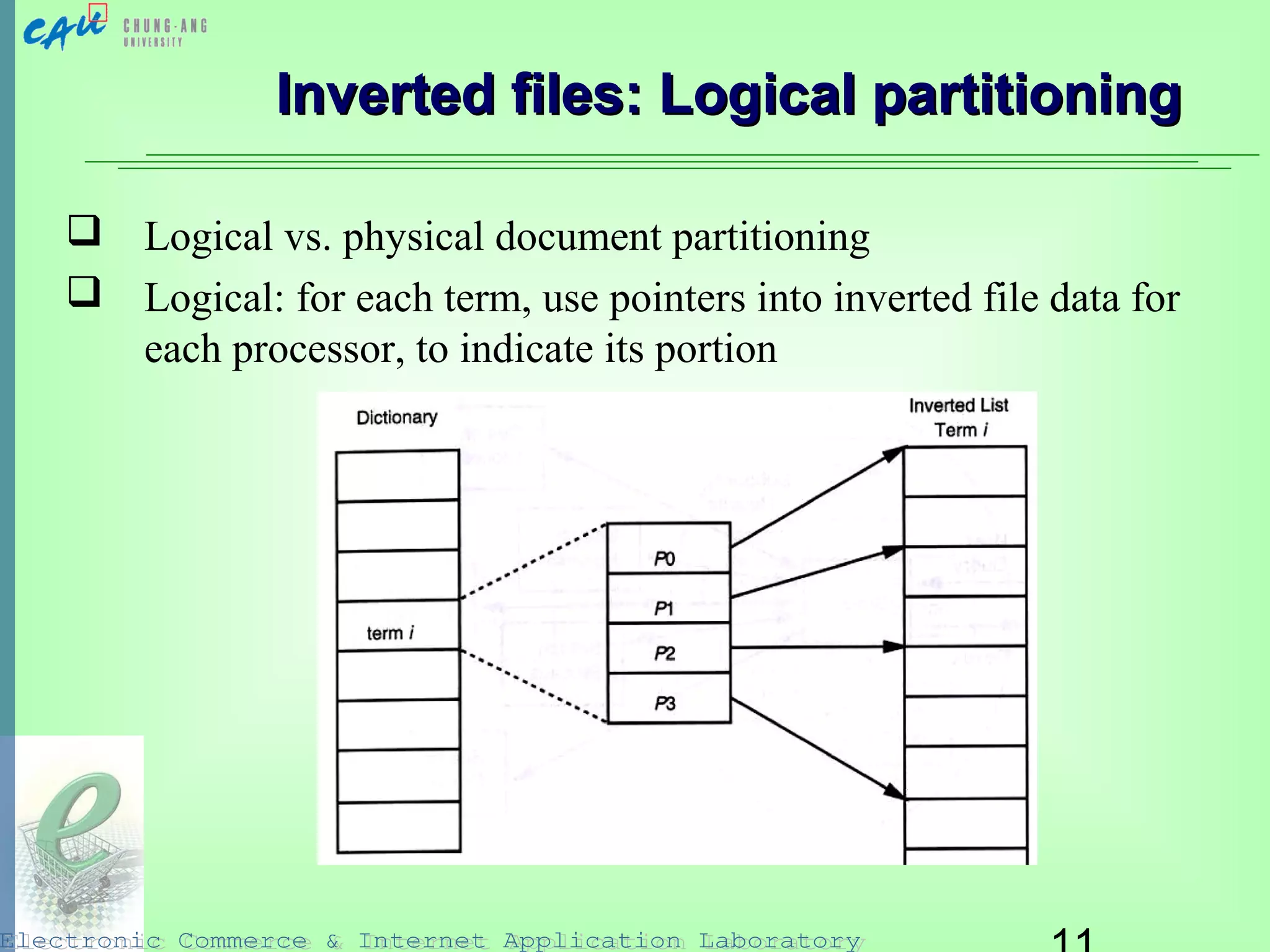
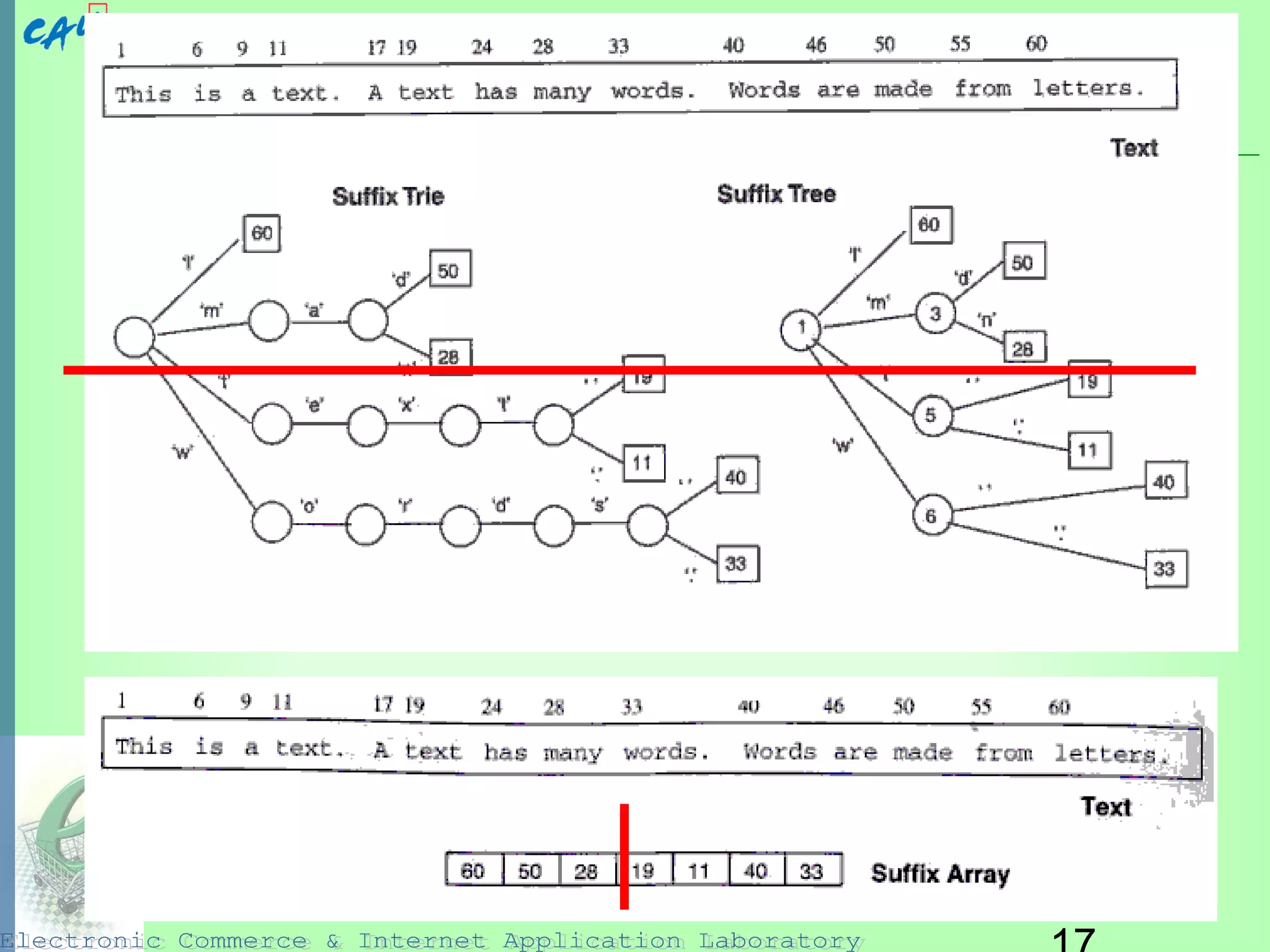
This document discusses parallel and distributed information retrieval. It describes how parallel architectures like MIMD can be used to accelerate search over very large document collections by distributing the work across multiple processors. Two main approaches to parallelism are covered: building new parallel algorithms or adapting existing techniques. Common ways to partition data for parallel indexing and search are discussed, including document partitioning and term partitioning. Specific data structures like inverted files, suffix arrays, and signature files are examined in terms of how they can be adapted for parallel and distributed retrieval architectures.