Download as PDF, PPTX











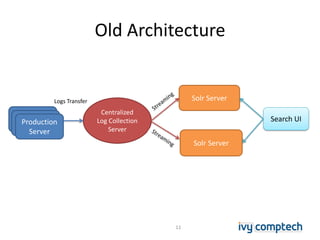
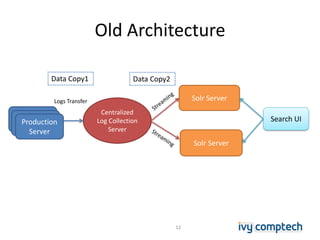
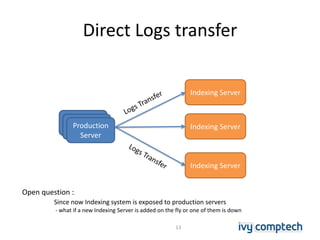
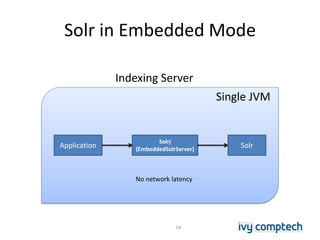

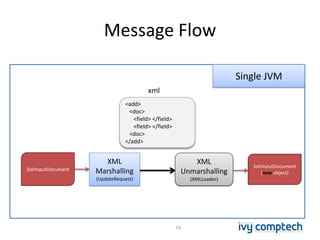
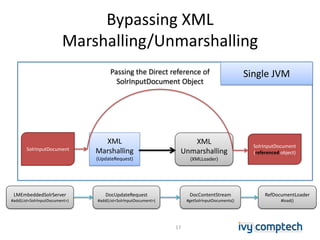

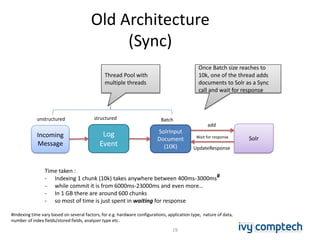
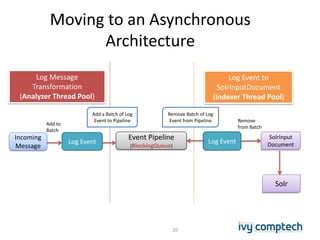

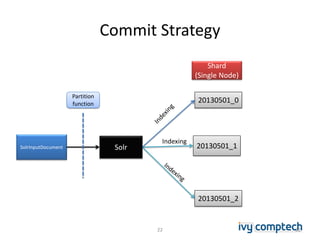
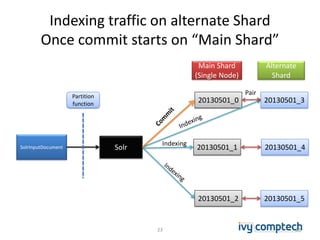




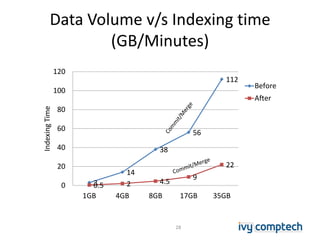

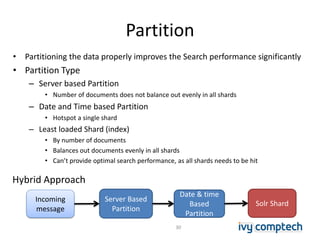
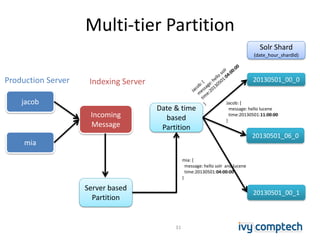

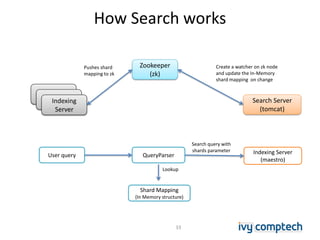
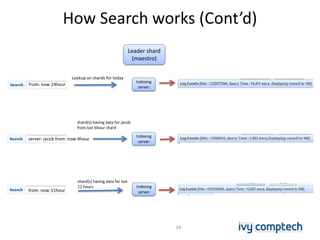

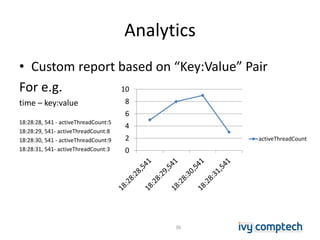

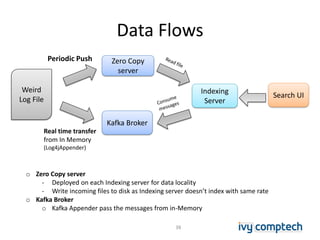
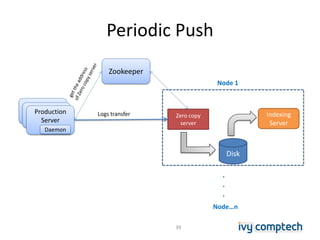
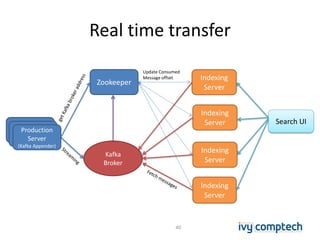



The document discusses building a near real-time log search engine and analytics using Solr, focusing on challenges like handling terabytes of unstructured logs and ensuring high indexing performance. It outlines improvements such as using an embedded Solr instance, asynchronous processing, and efficient commit strategies to optimize search and indexing. Additionally, it emphasizes lessons learned on scaling and performance tuning in distributed environments.























































































