Download as PDF, PPTX









![Lets get ready to write the data into
Elasticsearch
def setupEsOnSparkContext(sc: SparkContext) = {
val jobConf = new JobConf(sc.hadoopConfiguration)
jobConf.set("mapred.output.format.class",
"org.elasticsearch.hadoop.mr.EsOutputFormat")
jobConf.setOutputCommitter(classOf[FileOutputCommitter])
jobConf.set(ConfigurationOptions.ES_RESOURCE_WRITE,
“twitter/tweet”)
FileOutputFormat.setOutputPath(jobConf, new Path("-"))
jobconf
}](https://image.slidesharecdn.com/umdversion-sparkwithelasticsearch-141023044029-conversion-gate02/85/Spark-with-Elasticsearch-umd-version-2014-11-320.jpg)



![Elastic Search now has
Spark SQL!
case class tweetCS(docid: String, message: String,
hashTags: String, location: Opiton[String])](https://image.slidesharecdn.com/umdversion-sparkwithelasticsearch-141023044029-conversion-gate02/85/Spark-with-Elasticsearch-umd-version-2014-15-320.jpg)



![Now let’s find the hash tags :)
// Set our query
jobConf.set("es.query", query)
// Create an RDD of the tweets
val currentTweets = sc.hadoopRDD(jobConf,
classOf[EsInputFormat[Object, MapWritable]],
classOf[Object], classOf[MapWritable])
// Convert to a format we can work with
val tweets = currentTweets.map{ case (key, value) =>
SharedIndex.mapWritableToInput(value) }
// Extract the hashtags
val hashTags = tweets.flatMap{t =>
t.getOrElse("hashTags", "").split(" ")
}](https://image.slidesharecdn.com/umdversion-sparkwithelasticsearch-141023044029-conversion-gate02/85/Spark-with-Elasticsearch-umd-version-2014-19-320.jpg)
![and extract the top hashtags
object WordCountOrdering extends Ordering[(String, Int)]{
def compare(a: (String, Int), b: (String, Int)) = {
b._2 compare a._2
}
}
val ht = hashtags.map(x => (x, 1)).reduceByKey((x,y) => x+y)
val topTags = ht.takeOrdered(40)(WordCountOrdering)](https://image.slidesharecdn.com/umdversion-sparkwithelasticsearch-141023044029-conversion-gate02/85/Spark-with-Elasticsearch-umd-version-2014-20-320.jpg)



![So what does that give us?
Spark sets the filename to part-[part #]
If we have same partitioner we write
directly
Partition 1
Partition 2
Partition 3
ES Node 1
Partition {1,2}
ES Node 2
Partition {3}](https://image.slidesharecdn.com/umdversion-sparkwithelasticsearch-141023044029-conversion-gate02/85/Spark-with-Elasticsearch-umd-version-2014-25-320.jpg)






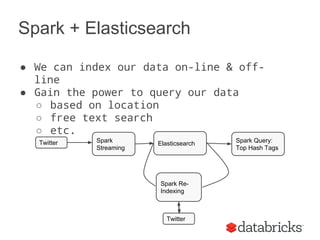
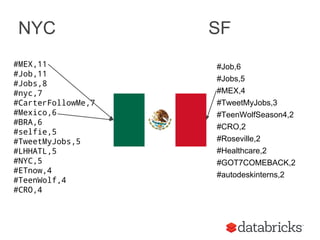
Holden Karau gave a talk on using Apache Spark and Elasticsearch. The talk covered indexing data from Spark to Elasticsearch both online using Spark Streaming and offline. It showed how to customize the Elasticsearch connector to write indexed data directly to shards based on partitions to reduce network overhead. It also demonstrated querying Elasticsearch from Spark, extracting top tags from tweets, and reindexing data from Twitter to Elasticsearch.



































































