Downloaded 108 times














![2
01
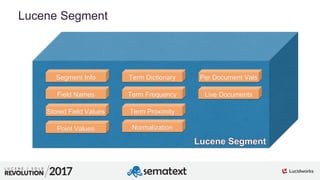
Atomic Updates
$ curl -XPOST -H 'Content-Type: application/json'
'http://localhost:8983/solr/lr/update?commit=true' --data-binary '[
{
"id" : "3",
"tags" : {
"add" : [ "solr" ]
}
}
]'
retrieve document
{
"id" : 3,
"tags" : [ "lucene" ],
"awesome" : true
}](https://image.slidesharecdn.com/sematext-lucenerevolution2017-optimizeisnotbadforyou-170920101032/85/Solr-Search-Engine-Optimize-Is-Not-Bad-for-You-29-320.jpg)
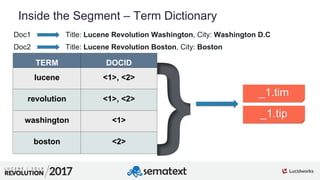
![3
01
Atomic Updates
$ curl -XPOST -H 'Content-Type: application/json'
'http://localhost:8983/solr/lr/update?commit=true' --data-binary '[
{
"id" : "3",
"tags" : {
"add" : [ "solr" ]
}
}
]'
{
"id" : 3,
"tags" : [ "lucene", "solr" ],
"awesome" : true
}
apply changes](https://image.slidesharecdn.com/sematext-lucenerevolution2017-optimizeisnotbadforyou-170920101032/85/Solr-Search-Engine-Optimize-Is-Not-Bad-for-You-30-320.jpg)
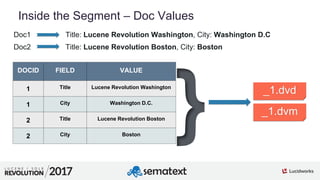
![3
01
Atomic Updates
$ curl -XPOST -H 'Content-Type: application/json'
'http://localhost:8983/solr/lr/update?commit=true' --data-binary '[
{
"id" : "3",
"tags" : {
"add" : [ "solr" ]
}
}
]'
{
"id" : 3,
"tags" : [ "lucene", "solr" ],
"awesome" : true
}
delete old document](https://image.slidesharecdn.com/sematext-lucenerevolution2017-optimizeisnotbadforyou-170920101032/85/Solr-Search-Engine-Optimize-Is-Not-Bad-for-You-31-320.jpg)
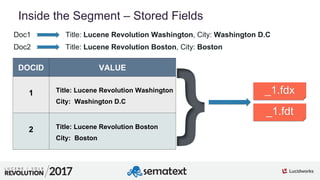
![3
01
Atomic Updates
$ curl -XPOST -H 'Content-Type: application/json'
'http://localhost:8983/solr/lr/update?commit=true' --data-binary '[
{
"id" : "3",
"tags" : {
"add" : [ "solr" ]
}
}
]'
{
"id" : 3,
"tags" : [ "lucene", "solr" ],
"awesome" : true
}](https://image.slidesharecdn.com/sematext-lucenerevolution2017-optimizeisnotbadforyou-170920101032/85/Solr-Search-Engine-Optimize-Is-Not-Bad-for-You-32-320.jpg)
![3
01
Atomic Updates – In Place
Works on top of numeric, doc values based fields
Fields need to be not indexed and not stored
Doesn’t require delete/index
Support only inc and set modifers
$ curl -XPOST -H 'Content-Type: application/json'
'http://localhost:8983/solr/lr/update?commit=true' --data-binary '[
{
"id" : "3",
"views" : {
"inc" : 100
}
}
]'](https://image.slidesharecdn.com/sematext-lucenerevolution2017-optimizeisnotbadforyou-170920101032/85/Solr-Search-Engine-Optimize-Is-Not-Bad-for-You-33-320.jpg)
![3
01
Atomic Updates – In Place
$ curl -XPOST -H 'Content-Type: application/json'
'http://localhost:8983/solr/lr/update?commit=true' --data-binary '[
{
"id" : "3",
"views" : {
"inc" : 100
}
}
]'
retrieve document
{
"id" : 3,
"tags" : [ "lucene", "solr" ],
"awesome" : true
}](https://image.slidesharecdn.com/sematext-lucenerevolution2017-optimizeisnotbadforyou-170920101032/85/Solr-Search-Engine-Optimize-Is-Not-Bad-for-You-34-320.jpg)
![3
01
Atomic Updates – In Place
$ curl -XPOST -H 'Content-Type: application/json'
'http://localhost:8983/solr/lr/update?commit=true' --data-binary '[
{
"id" : "3",
"views" : {
"inc" : 100
}
}
]'
{
"id" : 3,
"tags" : [ "lucene", "solr" ],
"awesome" : true,
"views" : 100
}
apply changes](https://image.slidesharecdn.com/sematext-lucenerevolution2017-optimizeisnotbadforyou-170920101032/85/Solr-Search-Engine-Optimize-Is-Not-Bad-for-You-35-320.jpg)
![3
01
Atomic Updates – In Place
$ curl -XPOST -H 'Content-Type: application/json'
'http://localhost:8983/solr/lr/update?commit=true' --data-binary '[
{
"id" : "3",
"views" : {
"inc" : 100
}
}
]'
{
"id" : 3,
"tags" : [ "lucene", "solr" ],
"awesome" : true,
"views" : 100
}
update doc values](https://image.slidesharecdn.com/sematext-lucenerevolution2017-optimizeisnotbadforyou-170920101032/85/Solr-Search-Engine-Optimize-Is-Not-Bad-for-You-36-320.jpg)



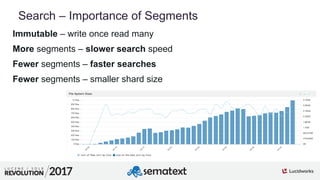





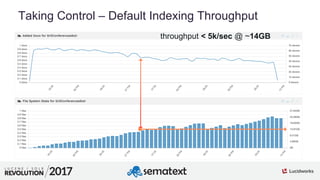


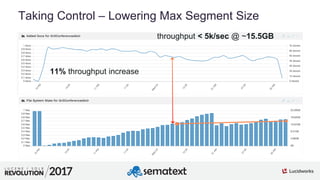


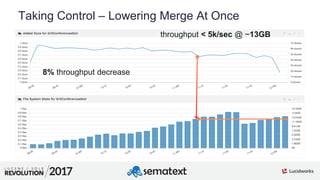



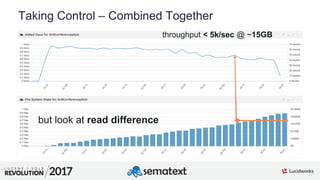





















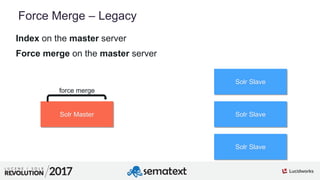
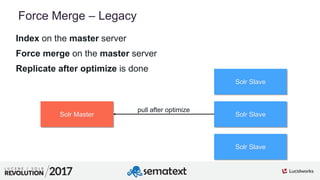



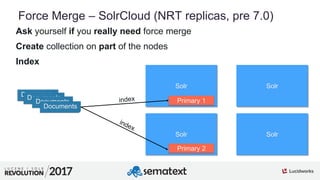
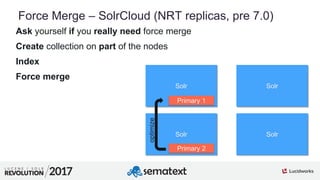







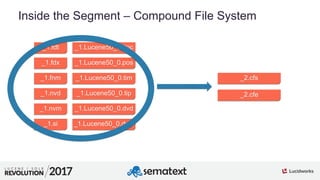
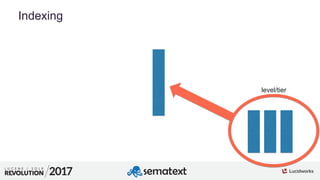
The document provides an in-depth analysis of segment management and merging in Solr, discussing aspects such as segment creation, modification, merging techniques, and performance implications. It explains the significance of immutable segments for search efficiency while also presenting various configuration options for controlling the merging process. Additionally, it includes technical examples of atomic updates and merge policies to optimize indexing and search performance.





























































































