Download as PDF, PPTX

































![49Spark Streaming from Zinoviev Alexey
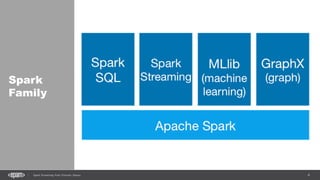
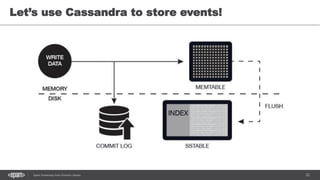
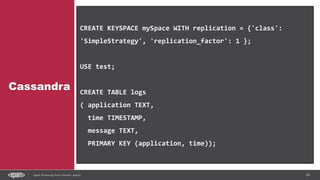
DStream
val conf = new SparkConf().setMaster("local[2]")
.setAppName("NetworkWordCount")
val ssc = new StreamingContext(conf, Seconds(1))
val lines = ssc.socketTextStream("localhost", 9999)
val words = lines.flatMap(_.split(" "))
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
wordCounts.print()
ssc.start()
ssc.awaitTermination()](https://image.slidesharecdn.com/sparkkafka-170405115804/85/Kafka-pours-and-Spark-resolves-49-320.jpg)
![50Spark Streaming from Zinoviev Alexey
DStream
val conf = new SparkConf().setMaster("local[2]")
.setAppName("NetworkWordCount")
val ssc = new StreamingContext(conf, Seconds(1))
val lines = ssc.socketTextStream("localhost", 9999)
val words = lines.flatMap(_.split(" "))
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
wordCounts.print()
ssc.start()
ssc.awaitTermination()](https://image.slidesharecdn.com/sparkkafka-170405115804/85/Kafka-pours-and-Spark-resolves-50-320.jpg)
![51Spark Streaming from Zinoviev Alexey
DStream
val conf = new SparkConf().setMaster("local[2]")
.setAppName("NetworkWordCount")
val ssc = new StreamingContext(conf, Seconds(1))
val lines = ssc.socketTextStream("localhost", 9999)
val words = lines.flatMap(_.split(" "))
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
wordCounts.print()
ssc.start()
ssc.awaitTermination()](https://image.slidesharecdn.com/sparkkafka-170405115804/85/Kafka-pours-and-Spark-resolves-51-320.jpg)
![52Spark Streaming from Zinoviev Alexey
DStream
val conf = new SparkConf().setMaster("local[2]")
.setAppName("NetworkWordCount")
val ssc = new StreamingContext(conf, Seconds(1))
val lines = ssc.socketTextStream("localhost", 9999)
val words = lines.flatMap(_.split(" "))
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
wordCounts.print()
ssc.start()
ssc.awaitTermination()](https://image.slidesharecdn.com/sparkkafka-170405115804/85/Kafka-pours-and-Spark-resolves-52-320.jpg)
![53Spark Streaming from Zinoviev Alexey
DStream
val conf = new SparkConf().setMaster("local[2]")
.setAppName("NetworkWordCount")
val ssc = new StreamingContext(conf, Seconds(1))
val lines = ssc.socketTextStream("localhost", 9999)
val words = lines.flatMap(_.split(" "))
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
wordCounts.print()
ssc.start()
ssc.awaitTermination()](https://image.slidesharecdn.com/sparkkafka-170405115804/85/Kafka-pours-and-Spark-resolves-53-320.jpg)






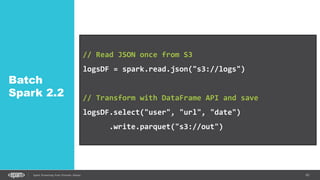

![63Spark Streaming from Zinoviev Alexey
WordCount
from
Socket
val lines = spark.readStream
.format("socket")
.option("host", "localhost")
.option("port", 9999)
.load()
val words = lines.as[String].flatMap(_.split(" "))
val wordCounts = words.groupBy("value").count()](https://image.slidesharecdn.com/sparkkafka-170405115804/85/Kafka-pours-and-Spark-resolves-63-320.jpg)
![64Spark Streaming from Zinoviev Alexey
WordCount
from
Socket
val lines = spark.readStream
.format("socket")
.option("host", "localhost")
.option("port", 9999)
.load()
val words = lines.as[String].flatMap(_.split(" "))
val wordCounts = words.groupBy("value").count()](https://image.slidesharecdn.com/sparkkafka-170405115804/85/Kafka-pours-and-Spark-resolves-64-320.jpg)
![65Spark Streaming from Zinoviev Alexey
WordCount
from
Socket
val lines = spark.readStream
.format("socket")
.option("host", "localhost")
.option("port", 9999)
.load()
val words = lines.as[String].flatMap(_.split(" "))
val wordCounts = words.groupBy("value").count()](https://image.slidesharecdn.com/sparkkafka-170405115804/85/Kafka-pours-and-Spark-resolves-65-320.jpg)
![66Spark Streaming from Zinoviev Alexey
WordCount
from
Socket
val lines = spark.readStream
.format("socket")
.option("host", "localhost")
.option("port", 9999)
.load()
val words = lines.as[String].flatMap(_.split(" "))
val wordCounts = words.groupBy("value").count()
Don’t forget
to start
Streaming](https://image.slidesharecdn.com/sparkkafka-170405115804/85/Kafka-pours-and-Spark-resolves-66-320.jpg)
![68Spark Streaming from Zinoviev Alexey
WordCount with Structured Streaming [Complete Mode]](https://image.slidesharecdn.com/sparkkafka-170405115804/85/Kafka-pours-and-Spark-resolves-68-320.jpg)








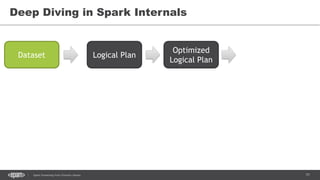
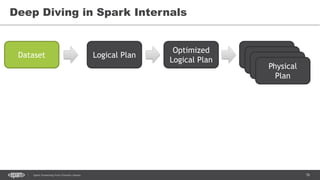

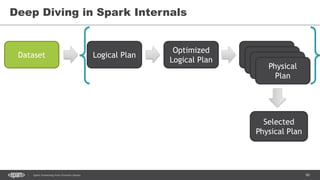


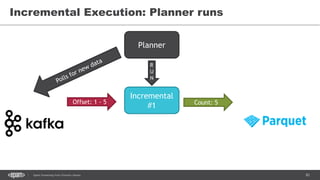
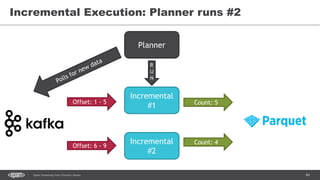
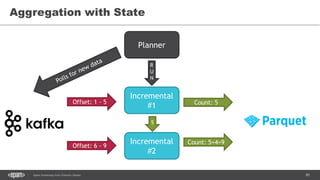
![86Spark Streaming from Zinoviev Alexey
DataSet.explain()
== Physical Plan ==
Project [avg(price)#43,carat#45]
+- SortMergeJoin [color#21], [color#47]
:- Sort [color#21 ASC], false, 0
: +- TungstenExchange hashpartitioning(color#21,200), None
: +- Project [avg(price)#43,color#21]
: +- TungstenAggregate(key=[cut#20,color#21], functions=[(avg(cast(price#25 as
bigint)),mode=Final,isDistinct=false)], output=[color#21,avg(price)#43])
: +- TungstenExchange hashpartitioning(cut#20,color#21,200), None
: +- TungstenAggregate(key=[cut#20,color#21],
functions=[(avg(cast(price#25 as bigint)),mode=Partial,isDistinct=false)],
output=[cut#20,color#21,sum#58,count#59L])
: +- Scan CsvRelation(-----)
+- Sort [color#47 ASC], false, 0
+- TungstenExchange hashpartitioning(color#47,200), None
+- ConvertToUnsafe
+- Scan CsvRelation(----)](https://image.slidesharecdn.com/sparkkafka-170405115804/85/Kafka-pours-and-Spark-resolves-86-320.jpg)




![91Spark Streaming from Zinoviev Alexey
There are two main modes and one in future
• append (default)
• complete
• update [in dreams]](https://image.slidesharecdn.com/sparkkafka-170405115804/85/Kafka-pours-and-Spark-resolves-91-320.jpg)
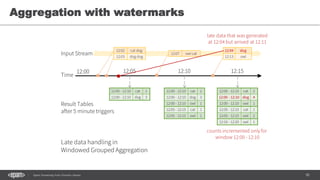

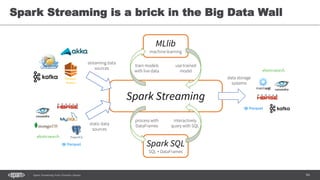





![104Spark Streaming from Zinoviev Alexey
Console
Foreach
Sink
import org.apache.spark.sql.ForeachWriter
val customWriter = new ForeachWriter[String] {
override def open(partitionId: Long, version: Long) = true
override def process(value: String) = println(value)
override def close(errorOrNull: Throwable) = {}
}
stream.writeStream
.queryName(“ForeachOnConsole")
.foreach(customWriter)
.start](https://image.slidesharecdn.com/sparkkafka-170405115804/85/Kafka-pours-and-Spark-resolves-104-320.jpg)










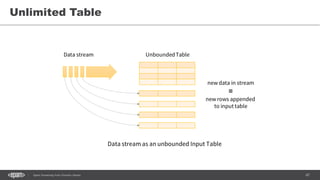
The document discusses the integration of Apache Spark and Kafka for real-time data processing, highlighting key concepts such as Spark Streaming and DStreams. It covers the architecture of Kafka as a distributed messaging system and provides practical examples of using Spark with Kafka, including word count operations and structured streaming. Additionally, it mentions considerations for performance and capabilities of Spark Streaming, leading to the conclusion that a scalable, fault-tolerant real-time pipeline is feasible with these technologies.














































































![[DSC Europe 25] Slobodan Dolinic - Smart and Intelligent Green Region.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/0bribinjsp6ghwtvsvor-2-sigre-slobodan-dolinic-260115093812-c9c10e90-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Ivica Milaric - The Future of Gaming and AI Tools.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/tijgzsmgse2kj2y5pzzp-5-ivica-milaric-the-future-of-gaming-x-ai-tools-260114111931-87c2b3ac-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Srba Markovic - From Pilot to Production: Overcoming AI Deplo...](https://cdn.slidesharecdn.com/ss_thumbnails/yjjmrtytmwbalxlba7px-4-srba-markovic-from-pilot-to-production-overcoming-ai-deployment-blockers-with-260114111931-4a892d44-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Mijat Kustudic - Building Financial Intelligence with AI Agen...](https://cdn.slidesharecdn.com/ss_thumbnails/38y2lb5lse6wstegtvas-3-mijat-kustudic-building-financial-intelligence-with-ai-agents-260114111931-1a4783ce-thumbnail.jpg?width=640&height=640&fit=bounds)
