

















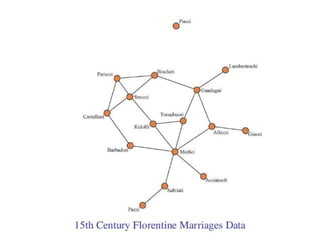

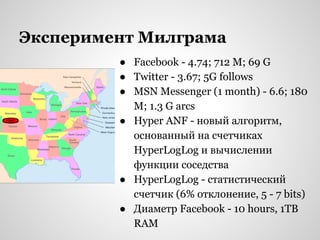










Докладчик Алексей Зиновьев делится опытом участия в almada-2013, обсуждая важность теории графов и big data в транспортных системах и управлении данными. Он выделяет этические аспекты использования персональной информации и возможности, которые открывает применение больших данных в разных областях. Также представлено несколько научных тем и алгоритмов, включая их приложения и значимость в современных исследованиях.















































